KI-System MinD-Vis dekodiert Bilder aus MRT-Aufnahmen

Ein neues KI-System rekonstruiert Bilder aus MRT-Daten um zwei Drittel genauer als ältere Systeme. Möglich ist das durch mehr Daten und Diffusion-Modelle.
Können KI-Modelle Gedanken rekonstruieren? Experimente mit großen Sprachmodellen etwa von Metas Forschungsgruppe um Jean-Remi King versuchen, Wörter oder Sätze aus MRT-Daten mit Sprachmodellen abzuleiten.
Kürzlich zeigte eine Forschungsgruppe ein KI-System, das die MRT-Daten einer Person, die ein Video anschaut, in Text, der die Ereignisse in Teilen beschreibt, umwandelt. In einem weiteren Experiment wollen Forschende Inhalte von Affen-Neuronen visualisieren.
Diese Technologien könnten einmal zu fortschrittlichen Interfaces führen, mit denen etwa Menschen mit Behinderung besser mit ihrer Umgebung kommunizieren oder einen Computer steuern können.
Eine neue Studie setzt jetzt auf Diffusion-Modelle, um aus menschlichen MRT-Daten Bilder zu rekonstruieren. Diffusion-Modelle stecken auch in fortschrittlichen Bild-KI-Systemen wie DALL-E 2 oder Stable Diffusion. Sie können aus Bildrauschen Bilder herausarbeiten.
MinD-Vis setzt auf Diffusion und 340 Stunden MRT-Aufnahmen
Forschende der National University of Singapore, der Chinese University of Hongkong und der Stanford University zeigen "Sparse Masked Brain Modeling with Double-Conditioned Latent Diffusion Model for Human Vision Decoding" - kurz MinD-Vis.
Ziel der Arbeit ist ein Diffusion-basiertes KI-Modell, das visuelle Stimuli von Gehirnaufnahmen dekodieren und so ein Fundament für die Verknüpfung von menschlichem und maschinellem Sehen legen kann.
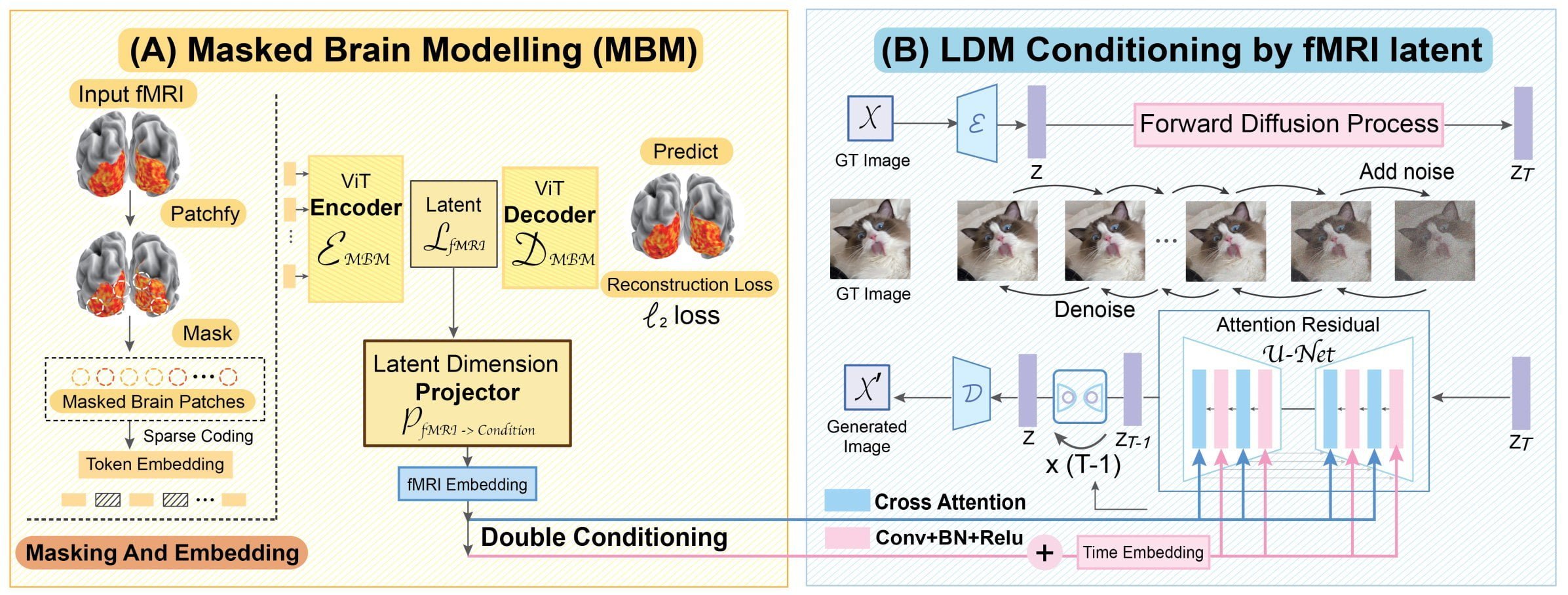
Zuerst lernt das KI-System per selbst-überwachtem Lernen eine effektive Repräsentation der MRT-Daten. Embeddings dieser Daten dienen dann als Kondition für die Bild-Generierung des Diffusion-Modells.
Für das Training setzt das Team auf Daten des "Human Connectome Project" und des "Generic Object Decoding Dataset". Insgesamt umfassen die Trainingsdaten so 136.000 MRT-Segmente von 340 Stunden MRT-Aufnahmen, der bisher größte Datensatz für ein Gehirnlese-KI-System.
MinD-Vis erfasst semantische Details und Bildeigenschaften
Während der erste Datensatz ausschließlich aus MRT-Daten besteht, umfasst der zweite 1.250 verschiedene Bilder aus 200 Klassen. 50 der Bilder hielt das Team für Tests zurück.
Für die weitere Validierung ihres Ansatzes setzten die Forschenden zudem auf das "Brain, Object, Landscape Dataset", das 5.254 MRT-Aufnahmen plus gesehene Bilder umfasst.
Laut der Veröffentlichung hängt MinD-Vis ältere Modelle deutlich ab: In der Erfassung semantischer Inhalte ist das System 66 Prozent und in der Qualität der generierten Bilder 41 Prozent besser.
Am Ende ist das System damit jedoch noch immer weit davon entfernt, Gedanken zuverlässig zu lesen: Trotz der Verbesserung liegt die Genauigkeit bei der Erfassung der semantischen Inhalte im Test bei nur 23,9 Prozent.

Die Qualität der rekonstruierten Bilder schwanke zudem zwischen verschiedenen Personen. Ein bekanntes Phänomen im Forschungsfeld, schreibt das Team. Zudem seien viele der getesteten Bildklassen nicht im Trainingsdatensatz enthalten gewesen. Mehr Daten könnten die Qualität des Systems also weiter verbessern.
Weitere Informationen und mehr Beispiele gibt es auf der Projektseite von MinD-Vis.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.