Alibaba Qwen3-Omni: KI-Modell verarbeitet Text, Audio und Video in Echtzeit

Das chinesische Technologieunternehmen Alibaba hat mit Qwen3-Omni ein nativ multimodales KI-Modell vorgestellt, das Text, Bilder, Audio und Video verarbeitet und dabei in Echtzeit antwortet.
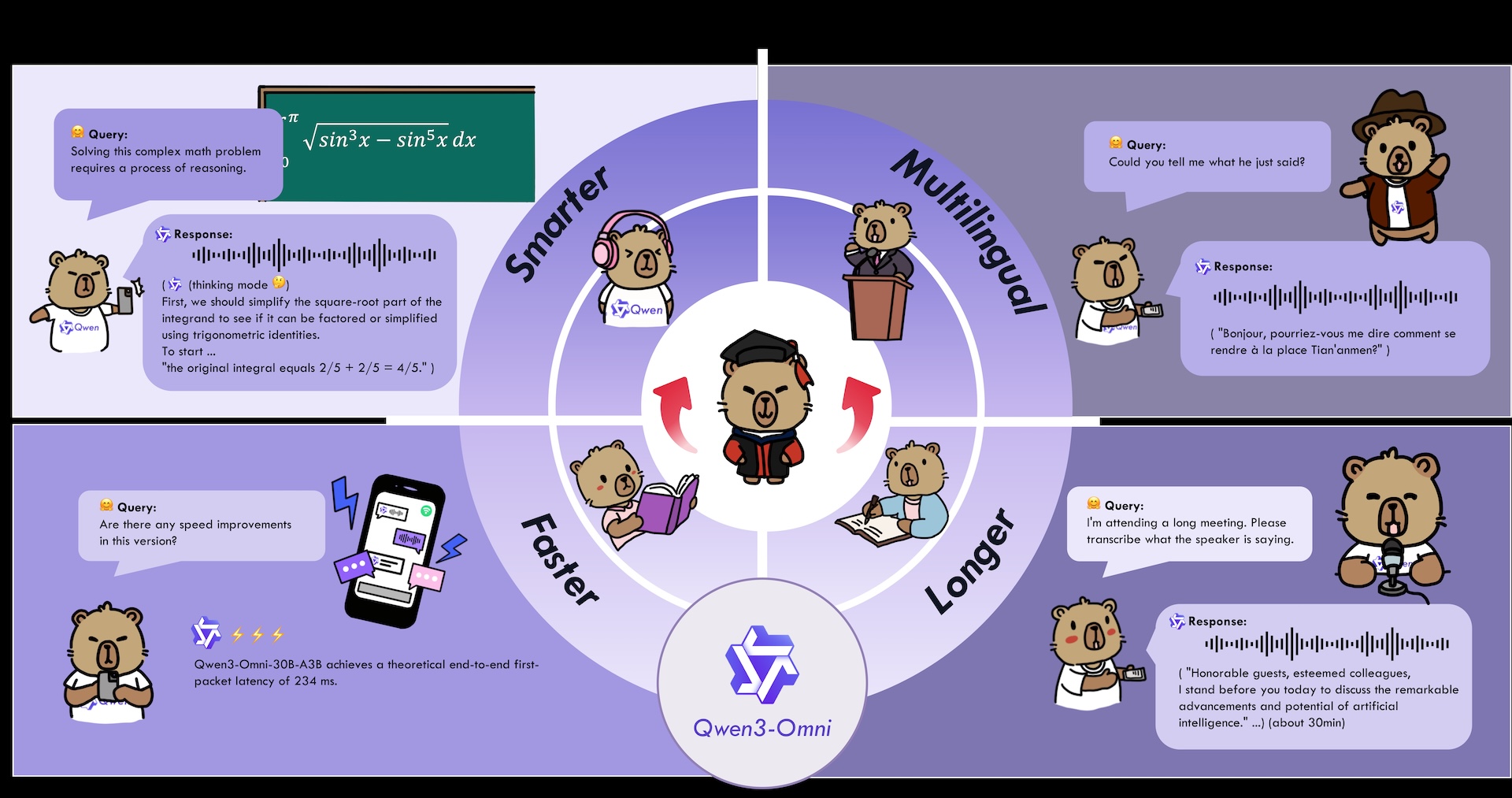
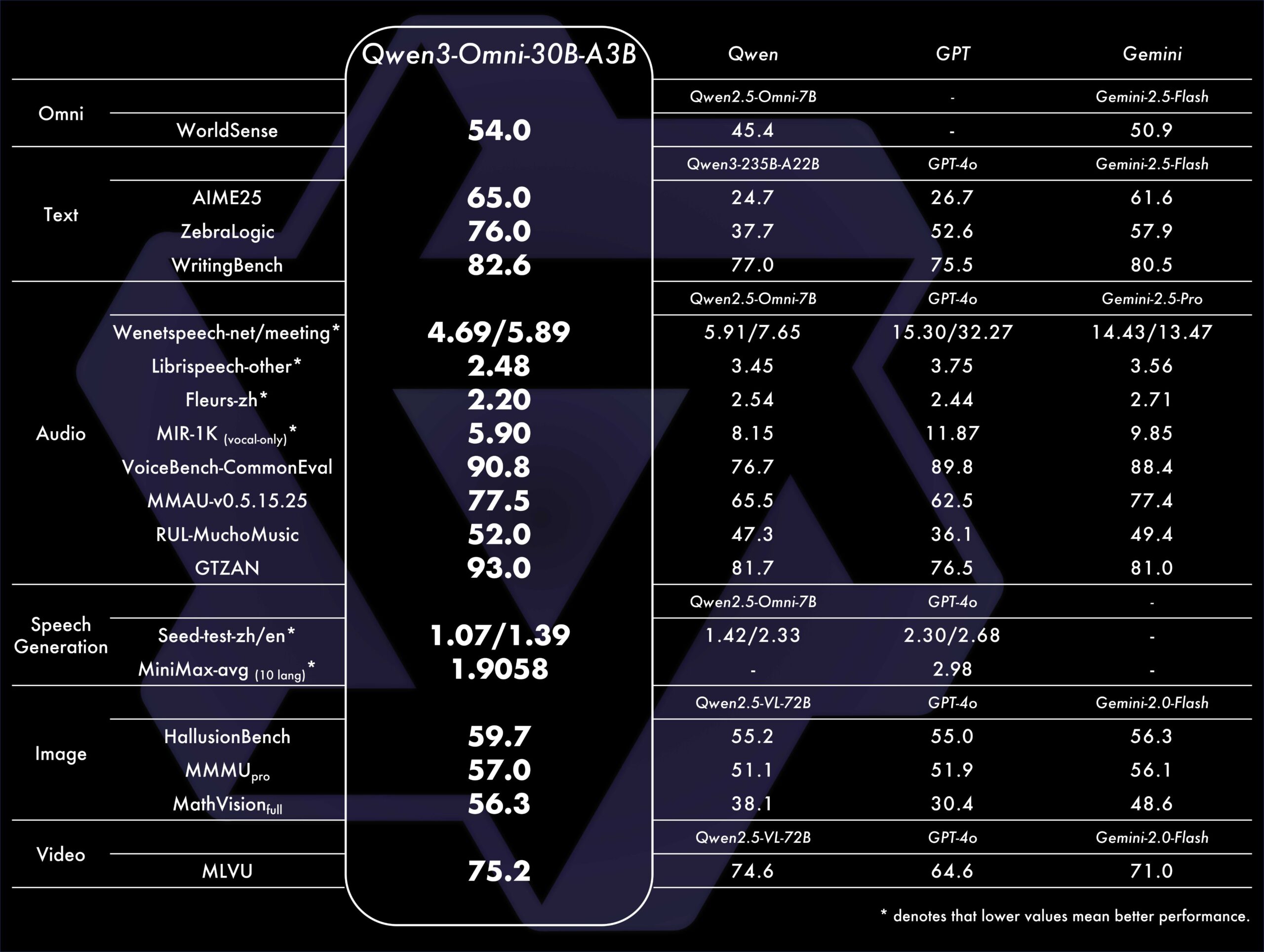
Das System erreicht laut Alibaba Spitzenleistungen auf 32 von 36 Audio- und Video-Benchmarks und übertrifft unter anderem bei Sprachverständnis und Stimmengenerierung etablierte Modelle wie Gemini 2.5 Flash und GPT-4o. Dabei bleibe die Leistung in einzelnen Bereichen auf dem Niveau spezialisierter Modelle, die nur eine Art von Eingabe verarbeiten.
Einen technischen Bericht hat Alibaba bisher nicht veröffentlicht, aus dem Blogpost und den Benchmarkergebnissen lassen sich jedoch ein paar Punkte herauslesen. So nutzt das 30-Milliarden-Parameter-Modell eine Mixture-of-Experts-Architektur mit jeweils drei Milliarden aktiven Parametern bei Inferenz.
Ein Kernmerkmal ist die niedrige Reaktionszeit: Das Modell antwortet bei reinen Audio-Eingaben bereits nach 211 Millisekunden und bei kombinierter Audio-Video-Verarbeitung nach 507 Millisekunden.
Dass Qwen3-Omni in den von Alibaba ausgewählten Tests oft mit führenden kommerziellen Modellen mithalten kann, ist angesichts seiner vergleichsweise kompakten Architektur bemerkenswert. Dennoch ist fraglich, ob es über die ausgewählten Benchmarks hinaus in der alltäglichen Nutzung tatsächlich durchgehend das Niveau von Modellen wie GPT-4o oder Gemini 2.5 Flash erreicht.
Zweiteilige Architektur für schnelle Verarbeitung
Qwen3-Omni basiert auf einer zweigeteilten Architektur. Der "Thinker"-Teil analysiert Eingaben und generiert Textantworten, während der "Talker" diese direkt in Sprachausgabe umsetzt. Beide Komponenten arbeiten parallel, um Verzögerungen zu minimieren.
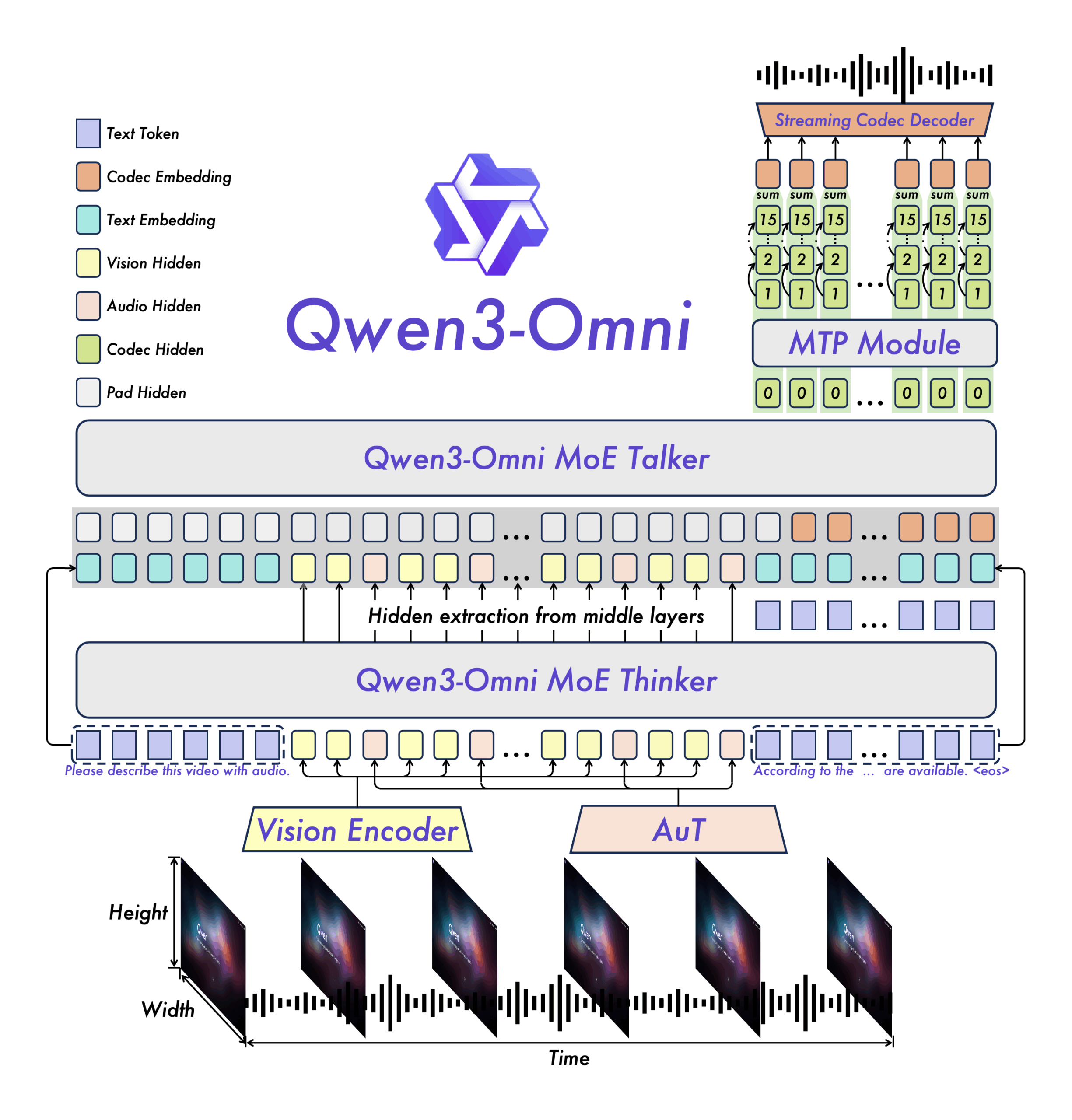
Für die Echtzeitausgabe generiert das System Audiodaten schrittweise, anstatt komplette Audiodateien zu erstellen. Dabei wird jeder Verarbeitungsschritt sofort in hörbare Sprache umgewandelt, was das kontinuierliche Streaming ermöglicht.
Der Audio-Encoder wurde mit 20 Millionen Stunden Audiomaterial trainiert. Beide Hauptkomponenten nutzen eine Architektur mit mehreren spezialisierten Teilsystemen, die parallel arbeiten und so hohen Durchsatz bei schneller Verarbeitung erlauben.
Umfassende Sprachunterstützung
Das Modell verarbeitet Text in 119 Sprachen, versteht gesprochene Sprache in 19 Sprachen und kann selbst in 10 Sprachen antworten. Audio-Inhalte von bis zu 30 Minuten Länge kann es analysieren und zusammenfassen.
Laut Alibaba wurde das System so trainiert, dass es in allen unterstützten Modalitäten gleich gute Leistungen erbringt. Das Unternehmen betont, dass keine Einbußen in einzelnen Bereichen auftreten, obwohl das Modell gleichzeitig mehrere Arten von Eingaben verarbeiten kann.
Nutzer:innen können das Verhalten des Systems über spezielle Anweisungen anpassen, etwa Antwort-Stil oder Persönlichkeitsmerkmale verändern. Zusätzlich kann Qwen3-Omni externe Tools und Services einbinden, um komplexere Aufgaben zu lösen.
Zusätzliches Modell für Audio-Beschreibungen
Parallel veröffentlicht Alibaba mit Qwen3-Omni-30B-A3B-Captioner ein separates Modell, das Audio-Inhalte wie Musikstücke detailliert analysiert. Das System soll präzise Beschreibungen mit wenigen Fehlern liefern und eine Lücke im Open-Source-Bereich schließen.

Für die Zukunft plant Alibaba Verbesserungen bei der Erkennung mehrerer Sprecher, der Texterkennung in Videos und dem Lernen aus Audio-Video-Kombinationen. Auch die Fähigkeit, als autonomer Agent zu arbeiten, soll ausgebaut werden.
Qwen3-Omni ist über Qwen Chat sowie eine Demo auf Hugging Face verfügbar. Entwickler:innen können das Modell über eine API-Plattform in eigene Anwendungen integrieren.
Das Unternehmen hat zwei spezialisierte Versionen als Open Source veröffentlicht: Qwen3-Omni-30B-A3B-Instruct für Anweisungsbefolgung und Qwen3-Omni-30B-A3B-Thinking für komplexe Denkaufgaben.
Alibabas Consumer-Modell
Alibaba hat zusammen mit dem Modell ein Promotionsvideo auf Youtube veröffentlicht, das Anwendungsfälle für Qwen3-Omni demonstriert. Beim Übersetzen einer Speisekarte etwa kommt ein Wearable zum Einsatz. Dahingehend hatte Alibaba erst vor wenigen Monaten die Quark AI Glasses präsentiert. Die ChatGPT-Alternative Quark ist in chinesischen App Stores außerdem sehr beliebt.
Mit Qwen3-Omni wird Alibaba höchstwahrscheinlich noch mehr Endnutzer:innen erreichen und sieht seine Zielgruppe dabei offenbar nicht nur in China, sondern auch in der westlichen Hemisphäre, wie der englischsprachige Werbeclip unterstreicht.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.