Alibabas Qwen3-Next setzt auf schnellere MoE-Architektur

Update –
- FP8-Modelle ergänzt
Update vom 23.09.2025:
Alibaba veröffentlicht zwei neue Varianten seiner Qwen3-Next-Serie mit FP8-Präzision. Die Modelle Qwen3-Next-80B-A3B-Instruct-FP8 und Qwen3-Next-80B-A3B-Thinking-FP8 nutzen das FP8-Format (8-Bit Floating Point), das eine deutlich höhere Verarbeitungsgeschwindigkeit ermöglichen soll. Sie sind vollständig kompatibel mit Frameworks wie Transformers, vLLM und SGLang.
Die FP8-Variante zielt auf Anwendungen mit hohen Geschwindigkeitsanforderungen ab, etwa bei der Bereitstellung von KI-Diensten im Echtzeitbetrieb. Im Vergleich zu herkömmlichen Formaten wie FP16 oder INT8 bietet FP8 ein besseres Verhältnis zwischen Rechenleistung und Energieverbrauch bei geringem Qualitätsverlust in der Antwortgenauigkeit.
Beide Modelle sind ab sofort auf Hugging Face und ModelScope verfügbar. Das Instruct-Modell richtet sich an allgemeine Aufgaben im Chatbot- oder Assistenzbereich. Das Thinking-Modell ist auf Aufgaben mit hohem logischen Anspruch optimiert.
Ursprünglicher Artikel vom 14.09.2025:
Alibaba hat mit Qwen3-Next ein neues Sprachmodell veröffentlicht, das auf eine angepasste Architektur setzt. Das Modell soll damit deutlich schneller rechnen als frühere Varianten – bei vergleichbarer Leistung.
Alibaba hat mit Qwen3-Next ein neues Sprachmodell vorgestellt, das auf eine besonders sparsame MoE-Architektur setzt. Während das Vorgängermodell Qwen3 etwa 128 Experten definierte und bei jedem Inferenzschritt acht davon aktivierte, nutzt Qwen3-Next eine deutlich vergrößerte Expertenschicht mit 512 Experten, aktiviert jedoch nur zehn davon plus einen zusätzlichen gemeinsamen Experten. Die Entwickler versprechen eine mehr als zehnfach höhere Geschwindigkeit im Vergleich zum bisherigen Modell Qwen3-32B, insbesondere bei langen Texteingaben mit mehr als 32.000 Tokens.
Die neue MoE-Variante setzt außerdem auf stabilitätsfördernde Maßnahmen, um typische Probleme wie ungleiche Nutzung der Experten, numerische Instabilitäten oder zufällige Initialisierungsfehler zu vermeiden. Dazu gehören unter anderem eine normalisierte Initialisierung der Router-Parameter oder ein Output-Gating in den Attention-Layern.
Neben dem Basismodell wurden zwei spezialisierte Varianten veröffentlicht: Qwen3-Next-80B-A3B-Instruct für allgemeine Anwendungen und Qwen3-Next-80B-A3B-Thinking für komplexe Denkaufgaben. Das kleinere Instruct-Modell erreicht laut dem Unternehmen nahezu die Leistung von Alibabas Flaggschiffmodell Qwen3-235B-A22B-Instruct, insbesondere bei sehr langen Kontexten bis 256.000 Tokens. Das Thinking-Modell schlägt laut Alibaba das geschlossene Gemini-2.5-Flash-Thinking von Google in mehreren Benchmarks und nähert sich in zentralen Metriken dem eigenen Topmodell Qwen3-235B-A22B-Thinking an.
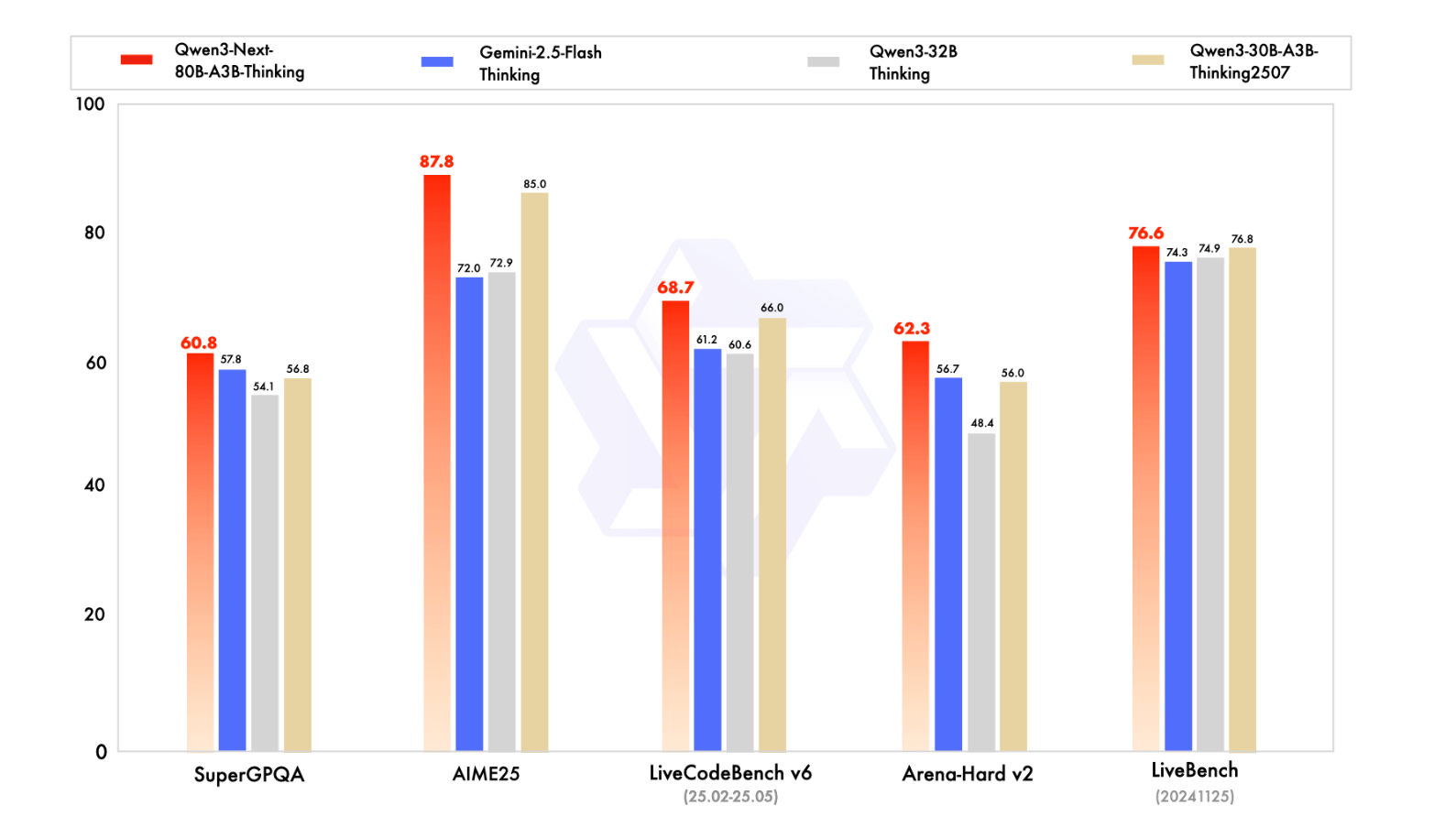
Die Modelle können über Hugging Face, ModelScope oder den Nvidia API Catalog genutzt werden. Für eigene Server empfehlen die Entwickler spezialisierte Frameworks wie sglang oder vllm. Derzeit sind Kontextlängen bis 256.000 Tokens möglich, in Kombination mit speziellen Verfahren auch bis zu einer Million Tokens.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.