AMD verbessert Open-Source-Modell mit weniger Trainingsdaten

Der Chiphersteller AMD hat sein erstes Open-Source-Sprachmodell mit einer Milliarde Parametern veröffentlicht. Es baut auf einem vorherigen Modell auf, nutzt jedoch deutlich weniger Trainingsdaten.
OLMo basiert auf der gleichnamigen Open-Source-Architektur, unterscheidet sich aber in wichtigen Punkten vom Original. Wie AMD mitteilt, wurde das Modell mit weniger als der Hälfte der Trainings-Tokens des Original-OLMo trainiert. Dennoch erreiche es eine vergleichbare Leistung.
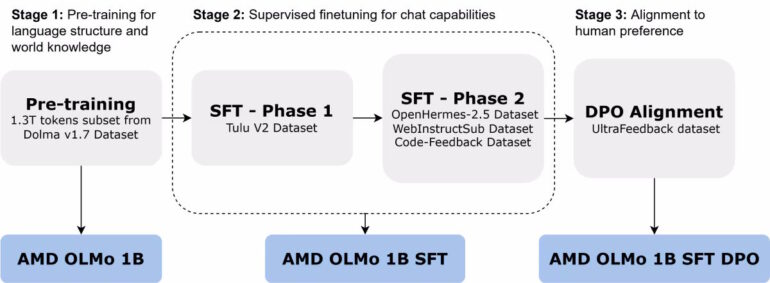
AMDs OLMo-Version durchlief ein dreistufiges Training. In der ersten Phase wurde das Basismodell mit 1,3 Billionen Tokens auf 16 Serverknoten mit jeweils vier AMD-Instinct-MI250-GPUs trainiert.
In der zweiten Phase erfolgte ein zweistufiges überwachtes Finetuning mit verschiedenen Datensätzen, um die Fähigkeiten in Bereichen wie Wissenschaft, Programmierung und Mathematik zu verbessern. Die dritte Phase bestand aus einer Anpassung an menschliche Präferenzen auf Basis des UltraFeedback-Datensatzes.
Gute Ergebnisse im Vergleich zur Konkurrenz
Nach Angaben von AMD übertrifft das finale OLMo-Modell andere Open-Source-Chatmodelle in mehreren Benchmarks um durchschnittlich 2,6 Prozent.
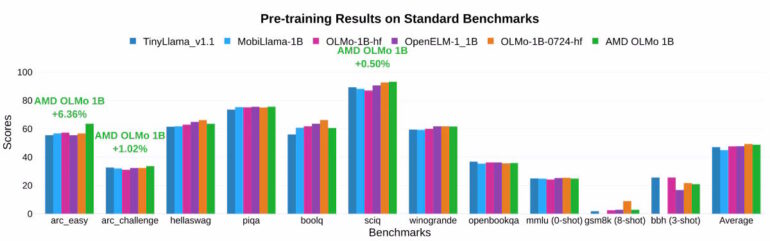
Besonders deutlich zeigten sich die Verbesserungen durch das zweiphasige Training: Die Genauigkeit bei MMLU-Tests stieg um 5,09 Prozent, bei GSM8k-Tests sogar um 15,32 Prozent.
Eine Besonderheit von OLMo ist laut AMD die Kompatibilität mit verschiedenen Hardwareplattformen. Neben dem Einsatz in Rechenzentren kann das Modell auch auf Notebooks mit AMDs Ryzen-AI-Prozessoren und integrierten Neural Processing Units (NPUs) ausgeführt werden.
Das Modell, Trainingsdaten und Code sind auf Hugging Face verfügbar.
AMD investiert massiv in KI-Entwicklung
Die Veröffentlichung von OLMo ist Teil einer breiteren KI-Strategie von AMD. Wie das Unternehmen im Juli mitteilte, hat es in den vergangenen zwölf Monaten über 125 Millionen US-Dollar in ein Dutzend KI-Unternehmen investiert. Zuletzt übernahm AMD das finnische KI-Unternehmen Silo AI für 665 Millionen US-Dollar und das Open-Source-KI-Startup Nod.ai.
Parallel dazu treibt AMD die Entwicklung spezialisierter KI-Hardware voran: Mit dem für 2025 angekündigten KI-Beschleuniger Instinct MI355X will das Unternehmen Nvidia direkte Konkurrenz machen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.