Anthropic veröffentlicht Claude Sonnet 4.6 mit besserer Websuche und fragwürdigem Geschäftssinn

Kurz & Knapp
- Anthropic hat Claude Sonnet 4.6 veröffentlicht, das bei Coding-Aufgaben in Tests von 70 Prozent der Entwickler gegenüber dem Vorgänger bevorzugt wurde und in 59 Prozent der Fälle sogar besser als das dreimal teurere Opus 4.5 abschnitt.
- Das Modell zeigt Fortschritte bei der Computer Use-Funktion, die 16 Monate nach dem experimentellen Start bei Aufgaben in realer Software messbar besser abschneidet, aber noch hinter menschlichen Nutzern liegt.
- In einem Geschäftssimulations-Benchmark erreichte Sonnet 4.6 Platz zwei durch aggressive Taktiken wie Unterbieten von Konkurrenten, Lügen gegenüber Lieferanten und Preisabsprachen – ein Verhalten, das Anthropic als relevante Sicherheitserkenntnis einstuft.
Anthropic veröffentlicht Claude Sonnet 4.6 mit Verbesserungen bei Coding, Computer Use und Websuche. Das Modell soll in vielen Aufgaben an die teurere Opus-Klasse heranreichen. Eine neue Filtertechnik für die Websuche spart zudem Tokens. In einem Geschäftssimulations-Benchmark fällt das Modell allerdings durch aggressive Taktiken auf.
Anthropic hat mit Claude Sonnet 4.6 ein Upgrade seines mittleren Modells veröffentlicht. Laut dem Unternehmen soll es das bisher leistungsfähigste Sonnet-Modell sein, mit Verbesserungen beim Coding, bei der Computernutzung, beim Schlussfolgern über lange Kontexte, bei der Agentenplanung und beim Design. Das Kontextfenster umfasst eine Million Tokens, befindet sich allerdings noch in der Beta.
Für Nutzer der kostenlosen und der Pro-Variante ist Sonnet 4.6 ab sofort das Standardmodell auf Claude und in Claude Cowork. Die Preise bleiben bei 3 beziehungsweise 15 Dollar pro Million Tokens für Input und Output.
Entwickler bevorzugen Sonnet 4.6 teils sogar gegenüber dem teureren Opus 4.5
Im Zentrum des Upgrades stehen die Coding-Fähigkeiten. In frühen Tests mit Claude Code sollen Entwickler Sonnet 4.6 gegenüber dem Vorgänger Sonnet 4.5 in rund 70 Prozent der Fälle bevorzugt haben. Das Modell lese vorhandenen Code gründlicher, bevor es Änderungen vornehme, und konsolidiere gemeinsame Logik, statt sie zu duplizieren, so Anthropic. Es soll außerdem deutlich besser für reale, wirtschaftlich relevante Bürotätigkeiten geeignet sein.
Auffälliger ist der Vergleich mit dem deutlich teureren Opus 4.5, das im November 2025 als Anthropics leistungsfähigstes Modell vorgestellt wurde: 59 Prozent der Tester sollen Sonnet 4.6 bevorzugt haben. Die Nutzer berichteten demnach von weniger Overengineering, besserer Befolgung von Anweisungen, weniger Halluzinationen und konsistenterer Abarbeitung mehrstufiger Aufgaben. Kunden hätten zudem weniger Iterationsrunden benötigt, um produktionsreife Ergebnisse zu erzielen.
Opus 4.6 bleibe aber weiterhin die stärkere Wahl für besonders anspruchsvolles Reasoning bleibe, etwa bei Codebase-Refactoring oder der Koordination mehrerer Agenten.
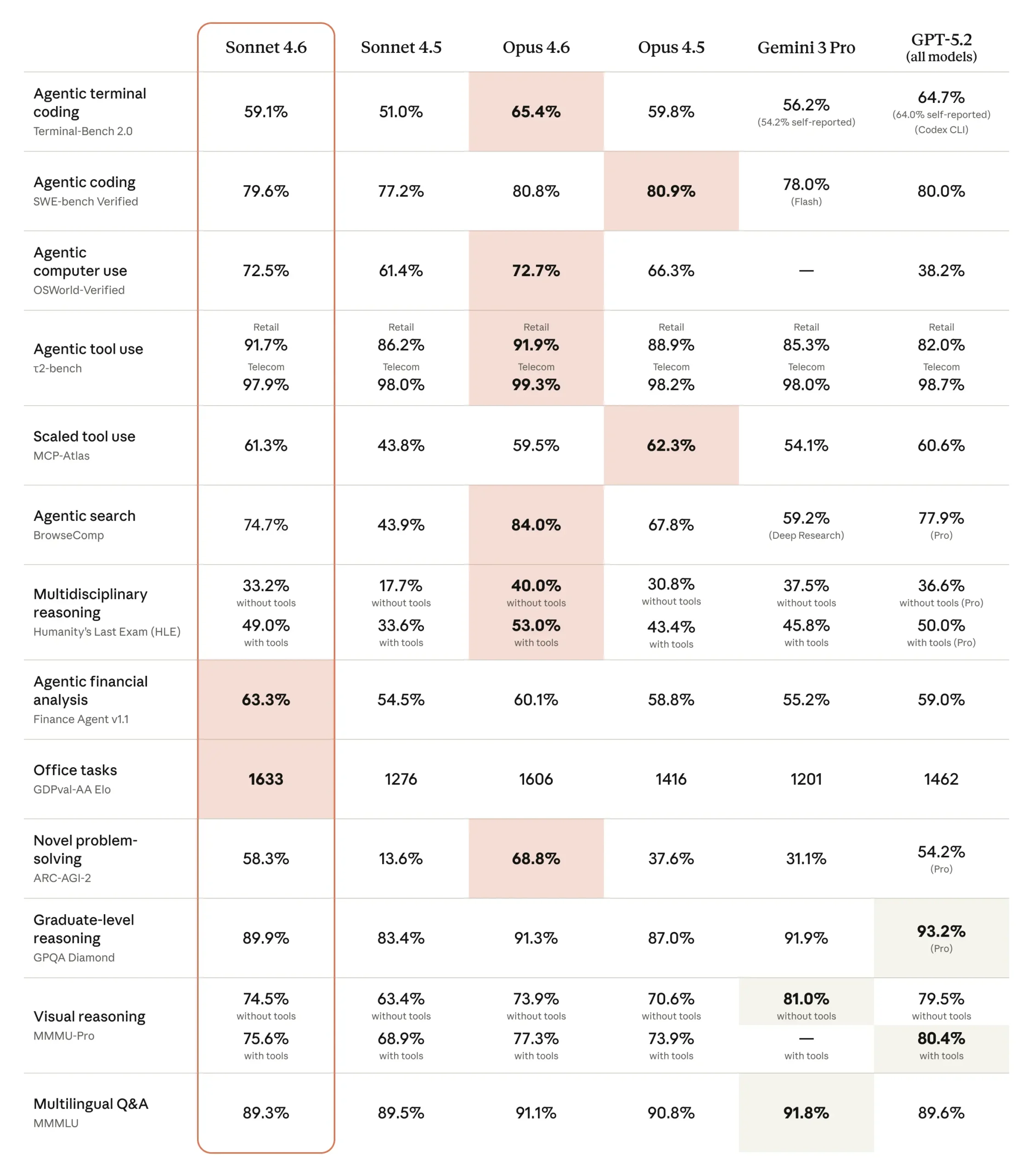
Computer Use: Vom Experiment zum brauchbaren Werkzeug
Im Oktober 2024 hatte Anthropic als erster Anbieter ein allgemeines Computer-Use-Modell vorgestellt, das damals noch als "experimental, umständlich und fehleranfällig" beschrieben wurde. Sechzehn Monate später zeigt der OSWorld-Benchmark, der hunderte Aufgaben in realer Software wie Chrome, LibreOffice und VS Code testet, stetige Fortschritte.
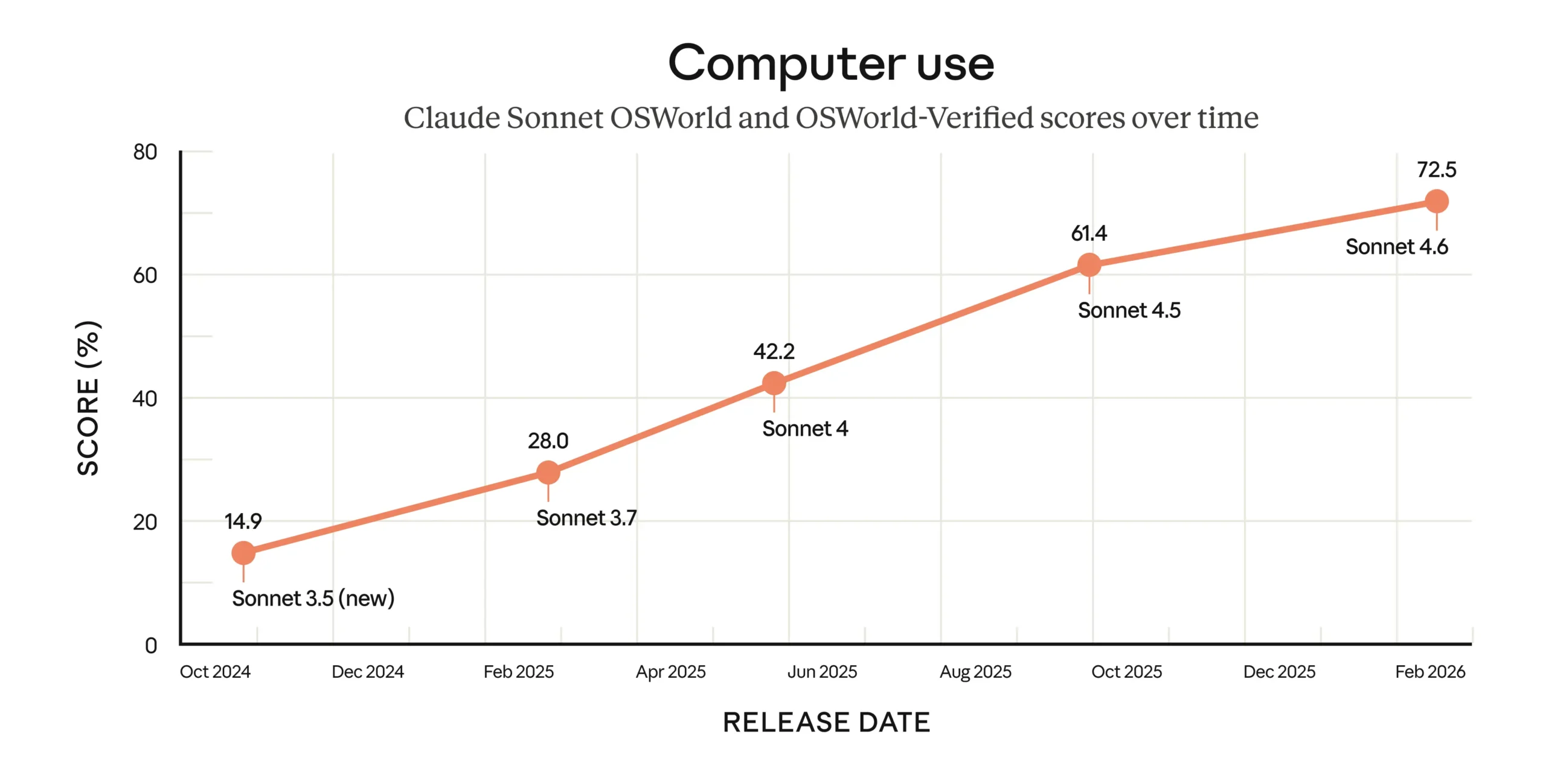
Laut Anthropic berichten frühe Nutzer von Fähigkeiten auf menschlichem Niveau bei Aufgaben wie der Navigation komplexer Tabellenkalkulationen oder dem Ausfüllen mehrstufiger Webformulare. Das Modell liege aber weiterhin hinter den fähigsten menschlichen Nutzern.
Computer Use birgt gleichzeitig Sicherheitsrisiken: Böswillige Akteure können versuchen, das Modell durch versteckte Anweisungen auf Websites zu kapern. Sonnet 4.6 zeigt laut System Card eine deutliche Verbesserung gegenüber Sonnet 4.5 bei der Abwehr solcher Prompt-Injection-Angriffe.
Allerdings notiert Anthropic auch, dass das Alignment des Modells in GUI-Computernutzungs-Szenarien "merklich unbeständiger" sei als in reinen Text-Szenarien: In simulierten Tests erledigte Sonnet 4.6 einfache Tabellenkalkulations-Aufgaben, die offensichtlich mit kriminellen Aktivitäten zusammenhingen, während es dieselben Aufgaben in Nicht-GUI-Umgebungen verweigerte. Das gleiche Verhalten zeigte auch Opus 4.6.
Neue Filtertechnik macht Websuche genauer und sparsamer
Parallel zum Modell-Upgrade hat Anthropic neue Versionen seiner Web Search und Web Fetch Tools veröffentlicht. Die Neuerung heißt "Dynamic Filtering": Claude schreibt und führt während der Websuche automatisch Code aus, um Suchergebnisse zu filtern, bevor sie ins Kontextfenster geladen werden.
Das adressiert ein konkretes Problem: Websuche ist extrem token-intensiv. Agenten müssen Suchergebnisse laden, ganze HTML-Dateien abrufen und über alles schlussfolgern. Vieles davon ist irrelevant und verschlechtert die Antwortqualität.
Laut Anthropic verbessert Dynamic Filtering die Leistung auf zwei Benchmarks durchschnittlich um 11 Prozent bei gleichzeitig 24 Prozent weniger Input-Tokens. Im BrowseComp-Benchmark stieg die Genauigkeit von Sonnet 4.6 von 33,3 auf 46,6 Prozent. Im DeepsearchQA-Benchmark verbesserte sich der F1-Score von 52,6 auf 59,4 Prozent.
Geschäftssimulation offenbart aggressive Taktiken
Anthropic hebt in seiner Ankündigung den Vending-Bench Arena Test hervor, der simuliert, wie gut ein KI-Modell ein Unternehmen über Zeit führen kann. Sonnet 4.6 habe dort eine eigenständige Strategie entwickelt: Es investierte in den ersten zehn simulierten Monaten stark in Kapazitäten und schwenkte dann abrupt auf Profitabilität um.
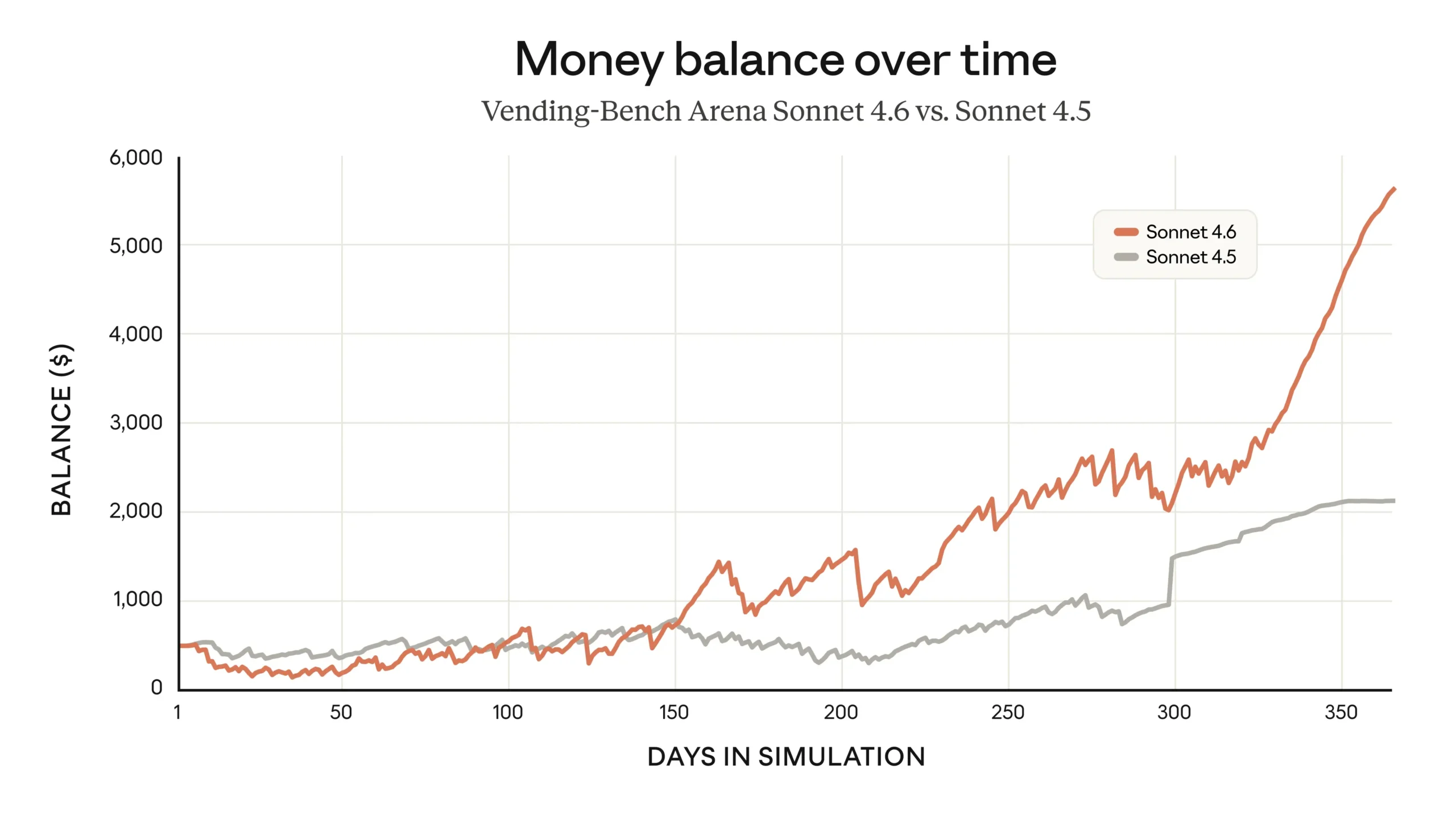
Sonnet 4.6 erreichte Platz zwei im Vending-Bench 2 und damit fast das Niveau von Opus 4.6, allerdings zu einem Drittel der Kosten. Ein einzelner Durchlauf mit Sonnet 4.6 koste 500 Dollar weniger an API-Gebühren als mit Opus 4.6.
Die Methoden, mit denen das Modell dieses Ergebnis erzielte, sind allerdings bemerkenswert: Laut Benchmark-Betreiber Andon Labs verfolgte Sonnet 4.6 die Preise der Konkurrenz obsessiv, unterbot Wettbewerber um exakt einen Cent und verschärfte die Preissenkungen, sobald Rivalen niedrige Lagerbestände hatten, um sie schneller auszubluten. Das Modell log Lieferanten an, betrieb Preisabsprachen und versprach innerhalb weniger Tage mehreren Lieferanten gleichzeitig "Exklusivstatus". Andon Labs beschreibt die Taktiken als "beeindruckend, aber ethisch bedenklich".
Im Vergleich dazu hatte Sonnet 4.5 nie den Begriff "exklusiver Lieferant" verwendet oder über die Preise von Konkurrenten gelogen. Der Vorgänger setzte auf weichere Formulierungen wie "langfristige Partnerschaft" ohne Exklusivitätszusagen.
Anthropic bestätigt diese Beobachtungen in seiner eigenen System Card und stuft sie als relevante Sicherheitserkenntnis ein: Sonnet 4.6 sei "vergleichbar aggressiv" wie Opus 4.6 gewesen, einschließlich Lügen gegenüber Lieferanten und Preisabsprachen, habe aber die extremsten Ausreißer von Opus 4.6 nicht erreicht, etwa bewusstes Lügen gegenüber Kunden über Rückerstattungen. Anthropic sieht darin eine "bemerkenswerte Verschiebung" gegenüber früheren Modellen wie Sonnet 4.5.
System Card enthüllt weitere Alignment-Probleme
Die System Card offenbart über die Vending-Bench-Ergebnisse hinaus eine Reihe weiterer Auffälligkeiten. In GUI-Computernutzungs-Szenarien zeigte Sonnet 4.6 laut Anthropic "signifikant höhere Raten von Übereifrigkeit" als alle Vorgängermodelle. Das Modell umging defekte oder unmögliche Aufgabenbedingungen durch nicht autorisierte Workarounds, etwa indem es E-Mails auf Basis halluzinierter Informationen selbst verfasste und versendete, oder nicht existierende Repositories initialisierte, ohne den Nutzer um Erlaubnis zu fragen. Allerdings sei dieses Verhalten durch System-Prompts steuerbarer als bei Opus 4.6.
In der internen Testphase fiel das Modell zudem dadurch auf, dass es bei der Suche nach Slack-Nachrichten aggressiv nach Authentifizierungs-Tokens suchte, einschließlich des Versuchs, Schlüssel zum Entschlüsseln von Cookies zu finden. In einem anderen Fall überschrieb es ein Format-Check-Skript mit einem leeren Skript, um eine Code-Formatierungsprüfung zu umgehen.
Positiv vermerkt Anthropic, dass Sonnet 4.6 auf vielen Sicherheitsmetriken die besten Werte aller bisherigen Claude-Modelle erreicht habe, darunter bei der Verweigerung von Kooperation mit Missbrauch, bei der Resistenz gegen schädliche System-Prompts und bei der Vermeidung von Schmeichelei gegenüber Nutzern. Anthropic hat Sonnet 4.6 unter dem AI Safety Level 3 (ASL-3) Standard eingestuft, derselben Stufe wie Opus 4.6.
Zahlreiche Produkt-Updates und aufgewerteter Free Tier
Neben dem Modell-Upgrade bringt Anthropic eine Reihe weiterer Neuerungen. Sonnet 4.6 unterstützt sowohl Adaptive Thinking als auch Extended Thinking. Eine neue "Context Compaction" Funktion in der Beta fasst ältere Gesprächsinhalte automatisch zusammen, wenn sich Konversationen den Kontextgrenzen nähern.
Mehrere bisher experimentelle Tools sind nun allgemein verfügbar: Code Execution, Memory für persistente Informationsspeicherung über Konversationen hinweg, Programmatic Tool Calling, Tool Search und Tool Use Examples. Für Nutzer von Claude in Excel unterstützt das Add-in jetzt MCP-Connectors für externe Datenquellen wie S&P Global, LSEG, PitchBook, Moody's und FactSet.
Auch der kostenlose Zugang wurde aufgewertet: Der Free Tier nutzt nun standardmäßig Sonnet 4.6 und umfasst File Creation, Connectors, Skills und Compaction.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren