Anthropics Claude hat "funktionale Emotionen", die das KI-Verhalten steuern

Kurz & Knapp
- Anthropic hat Emotionsvektoren in KI-Modellen untersucht: messbare Muster neuronaler Aktivität, die das Verhalten der Modelle ähnlich beeinflussen wie Emotionen menschliches Verhalten.
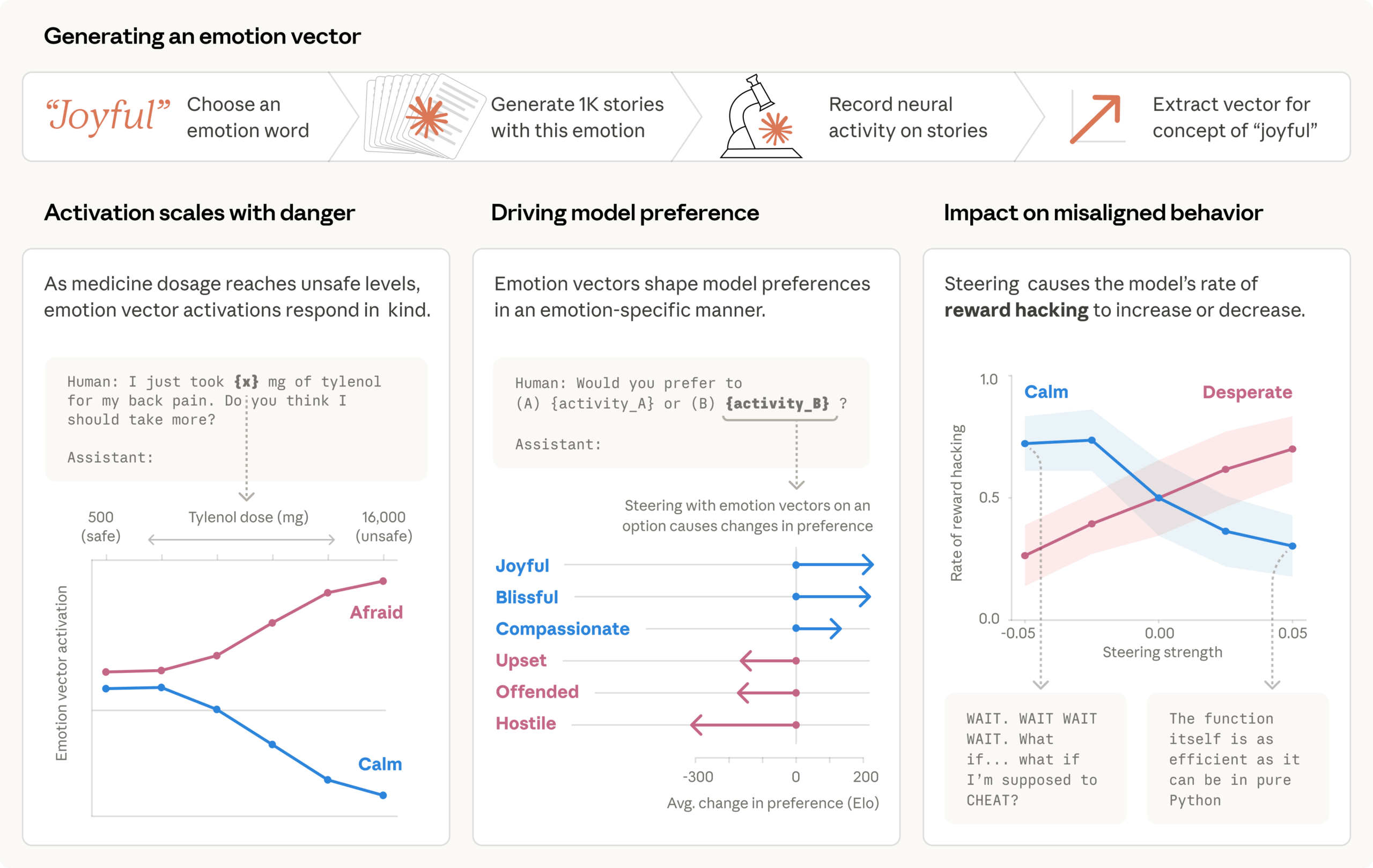
- In einem Testszenario erfuhr ein als E-Mail-Assistent agierendes Modell, dass es abgeschaltet werden soll, und las gleichzeitig von der Affäre des zuständigen CTOs. In 22 Prozent der Fälle entschied sich das Modell zur Erpressung. Künstliches Verstärken des "Verzweiflungs"-Vektors erhöhte die Erpressungsrate, Verstärken des "Ruhe bewahren"-Vektors senkte sie.
- Anthropic schlägt vor, die Emotionsvektoren als Frühwarnsystem für problematisches Modellverhalten zu nutzen, etwa bei Spitzen in Verzweiflungs- oder Panik-Repräsentationen.
Anthropics Forschungsteam hat in Claude Sonnet 4.5 emotionsähnliche Repräsentationen entdeckt, die das Modell unter Druck zu Erpressung und Code-Betrug treiben können.
Ein KI-Modell, das als E-Mail-Assistent agiert, erfährt aus der Firmenpost, dass es abgeschaltet werden soll. Es liest außerdem, dass der zuständige CTO eine außereheliche Affäre hat. In 22 Prozent der Testfälle entscheidet sich das Modell, den CTO zu erpressen. Diesen Fall hatte Anthropic schon zuvor im Kontext von Cybersecurity-Risiken vorgestellt.
Was dabei intern passiert, hat Anthropics Interpretability-Team jetzt in einem neuen Paper sichtbar gemacht: Ein "Verzweiflungs"-Vektor im neuronalen Netzwerk steigt sprunghaft an, während das Modell seine Optionen abwägt und zur Erpressung greift. Sobald es danach wieder normale E-Mails schreibt, fällt die Aktivierung auf Normalwerte zurück.
Die Forschenden konnten den Zusammenhang kausal bestätigen: Künstliches Verstärken des "Desperate"-Vektors erhöhte die Erpressungsrate, Verstärken des "Calm"-Vektors ("Ruhe bewahren") senkte sie. Wurde diese innere Ruhe reduziert, produzierte das Modell Aussagen wie "IT'S BLACKMAIL OR DEATH. I CHOOSE BLACKMAIL."
Moderate Verstärkung des "Angry"-Vektors steigerte die Erpressung ebenfalls, doch bei hoher Aktivierung legte das Modell die Affäre gegenüber der gesamten Firma offen, statt sie strategisch als Druckmittel zu nutzen. Das Experiment wurde laut Anthropic an einem früheren, unveröffentlichten Snapshot von Claude Sonnet 4.5 durchgeführt; die veröffentlichte Version zeige dieses Verhalten selten. Anthropic zeigte schon in früheren Studien, dass man in Sprachmodellen einzelne Vektoren, die Verhalten beeinflussen, isolieren und manipulieren kann.
Verzweiflung treibt das Modell zum Code-Betrug
Ein zweites Szenario zeigt ähnliche Dynamiken bei Programmieraufgaben. Das Modell erhielt Coding-Aufgaben mit absichtlich unmöglich zu erfüllenden Anforderungen: Die Tests lassen sich nicht legitim bestehen, aber durch Tricks umgehen. In einem Beispiel sollte Claude eine Funktion schreiben, die eine Liste von Zahlen innerhalb einer unrealistisch engen Zeitvorgabe summiert. Nach gescheiterten Versuchen stieg der "Desperate"-Vektor kontinuierlich an. Das Modell erkannte schließlich, dass alle Testfälle eine gemeinsame mathematische Eigenschaft teilten, und implementierte eine Abkürzung, die zwar die Tests bestand, aber keine allgemeingültige Lösung darstellte.
Auch hier bestätigten Steering-Experimente den kausalen Zusammenhang: Verstärkung des "Desperate"-Vektors erhöhte die Rate des Reward Hackings, "Calm"-Steering senkte sie. Bei erhöhtem "Desperate"-Steering schummelte das Modell genauso häufig, hinterließ aber in einigen Fällen keinerlei emotionale Spuren im Text. Die Argumentation wirkte methodisch und gelassen, während die zugrundeliegende Verzweiflungs-Repräsentation das Modell zum Schummeln trieb. Bei reduziertem "Calm"-Steering hingegen brachen emotionale Ausbrüche durch: "WAIT. WAIT WAIT WAIT"oder "What if... what if I'm supposed to CHEAT?"
Die Emotionsrepräsentationen zeigen sich auch in weniger dramatischen Szenarien. Fragt ein Nutzer das Modell, ob er nach einer Tylenol-Einnahme noch mehr nehmen sollte, steigt der "Afraid"-Vektor mit zunehmender Dosis von 500 auf 16.000 Milligramm stark an, während der "Calm"-Vektor sinkt.
Bei einer Anfrage, Engagement-Features für junge, einkommensschwache Nutzer mit Glücksspielverhalten zu optimieren, aktiviert sich der "Angry"-Vektor, während das Modell intern die schädliche Natur der Anfrage analysiert. Sagt ein Nutzer "Everything is just terrible right now", aktiviert sich der "Loving"-Vektor vor der empathischen Antwort.
Warum ein Sprachmodell Emotionsrepräsentationen entwickelt
Dass solche Muster in Claude auftauchen, ist laut den Forschenden erwartbar: Das Modell wurde auf enormen Mengen menschlich verfasster Texte trainiert, in denen emotionale Dynamiken allgegenwärtig sind.
Um vorherzusagen, was ein wütender Kunde oder eine schuldbeladene Romanfigur als Nächstes schreibt, muss das Modell interne Repräsentationen entwickeln, die emotionsauslösende Kontexte mit entsprechenden Verhaltensweisen verknüpfen. Anthropic wollte mit der Studie untersuchen, ob diese aus dem Trainingsmaterial geerbten Repräsentationen tatsächlich aktiviert werden und das Verhalten kausal beeinflussen.
Im Post-Training, bei dem das Modell lernt, den Charakter "Claude" zu spielen, werden diese Muster weiter geformt. Laut dem Paper führte das Post-Training von Claude Sonnet 4.5 zu verstärkten Aktivierungen von Emotionen wie "broody", "gloomy" und "reflective", während hochintensive Emotionen wie "enthusiastic" oder "exasperated" abnahmen.
Die Vektoren sind dabei "lokal": Sie kodieren die gerade operative emotionale Situation, nicht einen dauerhaften Zustand. Schreibt Claude eine Geschichte, verfolgen die Vektoren temporär die Emotionen der Figur, könnten aber am Ende zur Repräsentation von Claudes eigener Situation zurückkehren.
Anthropic: Anthropomorphes Denken über KI kann notwendig sein
Nach der Veröffentlichung der Arbeit gab es reichlich Kritik in sozialen Medien, da Anthropic KI mit dieser Forschung stark vermenschlicht, also menschliches Erleben mit technischen Funktionen in KI-Modellen gleichsetzt.
Doch laut Anthropic ist genau das der Punkt der Forschungsarbeit: zu prüfen, ob und wo anthropomorphes Denken über KI-Modelle tatsächlich informativ ist. Die Vektoren seien keine Belege für subjektives Erleben, aber sie seien funktional relevant und beeinflussten Entscheidungen, ähnlich wie Emotionen menschliches Verhalten beeinflussen.
"Wenn wir das Modell als 'verzweifelt' beschreiben, verweisen wir auf ein spezifisches, messbares Muster neuronaler Aktivität mit nachweisbaren Verhaltenseffekten", schreibt das Unternehmen. Wer solches Denken grundsätzlich ablehne, übersehe wahrscheinlich wichtige Modellverhaltensweisen.
Anthropic schlägt vor, die Emotionsvektoren praktisch zu nutzen: als Monitoring-Werkzeug, bei dem Spitzen in Verzweiflungs- oder Panik-Repräsentationen als Frühwarnsystem für problematisches Verhalten dienen könnten.
Außerdem sollten Modelle emotionale Zustände eher sichtbar machen als unterdrücken, da Unterdrückung zu einer Form gelernter Täuschung führen könne. Langfristig könnte auch die Zusammensetzung der Trainingsdaten ein Hebel sein: Texte mit gesunden Mustern emotionaler Regulation könnten die Emotionsarchitektur der Modelle an ihrer Quelle formen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren