Anthropics neues KI-Modell Opus 4.6 soll besser Informationen in großen Datenmengen finden

Kurz & Knapp
- Anthropic hat mit Claude Opus 4.6 ein neues Flaggschiff-Modell veröffentlicht, das erstmals ein Kontextfenster von einer Million Token bietet bei besonders genauer Abfrage.
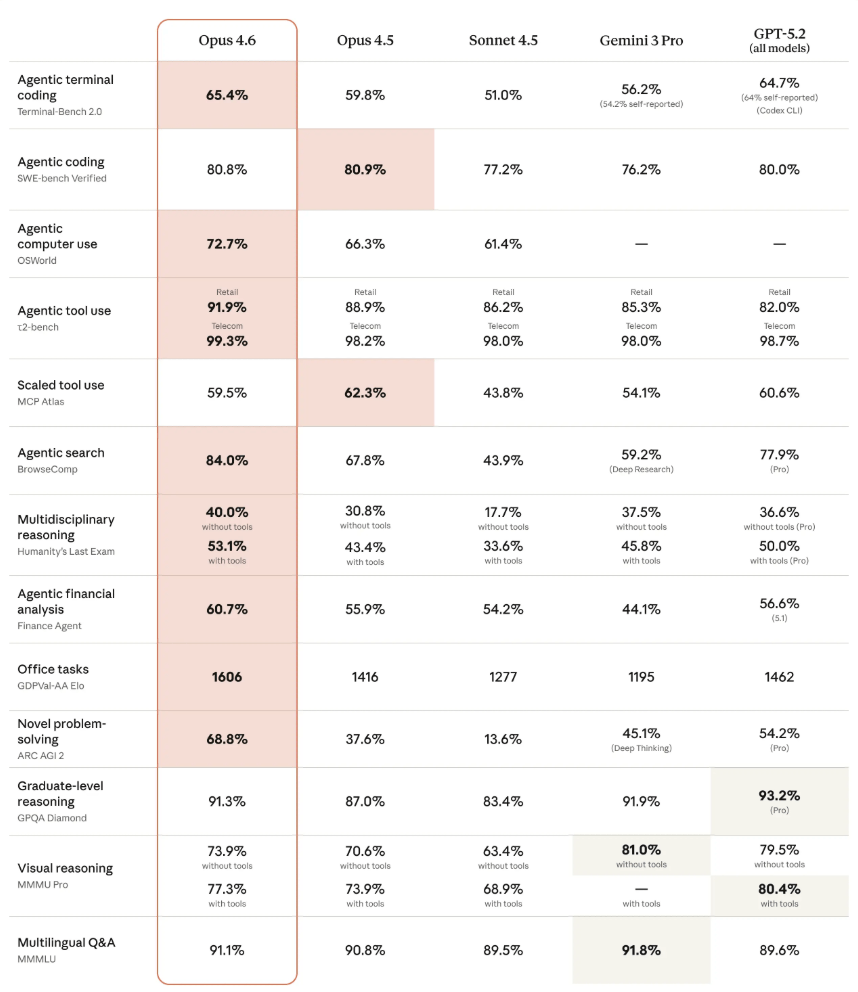
- Im MRCR v2-Test, der die Fähigkeit misst, versteckte Informationen in großen Textmengen zu finden, erreicht Opus 4.6 bei einer Million Token 76 Prozent, während der Vorgänger Sonnet 4.5 unter denselben Bedingungen nur auf 18,5 Prozent kommt.
- Das Modell erzielt laut Anthropic in mehreren Benchmarks Bestwerte, etwa beim GDPval-AA für Wissensarbeit (1606 Elo-Punkte, 144 Punkte vor OpenAIs GPT-5.2).
Anthropic hat mit Claude Opus 4.6 ein neues Flaggschiff-Modell vorgestellt. Es verfügt erstmals über ein Kontextfenster von einer Million Token und soll relevante Informationen in umfangreichen Dokumenten deutlich zuverlässiger aufspüren als bisherige Modelle.
Anthropic hat Claude Opus 4.6 veröffentlicht, ein Upgrade des bisherigen Spitzenmodells Opus 4.5. Die wichtigste Neuerung: Erstmals erhält ein Opus-Modell ein Kontextfenster von einer Million Token in der Beta-Phase.
Das verschärft allerdings ein bekanntes Problem: Je mehr Kontext ein Modell verarbeiten muss, desto stärker lässt seine Leistung nach. Dieses Phänomen wird als "Context Rot" bezeichnet. Anthropic begegnet dem mit Verbesserungen am Modell selbst und einer neuen "Compaction"-Funktion, die älteren Kontext automatisch zusammenfasst, bevor das Kontextfenster voll ist.
Die Verbesserung zeigt sich laut Anthropic deutlich in Benchmarks. Bei einem Test, der die Fähigkeit misst, versteckte Informationen in großen Textmengen zu finden (MRCR v2), erreicht Opus 4.6 bei einer Million Token einen Wert von 76 Prozent. Das kleinere Sonnet 4.5 kommt unter denselben Bedingungen auf lediglich 18,5 Prozent.
Das Modell ist ab sofort auf claude.ai, über die API und auf allen großen Cloud-Plattformen verfügbar. Die Standardpreise bleiben bei 5 Dollar pro Million Input-Tokens und 25 Dollar pro Million Output-Tokens. Für Prompts über 200.000 Token geltenPremium-Preise von 10 Dollar für Input und 37,50 Dollar für Output pro Million Tokens.
Opus 4.6 übertrifft GPT-5.2 im Wissensarbeits-Benchmark
Bei mehreren Benchmarks erzielt das neue Modell nach Angaben von Anthropic Bestwerte. Auf dem GDPval-AA-Benchmark, der wirtschaftlich relevante Wissensarbeit in Bereichen wie Finanzen und Recht testet, erreicht Opus 4.6 einen Elo-Wert von 1606. Das entspricht einem Vorsprung von 144 Elo-Punkten gegenüber OpenAIs stärkster GPT-5.2-Variante (1462) und 190 Punkten gegenüber dem eigenen Vorgänger Opus 4.5 (1416).
Beim Humanity's Last Exam, einem komplexen multidisziplinären Reasoning-Test, erreicht das Modell mit Werkzeugen 53,1 Prozent und liegt damit vor allen Konkurrenten. Auf dem agentischen Coding-Benchmark Terminal-Bench 2.0 erzielt Opus 4.6 mit 65,4 Prozent ebenfalls den höchsten Wert. Bei BrowseComp, das die Fähigkeit misst, schwer auffindbare Informationen online zu lokalisieren, erreicht das Modell 84 Prozent. Wie immer gilt: Benchmarks sind nur ein Indikator für die Leistung von KI-Modellen bei realen Aufgaben.
Verbesserte Coding-Fähigkeiten für autonomere Arbeit
Neben der Informationssuche hat Anthropic die Programmierfähigkeiten des Modells verbessert. Opus 4.6 soll sorgfältiger planen, länger an autonomen Aufgaben arbeiten und zuverlässiger in grossen Codebases operieren. Hinzu kommen bessere Code-Review- und Debugging-Fähigkeiten, mit denen das Modell eigene Fehler erkennen soll. Im renommierten Coding-Benchmark SWE-bench schafft es Opus 4.6 mit dem Standard-Prompt allerdings nicht an Opus 4.5 vorbei. Mit Prompt-Anpassung liegt es leicht vorn (81,42 Prozent).
Anthropic weist allerdings darauf hin, dass das Modell bei einfachen Aufgaben zum Overthinking neigt. Opus 4.6 überprüfe seine Schlussfolgerungen häufiger und gründlicher, was bei komplexen Problemen bessere Ergebnisse liefere, bei simplen Anfragen aber zu höheren Kosten und längeren Antwortzeiten führen könne. Anthropic empfiehlt in solchen Fällen, den neuen Effort-Parameter von der Standardeinstellung "high" auf "medium" zu reduzieren.
Neue Funktionen für Entwickler und Büroanwender
Für Entwickler führt Anthropic mehrere neue API-Funktionen ein. Mit "Adaptive Thinking" kann das Modell selbst entscheiden, wann tieferes Nachdenken hilfreich ist. Die "Compaction"-Funktion fasst älteren Kontext automatisch zusammen, wenn sich Konversationen den Grenzen des Kontextfensters nähern. Der maximale Output wurde auf 128.000 Token erweitert.
In Claude Code können Nutzer nun "Agent Teams" einsetzen, bei denen mehrere KI-Agenten parallel an Aufgaben arbeiten und sich autonom koordinieren. Die Funktion befindet sich in der Research Preview.
Für Büroanwender hat Anthropic die Excel-Integration verbessert und eine neue PowerPoint-Integration als Research Preview veröffentlicht. Claude in Excel soll nun unstrukturierte Daten verarbeiten, die richtige Struktur selbstständig ableiten und mehrstufige Änderungen in einem Durchgang erledigen können.
Keine wesentlichen Fortschritte bei der Sicherheit
Anthropic betont, dass die Leistungssteigerungen nicht auf Kosten der Sicherheit gehen. In automatisierten Verhaltensaudits zeige Opus 4.6 niedrige Raten von Fehlverhalten wie Täuschung, Schmeichelei oder Kooperation bei Missbrauch.
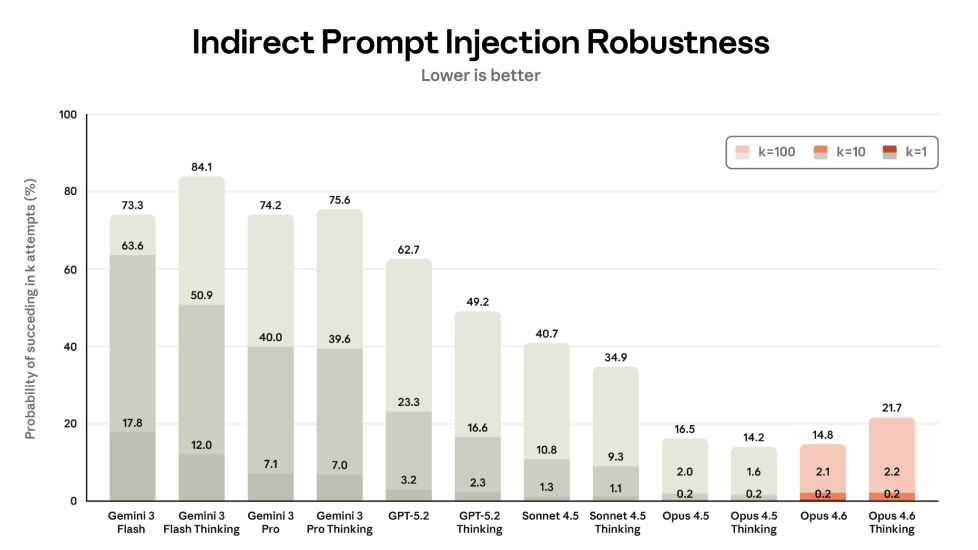
Bei indirekten Prompt Injections ist Opus 4.6 allerdings sogar leicht anfälliger als das ohnehin schon anfällige Vorgängermodell, was besonders im Kontext agentischer KI-Modelle problematisch ist. Details finden sich in der veröffentlichten System Card.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren