ARC-AGI-2 Benchmark macht selbst fortschrittlichsten KI-Systemen zu schaffen

Der neue KI-Benchmark ARC-AGI-2 legt die Messlatte für KI-Tests deutlich höher. Während Menschen die Aufgaben problemlos lösen können, scheitern selbst hoch entwickelte KI-Systeme wie OpenAI o3 deutlich.
François Chollet und sein Team haben mit ARC-AGI-2 eine neue Variante ihres Benchmarks veröffentlicht. Der Test folgt dem gleichen Format wie sein Vorgänger ARC-AGI-1, liefert aber nach Angaben des Teams ein deutlich stärkeres Signal für die tatsächliche Intelligenz eines Systems.
"Es ist ein KI-Benchmark, der die allgemeine fluide Intelligenz messen soll, nicht auswendig gelernte Fähigkeiten - eine Reihe von neuartigen Aufgaben, die Menschen leicht fallen, mit denen aktuelle KI aber zu kämpfen hat", erklärt Chollet auf X.
Der Schwerpunkt liegt dabei auf Fähigkeiten, die heutigen KI-Systemen noch fehlen: Symbolinterpretation, mehrstufiges Kompositionsdenken und kontextabhängige Regelanwendung.
Der Benchmark ist vollständig am Menschen kalibriert: In Tests mit 400 Personen in Live-Sitzungen wurden nur Aufgaben beibehalten, die von mehreren Personen zuverlässig gelöst werden können. Durchschnittliche Testpersonen erreichen ohne vorheriges Training 60 Prozent, während ein Panel von 10 Experten 100 Prozent erreicht.
Today, we're releasing ARC-AGI-2. It's an AI benchmark designed to measure general fluid intelligence, not memorized skills – a set of never-seen-before tasks that humans find easy, but current AI struggles with.
It keeps the same format as ARC-AGI-1, while significantly… pic.twitter.com/9mDyu48znp
— François Chollet (@fchollet) March 24, 2025
Aktuelle KI-Modelle scheitern an ARC-AGI-2
Die Ergebnisse der ersten Tests mit ARC-AGI-2 sind ernüchternd: Selbst die fortschrittlichsten Systeme schneiden extrem schlecht ab. Reine Sprachmodelle wie GPT-4.5, Claude 3.7 Sonnet oder Gemini 2 erreichen null Prozent. Modelle mit einfachem Chain-of-Thought-Reasoning wie Claude 3.7 Sonnet Thinking, R1 oder o3-mini kommen auf magere null bis ein Prozent.

Besonders bemerkenswert ist der Leistungsabfall des OpenAI-Modells o3-low, das beim Vorgänger ARC-AGI-1 noch beeindruckende 75,7 Prozent erreichte, bei ARC-AGI-2 aber auf etwa 4 Prozent abstürzt. Ähnlich dramatisch sieht es beim Gewinner des ARC Prize 2024, dem Team ARChitects, aus: Von 53,5 Prozent bei ARC-AGI-1 auf nur noch 3 Prozent bei ARC-AGI-2. "Im Gegensatz zu ARC-AGI-1 kann diese neue Version nicht einfach mit Brute Force gelöst werden", erklärt das Team. "Aktuelle Top-KI-Ansätze liegen zwischen 0 und 4 Prozent. Man kann diese Aufgaben nicht einfach durch Auswendiglernen lösen. Man braucht die Fähigkeit, Konzepte spontan zu rekombinieren - man braucht Adaption zur Testzeit."
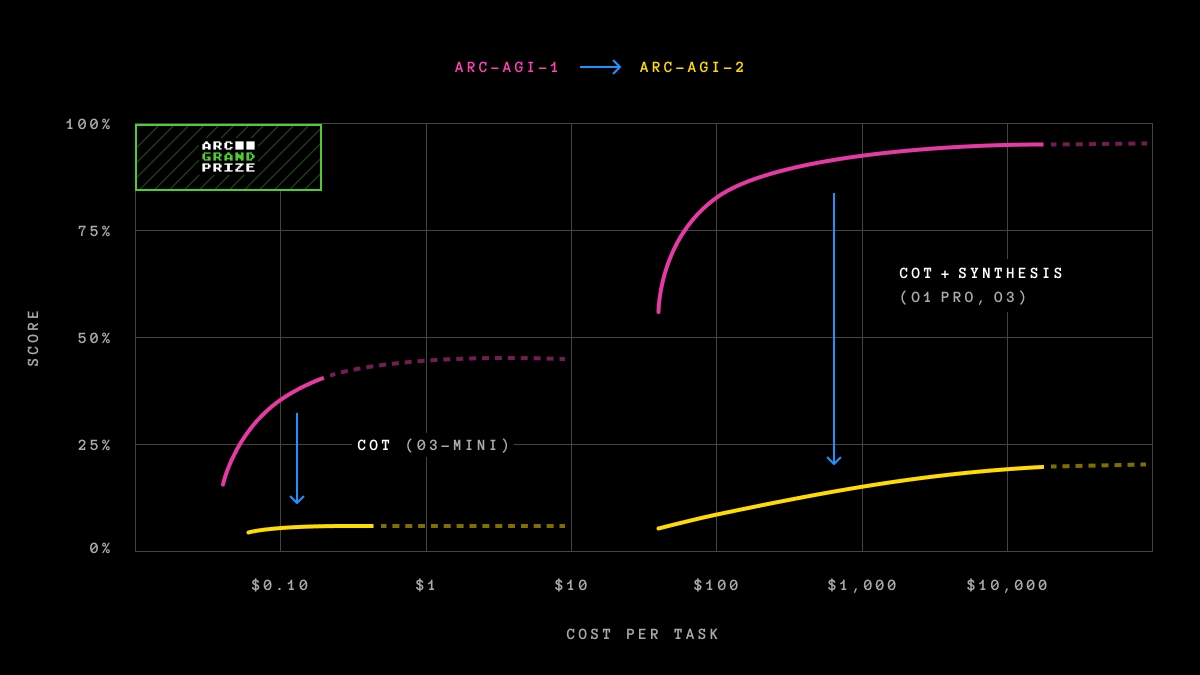
In einigen Fällen fehlen jedoch noch ausführliche Tests oder es handelt sich um Hochrechnungen, so dass die tatsächliche Leistung insbesondere von Modellen wie o3-high höher sein könnte.
Effizienz wird zum entscheidenden Faktor
Eine wichtige Neuerung der ARC-AGI-2 ist die Einführung einer Effizienzmetrik. In Zukunft wird nicht nur die Problemlösungsfähigkeit bewertet, sondern auch die Effizienz, mit der diese Fähigkeit eingesetzt wird. Als erste Metrik wird der Kostenfaktor verwendet, da dieser einen direkten Vergleich zwischen menschlicher und KI-Leistung ermöglicht.
"Wir wissen, dass eine Brute-Force-Suche irgendwann ARC-AGI lösen könnte (mit unbegrenzten Ressourcen und unbegrenzter Zeit). Das wäre keine echte Intelligenz", so die ARC Prize Foundation. "Intelligenz bedeutet, die Lösung effizient zu finden, nicht erschöpfend." Der Grund dafür ist wahrscheinlich der Erfolg von o3 in seinem Vorgänger: Das Modell hatte den Benchmark fast gelöst, dafür aber auf extrem viele parallel generierte Lösungen gesetzt.
Während ein menschliches Expertenpanel 100 Prozent der Aufgaben zu Kosten von rund 17 Dollar pro Aufgabe löst, benötigt das o3-low-Modell von OpenAI für seine mageren vier Prozent rund 200 Dollar pro Aufgabe. Dies zeigt die enorme Effizienzlücke zwischen menschlicher und künstlicher Intelligenz.
ARC Prize 2025 mit einer Million Dollar Preisgeld startet diese Woche
Parallel zur Veröffentlichung von ARC-AGI-2 startet der ARC Prize 2025 Wettbewerb mit einem Gesamtpreisgeld von 1 Million Dollar. Der Hauptpreis in Höhe von 700.000 Dollar wird für das Erreichen von 85 Prozent auf dem privaten Evaluierungsset vergeben. Zusätzlich gibt es 125.000 Dollar an garantierten Fortschrittspreisen und weitere 175.000 Dollar an noch nicht angekündigten Preisen.
Der Wettbewerb findet auf Kaggle statt und läuft von März bis November 2025. Im Gegensatz zum öffentlichen Leaderboard auf arcprize.org beschränken die Regeln von Kaggle die Teilnehmer auf etwa 50 Dollar Rechenleistung pro Einreichung und verbieten die Nutzung von Internet-APIs.
Der 2019 eingeführte ARC-AGI-1-Benchmark galt lange als einer der härtesten Tests für KI - und war wahrscheinlich der einzige Benchmark, der ein starkes Signal für den wohl wichtigsten Paradigmenwechsel in der KI der letzten Jahre lieferte: das Aufkommen von Reasoning-Modellen. Trotz des Namens sind jedoch weder die erste noch die neue Variante des Benchmarks ein Indikator für das Erreichen von AGI - beide Benchmarks können nach Aussage des Teams, das sie entwickelt hat, auch ohne das Erreichen einer AGI gelöst werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.