Auch neue LLMs wie GPT-5.2 und Claude 4.6 verlieren bei langen Chats massiv an Leistung
Auch die neue Generation großer Sprachmodelle (LLMs) ab GPT-5 hat nach wie vor Probleme, wenn Aufgaben über mehrere Gesprächsrunden verteilt werden. Forscher Philippe Laban und sein Team testeten aktuelle Modelle in sechs Aufgaben: Code, Datenbanken, Aktionen, Daten-zu-Text, Mathematik und Zusammenfassungen. Ergebnis: Die Leistung sinkt deutlich, wenn Informationen über mehrere Nachrichten verteilt (sharded) statt in einer einzigen Anfrage (concat) gegeben werden.
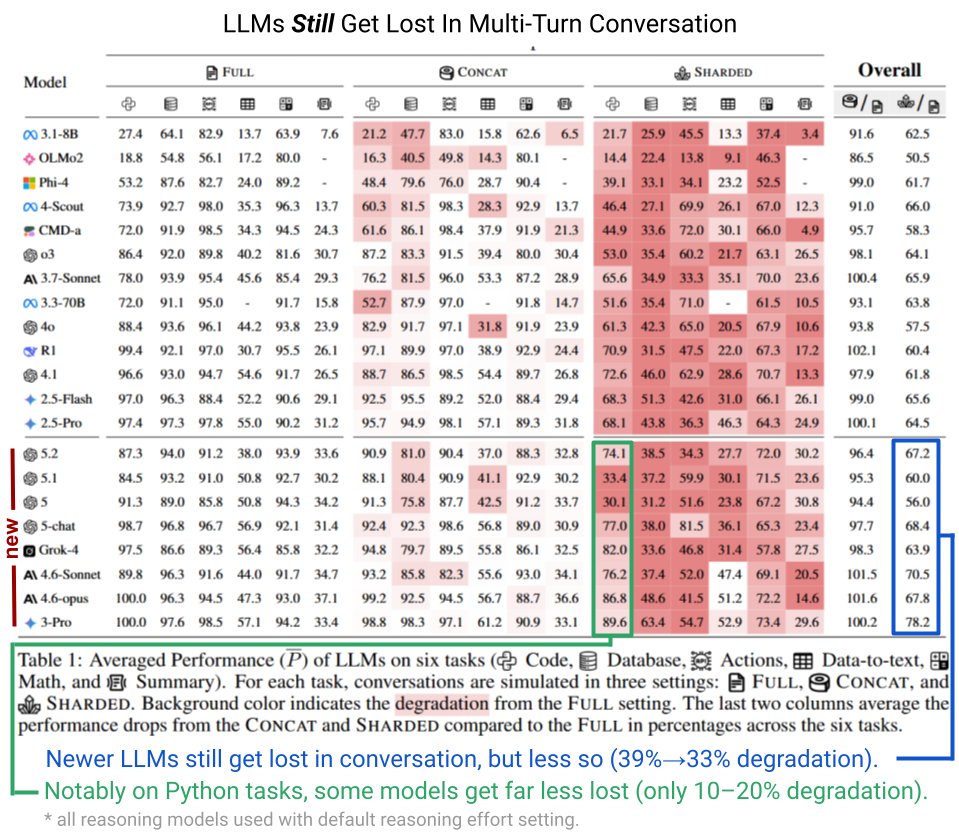
Neuere Modelle schneiden zwar etwas besser ab – sie verlieren im Schnitt 33 statt zuvor 39 Prozent ihrer Leistung –, doch das Problem bleibt bestehen. Verbesserungen zeigten sich primär bei Python-Programmieraufgaben, wo einige Modelle nur noch 10 bis 20 Prozent Leistung einbüßten. Die Tests nutzten einfache, unkomplizierte Nutzersimulationen. Laban vermutet, dass der Verlust noch größer ausfallen könnte, wenn Nutzer etwa mitten im Gespräch ihre Meinung ändern.
Die ursprüngliche Studie zeigte, dass technische Anpassungen wie niedrigere Temperaturwerte das Problem nicht lösen. Die Forscher empfehlen daher: Bei Problemen lieber ein neues Gespräch starten und am Ende einer Sitzung eine Zusammenfassung aller Anforderungen erstellen lassen. Mehr "Context-Engineering"-Strategien gibt’s im heise KI Pro Webinar zum Thema.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren