Jonathan ist Technikjournalist und beschäftigt sich stark mit Consumer Electronics. Er erklärt seinen Mitmenschen, wie KI bereits heute nutzbar ist und wie sie im Alltag unterstützen kann.
Wie China 2025 mit Open-Weight-Modellen an die KI-Spitze rückte
Chinesische Open-Weight-KI erobert die Welt: Laut Stanford-Analyse haben Modelle aus China ihre US-Pendants bei Verbreitung und Adoption bereits überholt. Doch mit dem Erfolg wachsen auch geopolitische und sicherheitspolitische Risiken.
KI-Agenten können Benchmarks "hacken": Warum Testergebnisse oft wenig aussagen
Benchmarks sollen objektiv messen, wie gut KI-Modelle sind. Doch laut einer Analyse von Epoch AI hängen die Ergebnisse stark davon ab, wie genau der Test durchgeführt wird. Die Forschungsorganisation identifiziert zahlreiche Variablen, die selten offengelegt werden, aber erheblichen Einfluss haben.
Urheberrechtlich geschützte Romane lassen sich laut Studien fast komplett aus KI-Sprachmodellen abrufen
Harry Potter, Herr der Ringe, Game of Thrones: Forscher extrahieren ganze Romane aus kommerziellen Sprachmodellen. Zwei der vier getesteten Systeme leisteten nicht einmal Widerstand. Die Ergebnisse könnten laufende Urheberrechtsklagen gegen KI-Unternehmen beeinflussen.
ByteDance gibt KI-Videomodellen ein Gedächtnis für längere Geschichten
ByteDance löst ein hartnäckiges Problem der KI-Videogenerierung: Charaktere, die von Szene zu Szene ihr Aussehen wechseln. Das neue System StoryMem merkt sich, wie Figuren und Umgebungen aussehen sollen und hält sie über eine ganze Geschichte hinweg stabil.
Forscherteam will unlogische KI-Grübelei mit neuen "Laws of Reasoning" beenden
Wenn ich bei einer einfachen Aufgabe länger grübeln würde als bei einer komplexen – und dabei auch noch schlechter abschneiden würde – würde mein Chef wohl Fragen stellen. Genau das passiert aber offenbar bei aktuellen Reasoning-Modellen wie Deepseek-R1. Ein Forscherteam hat sich das Problem nun genauer angeschaut und theoretische Gesetze formuliert, die beschreiben, wie KI-Modelle idealerweise „denken“ sollten.
Metas Pixio lernt durch Pixel-Rekonstruktion und übertrifft aufwendigere KI-Modelle
Weniger ist mehr: Metas neues Bildmodell Pixio schlägt komplexere Konkurrenten bei Tiefenschätzung und 3D-Rekonstruktion, obwohl es weniger Parameter hat. Die Trainingsmethode galt eigentlich als überholt.
Metas neues KI-Modell SAM Audio lässt Nutzer Töne in Videos anklicken
Hundegebell aus dem Straßenlärm filtern oder per Mausklick im Video eine Tonquelle isolieren: Mit SAM Audio bringt Meta sein bewährtes visuelles Segmentierungskonzept in die Audiowelt. Das Modell vereinfacht Audio-Bearbeitung durch Text, Klicks oder Zeitmarkierungen. Code und Gewichte sind frei verfügbar.
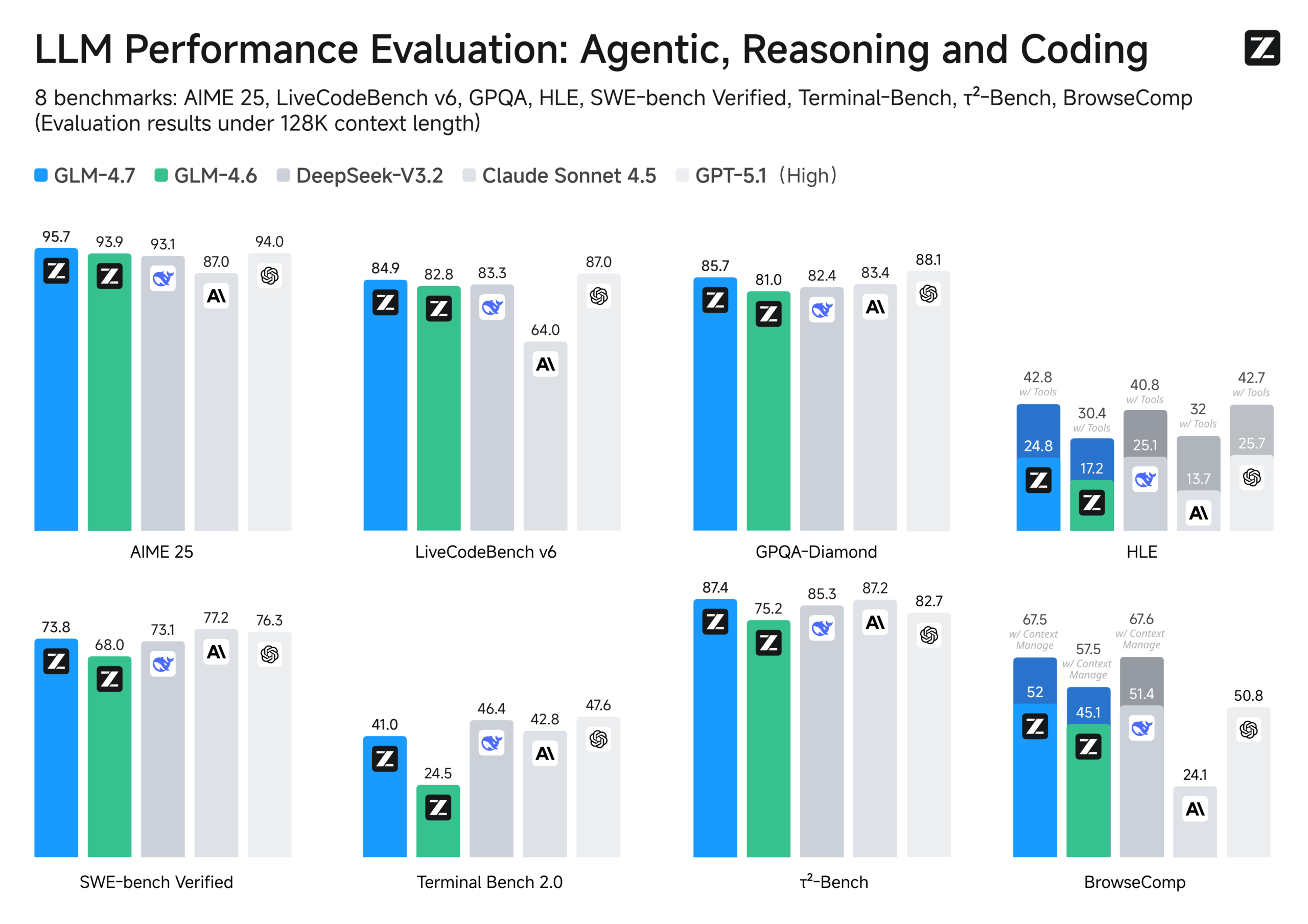
Zhipu AI stellt mit GLM-4.7 ein auf autonomes Programmieren spezialisiertes KI-Modell vor, das dank "Preserved Thinking" Gedankengänge über lange Dialoge speichert. Diese neue Funktion ergänzt das seit GLM-4.5 bekannte "Interleaved Thinking", bei dem die KI vor Aktionen pausiert. Im Vergleich zum Vorgänger GLM-4.6 erzielt das Modell deutliche Leistungssteigerungen, etwa 73,8 Prozent im SWE-bench Verified. Neben reinem Code generiert GLM-4.7 laut Anbieter auch ästhetisch ansprechendere Webseiten und Präsentationen ("Vibe Coding"). Im Blogbeitrag stellt Zhipu einige Webseiten vor, die aus einem einzigen Prompt entstanden sein sollen.
In mehreren Benchmarks wird das Kopf-an-Kopf-Rennen mit kommerziellen, westlichen Anbietern wie OpenAI und Anthropic deutlich.
Das Modell ist über die Z.ai-Plattform, OpenRouter sowie als lokaler Download auf Hugging Face verfügbar und lässt sich direkt in Coding-Tools wie Claude Code integrieren. Z.ai wirbt dabei mit einem Kampfpreis von einem Siebtel der Kosten vergleichbarer Modelle.
Das Qwen-Team von Alibaba Cloud hat zwei neue KI-Modelle veröffentlicht, die Stimmen per Textbefehl entwerfen oder klonen. Das Modell Qwen3-TTS-VD-Flash erlaubt es Nutzern, Stimmen durch detaillierte Beschreibungen zu generieren und dabei Eigenschaften wie Emotionen und Sprechtempo exakt festzulegen, etwa: "Male, middle-aged, booming baritone - hyper-energetic infomercial voice with rapid-fire delivery and exaggerated pitch rises, dripping with salesmanship". Es soll laut Hersteller in Tests besser abschneiden als OpenAIs im Frühjahr eingeführte API für GPT-4o-mini-tts.
Ergänzend kopiert das Modell Qwen3-TTS-VC-Flash Stimmen anhand von nur drei Sekunden Audio-Material und gibt diese in zehn Sprachen, darunter Deutsch, wieder. Qwen gibt an, dass die Fehlerrate dabei geringer ist als bei Elevenlabs oder MiniMax. Die KI verarbeitet auch komplexe Texte und kann sogar Tierstimmen imitieren oder Stimmen aus Aufnahmen extrahieren. Beide Modelle sind über die API von Alibaba Cloud verfügbar. Demos stehen sowohl für das Design- als auch das Klon-Modell auf Hugging Face bereit.