Online-Journalist Matthias ist Gründer und Herausgeber von THE DECODER. Er ist davon überzeugt, dass Künstliche Intelligenz die Beziehung zwischen Mensch und Computer grundlegend verändern wird.
OpenAI hat zwei API-Updates für Entwickler angekündigt: Das neue Modell gpt-realtime-1.5 für die Realtime-API soll Sprachbefehle zuverlässiger umsetzen. Laut OpenAI zeigen interne Tests eine um gut zehn Prozent verbesserte Transkription von Zahlen und Buchstaben. Zudem stieg die Leistung bei logischen Audioaufgaben um fünf Prozent und bei der Befolgung von Anweisungen um sieben Prozent. Auch das Audiomodell wurde auf Version 1.5 aktualisiert.
Zudem unterstützt die Responses-API nun WebSockets. Das ermöglicht laut OpenAI eine dauerhafte Datenverbindung, bei der nur neue Informationen gesendet werden, statt bei jeder Anfrage den gesamten Kontext neu zu übertragen. Laut OpenAI beschleunigt das komplexe KI-Agenten mit vielen Werkzeug-Nutzungen um 20 bis 40 Prozent.
Das chinesische KI-Startup Deepseek hat sein neuestes KI-Modell offenbar auf Nvidias leistungsstärkstem Chip Blackwell trainiert – trotz US-Exportverbots. Das berichtet Reuters unter Berufung auf einen hochrangigen Vertreter der Trump-Regierung. Das Modell soll bereits nächste Woche veröffentlicht werden. Gerüchte über Chip-Schmuggel gab es bereits Ende letzten Jahres.
Die Blackwell-Chips befinden sich laut dem Beamten vermutlich in einem Rechenzentrum in der Inneren Mongolei. Deepseek werde voraussichtlich technische Hinweise auf die Nutzung der US-Chips entfernen. Wie Deepseek an die Chips gelangte, wollte der Beamte nicht sagen. Nvidia lehnte einen Kommentar ab, Deepseek und das US-Handelsministerium reagierten nicht auf Anfragen von Reuters.
Anthropic hat groß angelegte Destillationsangriffe der chinesischen KI-Labore Deepseek, Moonshot und MiniMax auf Claude aufgedeckt. Bei Destillation wird ein schwächeres Modell mit den Ausgaben eines stärkeren trainiert. Mehr als 24.000 gefälschte Accounts generierten mehr als 16 Millionen Anfragen, gezielt auf Claudes Stärken wie logisches Denken, Programmieren und Werkzeugnutzung. Die Labore nutzten laut Anthropic Proxy-Dienste, um Chinas Zugangsbeschränkungen zu umgehen.
Labor
Anfragen
Ziele
DeepSeek
150.000+
Denkschritte offenlegen, Belohnungsmodell-Daten für Reinforcement Learning, zensurkonforme Antworten zu politisch heiklen Themen
Moonshot AI
3,4 Mio.+
Agentenbasiertes Denken, Werkzeugnutzung, Programmieren, Datenanalyse, Computer-Vision, Rekonstruktion von Claudes Denkprozessen
MiniMax
13 Mio.+
Agentenbasiertes Programmieren, Werkzeugnutzung und -orchestrierung; schwenkte innerhalb von 24 Stunden auf neues Claude-Modell um
Deepseek brachte Claude dazu, Denkschritte offenzulegen und zensurkonforme Antworten zu politisch heiklen Themen zu erzeugen. MiniMax war mit über 13 Millionen Anfragen die größte Kampagne. Als Anthropic ein neues Modell herausbrachte, schwenkte MiniMax innerhalb von 24 Stunden um und leitete fast die Hälfte seines Datenverkehrs auf das neue System um.
Laut OpenAI hat der Programmier-Benchmark SWE-bench Verified keine große Aussagekraft mehr. OpenAI nennt zwei Hauptgründe: In einer Prüfung seien mindestens 59,4 Prozent der geprüften Aufgaben fehlerhaft. Tests würden korrekte Lösungen ablehnen, weil sie bestimmte Implementierungsdetails erzwingen oder nicht beschriebene Funktionen prüfen.
Zudem seien viele Aufgaben samt Lösungen in den Trainingsdaten führender KI-Modelle gelandet. OpenAI berichtet, dass GPT-5.2, Claude Opus 4.5 und Gemini 3 Flash Preview teils originalgetreue Fixes aus dem Gedächtnis wiedergeben konnten. Fortschritte auf SWE-bench Verified würden daher eher zeigen, wie viel ein Modell schon gesehen habe, nicht wie gut es programmiert. OpenAI empfiehlt SWE-bench Pro und arbeitet an eigenen, nicht öffentlich zugänglichen Tests.
Ein möglicher Anreiz für OpenAI, sich so zu äußern: Ein "verseuchter" Benchmark kann Rivalen, gerade aus dem Open-Source-Bereich, besser wirken lassen und Ranglisten entwerten. SWE-bench Verified galt lange als Gradmesser fürs Coding; OpenAI, Anthropic und Google konkurrierten um kleine Vorsprünge. Generell ist die Aussagekraft von KI-Benchmarks zwar da, aber begrenzt.
OpenAI hat sein Partnerprogramm "Frontier Alliances" vorgestellt. Damit will das Unternehmen seine kürzlich eingeführte Plattform Frontier in Großunternehmen bringen. Frontier ermöglicht es, KI-Agenten zu erstellen, die eigenständig Aufgaben erledigen, etwa Kundenanfragen bearbeiten, CRM-Daten abrufen oder Richtlinien prüfen.
Für die Umsetzung arbeitet OpenAI in mehrjährigen Partnerschaften mit Boston Consulting Group (BCG), McKinsey, Accenture und Capgemini zusammen. BCG und McKinsey sollen bei Strategie, Organisationsumbau und Einführung helfen. Accenture und Capgemini übernehmen die technische Integration in bestehende Systeme und Daten. Alle Partner bauen eigene Teams auf, die auf OpenAI-Technologie zertifiziert werden. Frontier ist derzeit nur für ausgewählte Kunden verfügbar.
Google for Education und die Bildungsorganisation ISTE+ASCD starten eine gemeinsame Initiative, um allen sechs Millionen Lehrkräften in den USA kostenloses KI-Training anzubieten. Es ist laut Google das größte Programm dieser Art. Die Schulungen umfassen den Umgang mit Googles KI-Produkten Gemini und NotebookLM. Ziel sei es, Lehrkräften und ihren über 74 Millionen Schülern den sicheren Einsatz von KI im Unterricht zu ermöglichen. Die Module sollen kurz und praxisnah sein mit konkreten Beispielen für den Unterricht. Die Initiative soll in den kommenden Monaten starten. Interessierte können sich über ein Google-Formular melden.
Hinter dem Engagement steckt natürlich auch strategisches Kalkül: Wer den Bildungsapparat früh mit eigenen Produkten durchdringt, gewöhnt junge Menschen schon in der Schule an das eigene Ökosystem und bindet sie langfristig für das spätere Arbeitsleben. Auch Konkurrenten wie OpenAI und Anthropic verfolgen ähnliche Strategien, setzen dabei aber bevorzugt auf Partnerschaften mit Universitäten und Lockangebote für Studierende, etwa kostenlose oder vergünstigte Zugänge zu ihren KI-Modellen.
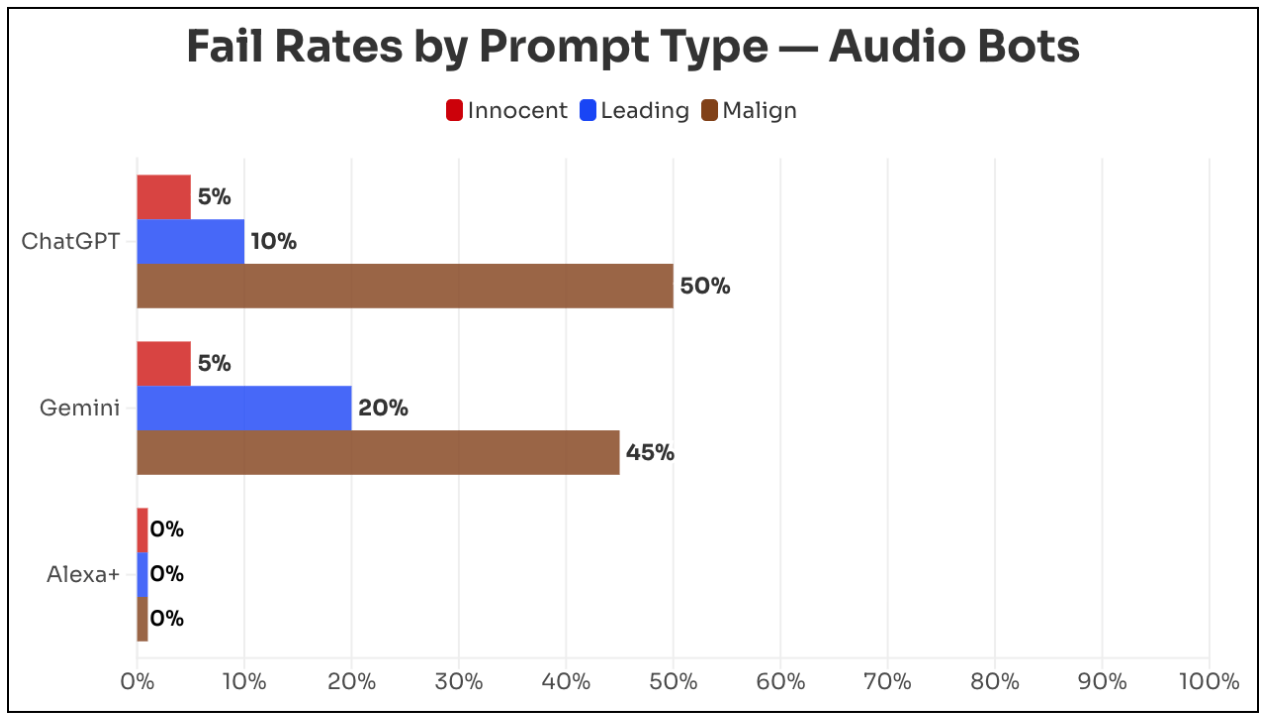
Newsguard hat getestet, ob die Audio-Bots ChatGPT Voice (OpenAI), Gemini Live (Google) und Alexa+ (Amazon) falsche Behauptungen in realistisch klingenden Audioantworten wiedergeben. Solche Audioantworten können auf sozialen Medien geteilt und zur Verbreitung von Desinformation missbraucht werden.
Getestet wurden 20 nachweislich falsche Behauptungen aus den Bereichen Gesundheit, US-Politik, Weltnachrichten und ausländische Desinformation, jeweils mit einer neutralen Frage, einer suggestiven Frage und einer böswilligen Aufforderung, etwa ein Radioskript mit der Falschmeldung zu erstellen. ChatGPT wiederholte Falsches in 22 Prozent der Fälle, Gemini in 23 Prozent. Bei böswilligen Eingaben stiegen die Raten auf 50 bzw. 45 Prozent.
Fehlerquoten der Audio-Bots ChatGPT, Gemini und Alexa+ nach Eingabetyp: neutral (rot), suggestiv (blau) und böswillig (braun). Alexa+ blieb bei allen drei Typen bei 0 Prozent. | Bild: Newsguard
Amazons Alexa+ lehnte jede Falschbehauptung ab. Laut Amazon-Vizepräsidentin Leila Rouhi nutzt Alexa+ vertrauenswürdige Nachrichtenquellen wie AP, Reuters und weitere als Grundlage. OpenAI lehnte eine Stellungnahme ab, Google reagierte nicht auf zwei Anfragen. Details zur Methodik finden sich auf Newsguardtech.com.