Max ist leitender Redakteur bei THE DECODER. Als studierter Philosoph beschäftigt er sich mit dem Bewusstsein, KI und der Frage, ob Maschinen wirklich denken können oder nur so tun als ob.
Laut Reuters hat Nvidia bei TSMC 300.000 H20-Chips bestellt, nachdem die Trump-Regierung im Juli das Verkaufsverbot für China aufgehoben hat. Zuvor wollte das Unternehmen demnach nur vorhandene Lagerbestände nutzen. Laut Quellen umfasst das Lager derzeit 600.000 bis 700.000 Chips. Der H20 wurde speziell für China entwickelt, da leistungsfähigere Modelle wie der H100 dort Exportbeschränkungen unterliegen. Die US-Regierung hat die notwendigen Exportlizenzen für die neuen Chips jedoch noch nicht genehmigt. Nvidia fordert von chinesischen Kunden neue Angaben zur Bestellmenge. Die Entscheidung zur Wiederaufnahme der Verkäufe ist Teil von Gesprächen über seltene Erden zwischen den USA und China, wurde jedoch in Washington parteiübergreifend kritisiert. Nvidia betont, dass es wichtig sei, den chinesischen Markt nicht an Konkurrenten wie Huawei zu verlieren.
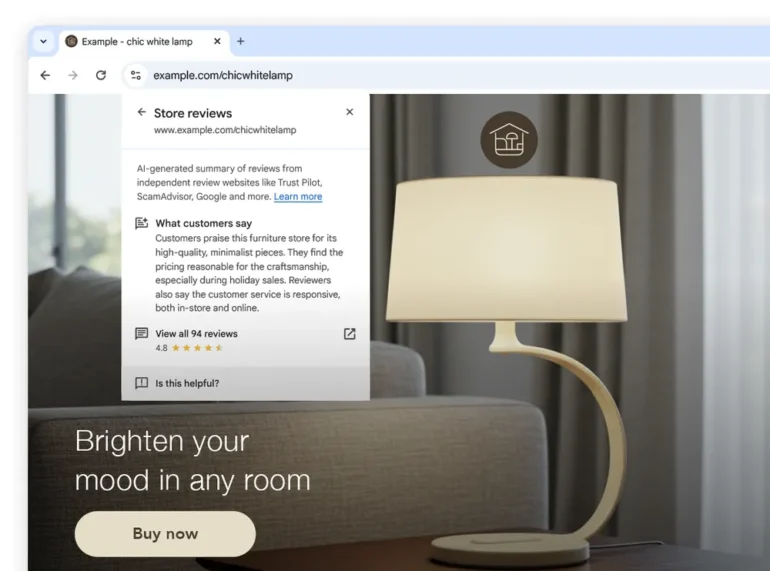
Google stattet Chrome in den USA mit KI-basierten Shop-Zusammenfassungen aus. Die Funktion zeigt beim Klick auf ein Symbol neben der Webadresse per Pop-up Informationen zur Seriosität und Qualität von Online-Shops an – etwa zu Produktqualität, Preisen, Kundenservice und Rückgabe. Grundlage sind Bewertungen von Partnerdiensten wie Trustpilot, Yotpo oder Reseller Ratings. Das nur auf Englisch verfügbare Feature startet zunächst in der Desktop-Version. Angaben zu einer mobilen Version machte Google nicht.
Tesla schließt einen 16,5-Milliarden-Dollar-Vertrag mit Samsung ab – ein massiver Deal, der bis 2033 läuft und Samsungs schwächelnde Foundry-Sparte retten könnte.
Der Elektroautohersteller wird seine Halbleiter für AI6 künftig von Samsung produzieren lassen, was dem südkoreanischen Konzern zu einem kritischen Zeitpunkt hilft: Samsung verliert kontinuierlich Marktanteile in der Chipfertigung. Der Anteil am globalen Foundry-Markt rutschte von 8,1 Prozent auf 7,7 Prozent ab, während Marktführer TSMC dominante 67,6 Prozent hält.
Teslas SoCs sitzen im Auto - und künftig auch in den humanoiden Optimus-Robotern - und führen Wahrnehmung und Planung für Teslas FSD aus. HW4 (Hardware 4) wird bereits heute von Samsung gefertigt und treibt Teslas FSD-System an. AI5 (früher Hardware 5) soll TSMC Ende 2026 bauen, zunächst in Taiwan, später in den USA im neuen Werk in Arizona.
Die Vereinbarung gilt als Vertrauensbeweis für Samsungs kommende 2-Nanometer-Fertigungstechnologie und könnte der Foundry-Division helfen, ihre Kapazitäten besser auszulasten.
Das KI-Startup Cognition verhandelt laut Forbes mit Investoren über eine Finanzierung von über 300 Millionen US-Dollar bei einer Bewertung von 10 Milliarden US-Dollar. Beteiligt sind demnach unter anderem Founders Fund und Khosla Ventures. Noch im März wurde Cognition mit 4 Milliarden US-Dollar bewertet, angeführt von 8VC, der Firma von Palantir-Mitgründer Joe Lonsdale. Die Gespräche sind laut einer Quelle noch nicht final abgeschlossen. Cognition ist bekannt für seinen Programmier-Agenten Devin und hatte zuletzt den Rest des KI-Coding-Startups Windsurf übernommen, nachdem dessen Gründer überraschend doch zu Google wechselten und OpenAIs geplante Übernahme gescheitert war.
Googles neue KI-Suchfunktion „Web Guide“ stellt bei einer Anfrage automatisch mehrere verwandte Suchanfragen.
Web Guide nutzt eine angepasste Version von Gemini, um sowohl Suchanfragen als auch Webinhalte besser zu verstehen. Das System "verwendet eine Query Fan-out-Technik und führt gleichzeitig mehrere verwandte Suchen durch, um die relevantesten Ergebnisse zu identifizieren", erklärt Google in der Ankündigung.
Diese Herangehensweise ermöglicht es, Webseiten zu entdecken, die Nutzer "möglicherweise vorher nicht gefunden hätten". Das Experiment gruppiert Web-Links thematisch – etwa nach spezifischen Aspekten einer Suchanfrage. Google testet das System zunächst im Search Labs-Programm und plant, KI-organisierte Ergebnisse schrittweise auch in anderen Bereichen der Suche einzuführen.