Google AVIS beantwortet Fragen zu Bildern, deren Informationen nicht leicht zugänglich sind, etwa das Gründungsdatum einer Fluggesellschaft oder das Baujahr eines Autos.
Fortschritte in großen Sprachmodellen und ihre Verknüpfung mit Computer-Vision-Modellen haben multimodale Fähigkeiten für Aufgaben wie Bildunterschriften und die Beantwortung visueller Fragen ermöglicht. Diese visuellen Sprachmodelle (VLMs) haben jedoch immer noch Probleme mit komplexen visuellen Schlussfolgerungen in der realen Welt, die externes Wissen erfordern - "visuelle Informationssuche" genannt.

Um diese Einschränkung zu überwinden, haben Google-Forschende eine neue Methode namens AVIS entwickelt, die Googles PALM mit Werkzeugen für Computer Vision, Websuche und Bildsuche integriert.
Googles AVIS lernt von Menschen
Im Gegensatz zu früheren Systemen, die große Sprachmodelle mit Werkzeugen in einem starren zweistufigen Prozess kombinieren, nutzt AVIS diese flexibler für die Planung und Durchführung der Suche. So kann das Modell etwa Aktionen auf der Grundlage von Echtzeit-Feedback anpassen.
AVIS besteht aus drei Hauptkomponenten:
- Einen Planer, der die nächste Aktion (API-Aufruf und Abfrage) via Sprachmodell bestimmt
- Ein Arbeitsspeicher, der Informationen aus vergangenen API-Ausführungen speichert
- Ein Reasoner, der API-Ausgaben via Sprachmodell verarbeitet, um nützliche Informationen zu extrahieren
Der Planer und der Reasoner werden iterativ verwendet, wobei der Planer auf der Grundlage des aktualisierten Status des Reasoners über das nächste Werkzeug und die nächste Abfrage entscheidet. Dieser Prozess wird so lange fortgesetzt, bis der Reasoner feststellt, dass genügend Informationen vorhanden sind, um die endgültige Antwort zu geben.
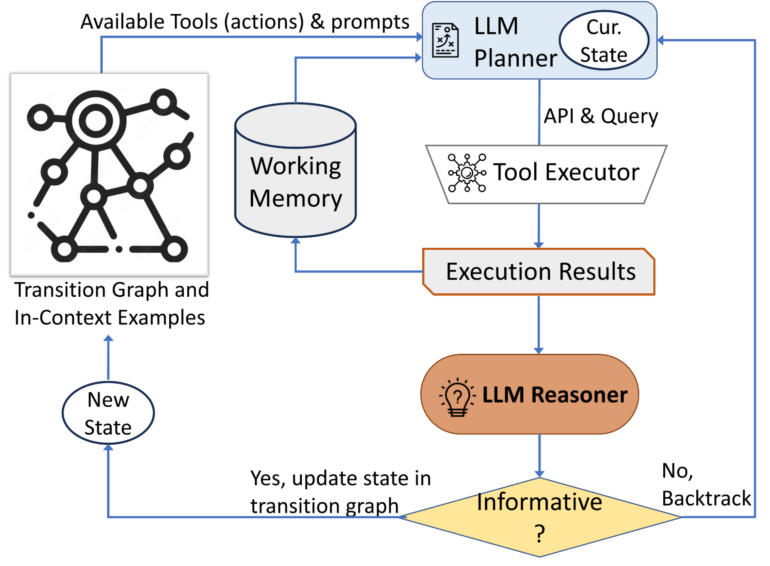
Drei Arten von Werkzeugen sind ebenfalls integriert:
- Computer-Vision-Tools zum Extrahieren visueller Informationen aus Bildern
- Ein Web-Suchwerkzeug zum Abrufen von Wissen und Fakten in der offenen Welt
- Ein Bildsuchwerkzeug zum Lesen relevanter Informationen aus Metadaten, die mit visuell ähnlichen Bildern verbunden sind
Um herauszufinden, wie diese Fähigkeiten am besten genutzt werden können, führten die Forschenden eine Studie durch, bei der Personen dieselben Fragen mit denselben Hilfsmitteln beantworteten. Die Studie identifizierte gemeinsame Handlungsabläufe, an denen sich AVIS in seinem Verhalten orientiert.
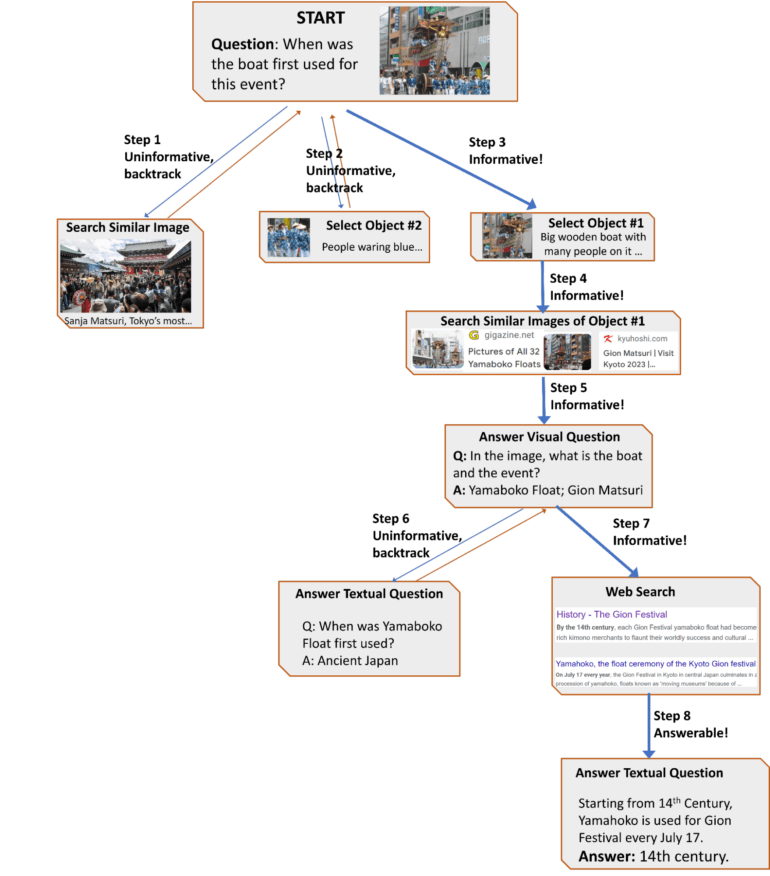
AVIS erreicht State-of-the-Art ohne Finetuning
Im Infoseek-Datensatz erreichte AVIS eine Genauigkeit von 50,7 % und übertraf damit deutlich fein abgestimmte visuelle Sprachmodelle wie OFA und PaLI. Auf dem OK-VQA-Datensatz erreichte AVIS mit wenigen Beispielen eine Genauigkeit von 60,2 % und übertraf damit die meisten früheren Arbeiten und näherte sich laut Google fein abgestimmten Modellen an.

In Zukunft will das Team sein Framework auf andere logische Aufgaben anwenden und herausfinden, ob diese Fähigkeiten auch von einfacheren Sprachmodellen erreicht werden können, da das verwendete PALM-Modell mit 540 Milliarden Parametern sehr rechenintensiv ist.