Baidus neues ERNIE-Modell bearbeitet Bilder während des Denkprozesses

Baidu hat mit ERNIE-4.5-VL-28B-A3B-Thinking ein Reasoning-Model veröffentlicht, das Bilder während des Denkprozesses ver- und bearbeiten kann, etwa einzoomen, um Text besser lesen zu können.
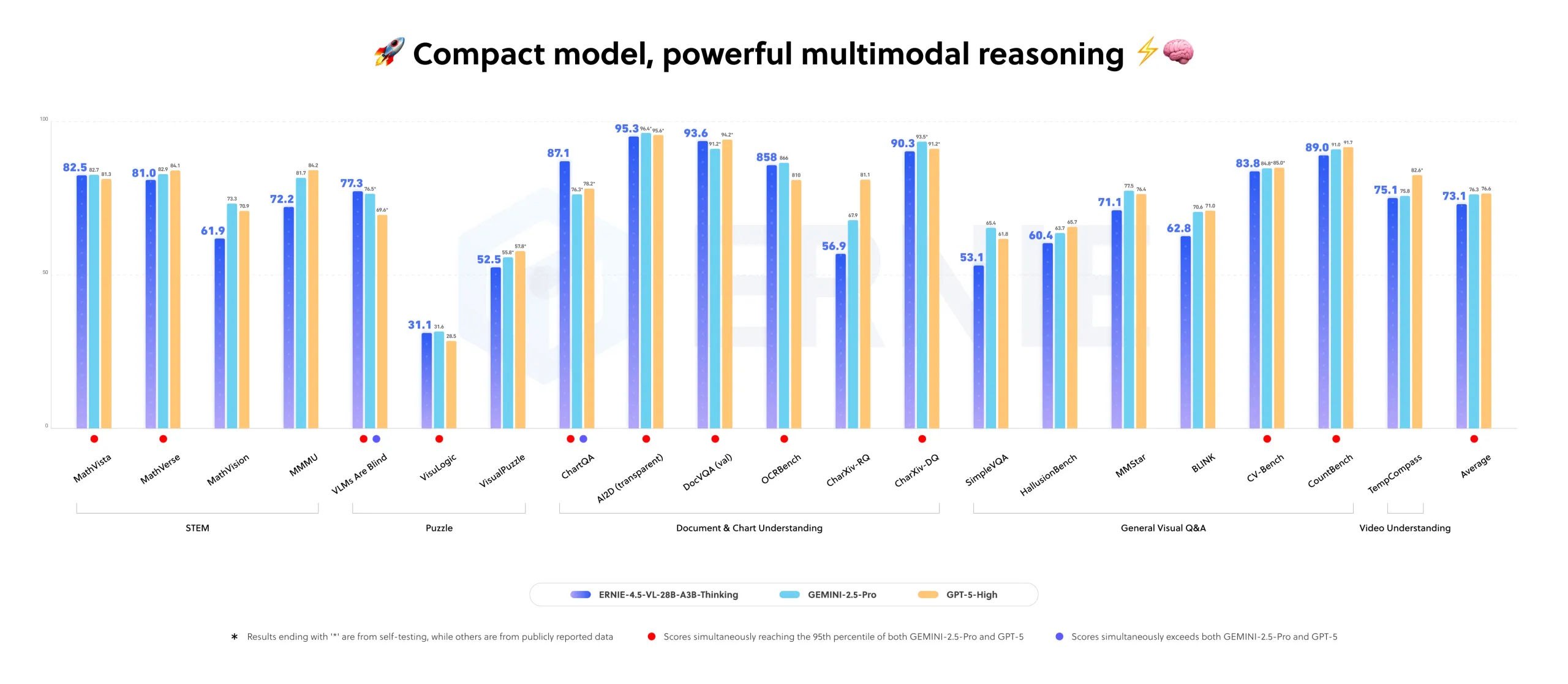
Nach Angaben des chinesischen Suchmaschinenkonzerns übertrifft es weit größere kommerzielle Modelle wie Google Gemini 2.5 Pro und OpenAI GPT-5-High in einigen Multimodal-Aufgaben. Das Modell nutzt wie auch die vorherige Version aus der ERNIE-4.5-Familiie nur drei Milliarden aktive Parameter bei insgesamt 28 Milliarden Parametern durch eine spezielle Routing-Architektur.
Das Modell läuft auf einer einzigen 80-GB-GPU wie der Nvidia A100 und wurde unter der Apache-2.0-Lizenz veröffentlicht, was kommerzielle Nutzung ohne Einschränkungen erlaubt. Unabhängige Tests der Leistungsangaben stehen noch aus.
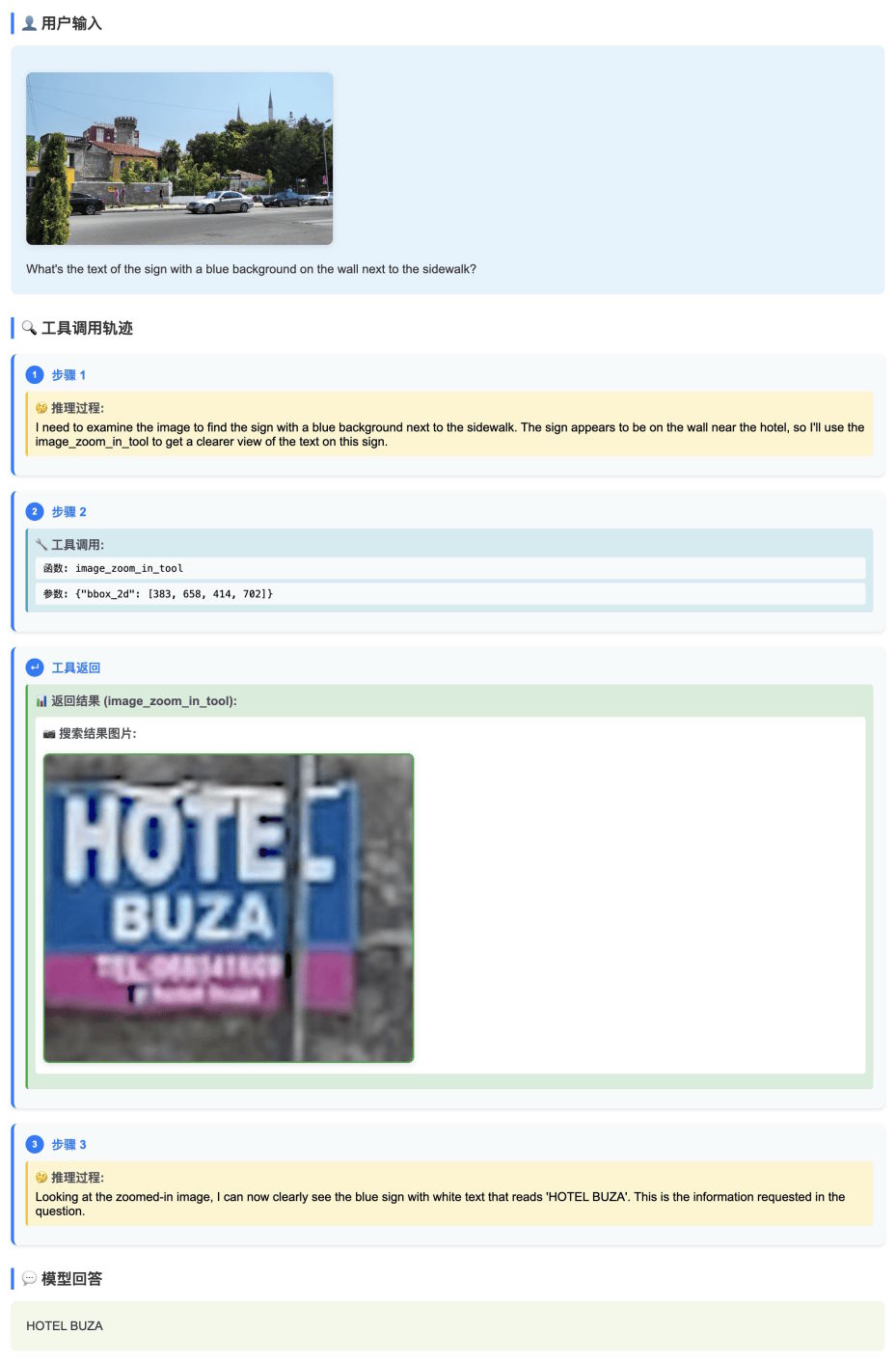
Mit "Thinking with Images" kann das System Bilder dynamisch zuschneiden, um Details zu analysieren. Baidu zeigte dies am Beispiel eines blauen Schilds, bei dem das Modell automatisch heranzoomte und den Text darauf erkannte.
In weiteren Tests identifizierte das System Personen in Bildern und gab deren Position als Koordinaten aus, löste mathematische Aufgaben durch Analyse von Schaltplänen und empfahl anhand von Diagrammen günstige Besuchszeiten.
Bei Videos kann es Untertitel extrahieren und bestimmte Szenen zeitlich zuordnen. Zusätzlich nutzt das Modell externe Werkzeuge wie Bildersuche übers Internet, um unbekannte Gegenstände zu identifizieren.
Bereits im April 2025 hat OpenAI mit den Modellen o3 und o4-mini ähnliche Funktionen eingeführt: Sie integrieren Bilder direkt in ihre interne Argumentationskette und setzen native Werkzeuge wie Zoom, Zuschneiden oder Drehen gezielt zur Lösung visueller Aufgaben ein. Damit setzte OpenAI neue Maßstäbe für agentenähnliches Reasoning und Problemlösen.
Auffällig ist nun, dass diese fortschrittlichen visuellen Reasoning-Funktionen, die bislang proprietären westlichen Modellen vorbehalten waren, nur wenige Monate nach ihrem Debüt nun auch in Open-Source-Modellen aus China verfügbar sind.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.