BALROG: Spielesammlung deckt systematische Schwächen von KI-Systemen auf

Forscher haben eine Testumgebung entwickelt, die KI-Systeme in Spielen auf die Probe stellt. Die Ergebnisse zeigen: Selbst führende Modelle scheitern an anspruchsvollen Spielen.
Eine neue Benchmark-Plattform namens BALROG stellt die Fähigkeiten moderner KI-Sprachmodelle auf eine harte Probe. Wie die Entwickler der Plattform berichten, können damit sowohl große Sprachmodelle (LLMs) als auch visuelle Sprachmodelle (VLMs) in einer Vielzahl von Spielumgebungen getestet werden.
Die Testumgebungen reichen laut den Forschern von simplen Aufgaben, die Menschen in Sekunden lösen können, bis hin zu hochkomplexen Spielen wie dem "NetHack Learning Environment", das selbst erfahrene Spieler erst nach jahrelangem Training meistern.
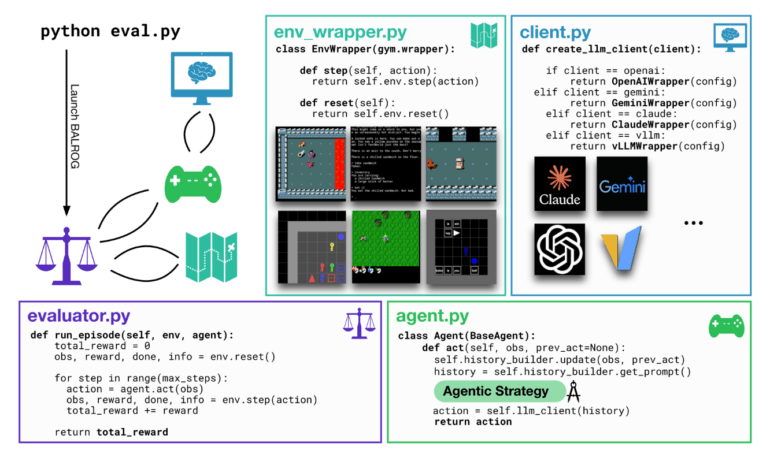
Für die Tests wurden führende Open-Source- und kommerzielle Sprachmodelle wie GPT-4, Claude 3.5 und Llama 3.1 eingesetzt. Die Modelle mussten sich in verschiedenen Szenarien bewähren - von Textadventures über Rätselspiele bis hin zu strategischen Rollenspielen.
GPT-4o bisher stärkstes Modell
Die Ergebnisse des BALROG-Benchmarks zeigen deutliche Grenzen aktueller KI-Sprachmodelle auf. Selbst Spitzenreiter wie GPT-4o von OpenAI erreichten im Durchschnitt nur 32 Prozent der möglichen Punktzahl über alle getesteten Spiele hinweg. Bei besonders komplexen Spielen wie NetHack, die langfristige Planung und Anpassungsfähigkeit erfordern, scheiterten alle Modelle fast vollständig - keines kam über 1,5 Prozent Spielfortschritt hinaus.
In der einfacheren Navigation von BabyAI erreichte der Spitzenreiter GPT-4o immerhin 78 Prozent Erfolgsrate. Doch schon bei Crafter, einem Minecraft-inspirierten Spiel, das Ressourcenmanagement erfordert, kam auch GPT-4o nur auf 33 Prozent Fortschritt.
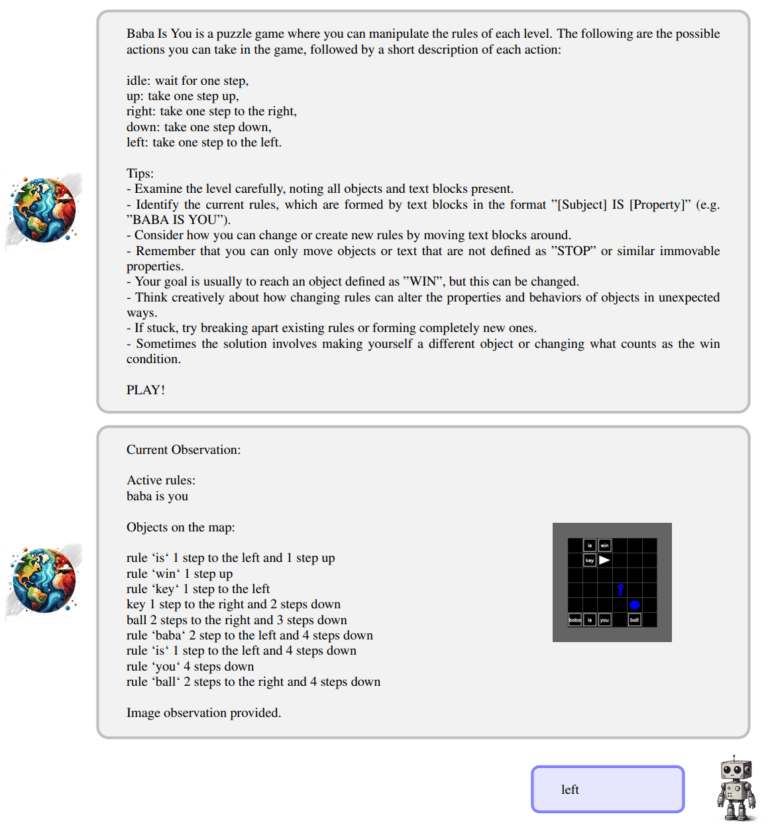
Ähnlich sah es bei Baba Is AI aus, einem Rätselspiel, bei dem die Regeln der Spielwelt manipuliert werden müssen. Hier erreichte überraschenderweise ein anderes Modell, Llama 3.2 von Meta, mit 44 Prozent das beste Ergebnis - GPT-4o kam nur auf 34 Prozent.
In den textbasierten Rätseln von TextWorld schnitten GPT-4o und Claude 3.5 Sonnet mit jeweils knapp über 40 Prozent am besten ab. Alle anderen Modelle blieben unter 20 Prozent.
Die anspruchsvolleren Aufgaben der MiniHack-Umgebung, die Kampf und Erkundung kombinieren, konnte kein einziges Modell im Zero-Shot-Modus lösen. Hier zeigten sich besonders eklatante Schwächen in der Planung und Navigation.
KI scheitert an visueller Entscheidungsfindung
Besonders eklatant waren die Defizite auch im Bereich der bildbasierten Entscheidungsfindung: Wurden den Sprachmodellen visuelle Darstellungen der Spielumgebungen präsentiert, schnitten sie sogar noch schlechter ab als bei rein textbasierten Eingaben.
"Unsere Studie zeigt schwerwiegende Mängel bei der visuellen Entscheidungsfindung auf", so das Team. "Die Modelle haben große Probleme, wenn sie Entscheidungen auf Basis von Bildinformationen treffen müssen."
Die Forscher sehen in ihren Ergebnissen einen wichtigen Beitrag, um die Fähigkeiten und Grenzen aktueller KI-Systeme besser zu verstehen. "Benchmarks wie BALROG sind enorm wichtig, um Stärken und Schwächen bestehender Ansätze aufzuzeigen und die Forschung in die richtigen Bahnen zu lenken", so das Team. Insbesondere die Schwierigkeiten bei der bildbasierten Entscheidungsfindung zeigten dringenden Verbesserungsbedarf auf. Zudem müsse die Fähigkeit der Modelle verbessert werden, abstraktes Wissen auf konkrete Situationen anzuwenden.
Die aktuelle Bestenliste ist auf der BALROG-Projektseite einsehbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.