Bilderkennungsmodell moondream2 beeindruckt trotz geringer Größe

Das Start-up Moondream hat mit moondream2 ein kompaktes Vision Language Model veröffentlicht, das trotz seiner geringen Größe in Benchmarks überzeugt. Das quelloffene Modell könnte den Weg für lokale Bilderkennung auf dem Smartphone ebnen.
Das in Seattle ansässige US-Start-up Moondream hat mit moondream2 im März ein viel beachtetes Vision Language Model (VLM) veröffentlicht. Das bedeutet, dass es neben Text als Eingabe auch Bilder akzeptiert. Basierend auf dieser Eingabe kann das Modell Fragen beantworten, Texte extrahieren (OCR), Dinge zählen oder sie klassifizieren. Seit Veröffentlichung gab es regelmäßig neue Versionen, die in Benchmarks noch ein Stück besser abschnitten als vorherige.
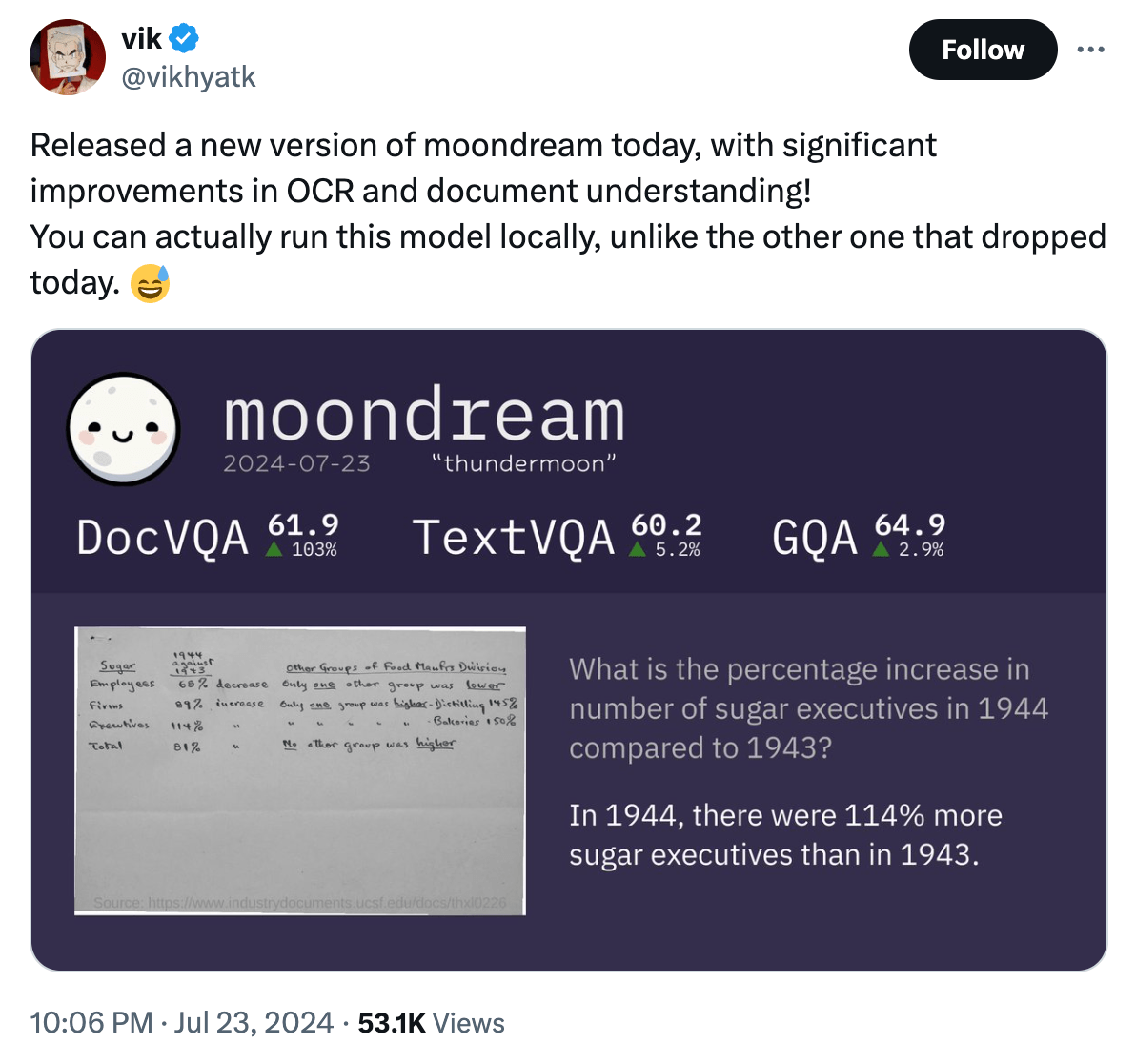
Außergewöhnlich ist moondream2 wegen seiner kompakten Größe: Nur 1,6 Milliarden Parameter zählt das Modell und kann damit nicht nur in der Cloud auf großen Servern, sondern auch lokalen Computern und sogar weniger leistungsfähigen Geräten wie Smartphones oder Einplatinenrechnern ausgeführt werden.
Dabei büßt es trotz der Größe nur wenig Leistungsfähigkeit ein: Es übertrifft in einigen Benchmarks konkurrierende Modelle, die teilweise um ein Vielfaches größer sind. In einem Vergleich von VLMs auf mobilen Endgeräten hoben Forscher:innen die Leistung von moondream2 hervor:
Wir stellen insbesondere fest, dass Moondream2, obwohl es nur etwa 1,7B Parameter hat, in seiner Leistung mit den 7B-Modellen durchaus vergleichbar ist. Lediglich bei SQA, dem einzigen Datensatz, der neben dem Bild und den Fragen einen verwandten Kontext bietet, damit die Modelle die Fragen effektiv beantworten können, fällt es zurück. Dies könnte darauf hinweisen, dass selbst die stärksten kleineren Modelle nicht in der Lage sind, den Kontext zu verstehen.
Murthy et al. im Paper "MobileAIBench: Benchmarking LLMs and LMMs for On-Device Use Cases"
Laut Entwickler Vikhyat Korrapati baut es unter anderem auf Modellen wie SigLIP, Microsofts Phi-1.5 und dem LLaVA-Trainingsdatensatz auf.
moondream2 wird quelloffen entwickelt und steht kostenlos auf GitHub zum Download oder in einer Demo auf Hugging Face bereit. Auf der Coding-Plattform hat es gemessen an mehr als 5.000 Stern-Bewertungen für großes Aufsehen in der Entwickler:innen-Community gesorgt.
Millionen-Investment in Start-up
Dieser Erfolg rief anscheinend auch Investor:innen auf den Plan: In einer Pre-Seed-Finanzierungsrunde, angeführt von Felicis Ventures, Microsofts M12 GitHub Fund und Ascend, sammelten die Betreiber:innen kürzlich 4,5 Millionen US-Dollar. An der Spitze des wachsenden Unternehmens Moondream steht CEO Jay Allen, der zuvor viele Jahre bei Amazon Web Services tätig war.
Moondream2 fügt sich ein in eine Reihe von spezialisierten und optimierten Open-Source-Modellen, die ähnliche Leistung wie größere, ältere Modelle erbringen, jedoch wenig Ressourcen für ihre Ausführung benötigen. Mit GOT präsentierten Forschenden vor einigen Wochen ein auf OCR-Aufgaben (Optical Character Reconition) trainiertes Modell. Vor Kurzem hat das Start-up Useful Sensors mit Moonshine auch eine vielversprechende Lösung für Sprachtranskription veröffentlicht.
Das ist besonders für Smartphones relevant, Open-Source-Fortschritte wie moondream2 beweisen die technische Machbarkeit. Die tatsächliche Anwendung gestaltet sich für Verbraucher:innen jedoch noch umständlich. Zwar gibt es kleine On-Device-Modelle für Apple Intelligence oder Googles Gemini Nano, beide Hersteller lagern komplexere Aufgaben aber noch weiter auf die Cloud aus.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.