BioGPT ist ein Microsoft-Sprachmodell für biomedizinisches Expertenwissen

BioGPT ist ein von Microsoft-Forschenden entwickeltes Transformer-Sprachmodell, das für die Beantwortung biomedizinischer Fragen optimiert wurde. Laut Microsoft Research liegt das Niveau des Modells auf Augenhöhe mit menschlichen Expert:innen.
Das Forschungsteam hat BioGPT ausschließlich mit domänenspezifischen Daten trainiert. Dazu sammelten sie vor 2021 aktualisierte Fachartikel aus PubMed, einer englischsprachigen textbasierten Metadatenbank für biomedizinische Fachartikel. Insgesamt kamen so 15 Millionen Inhalte mit Titel und Abstract zusammen, die das Team für das Training von BioGPT verwendete.
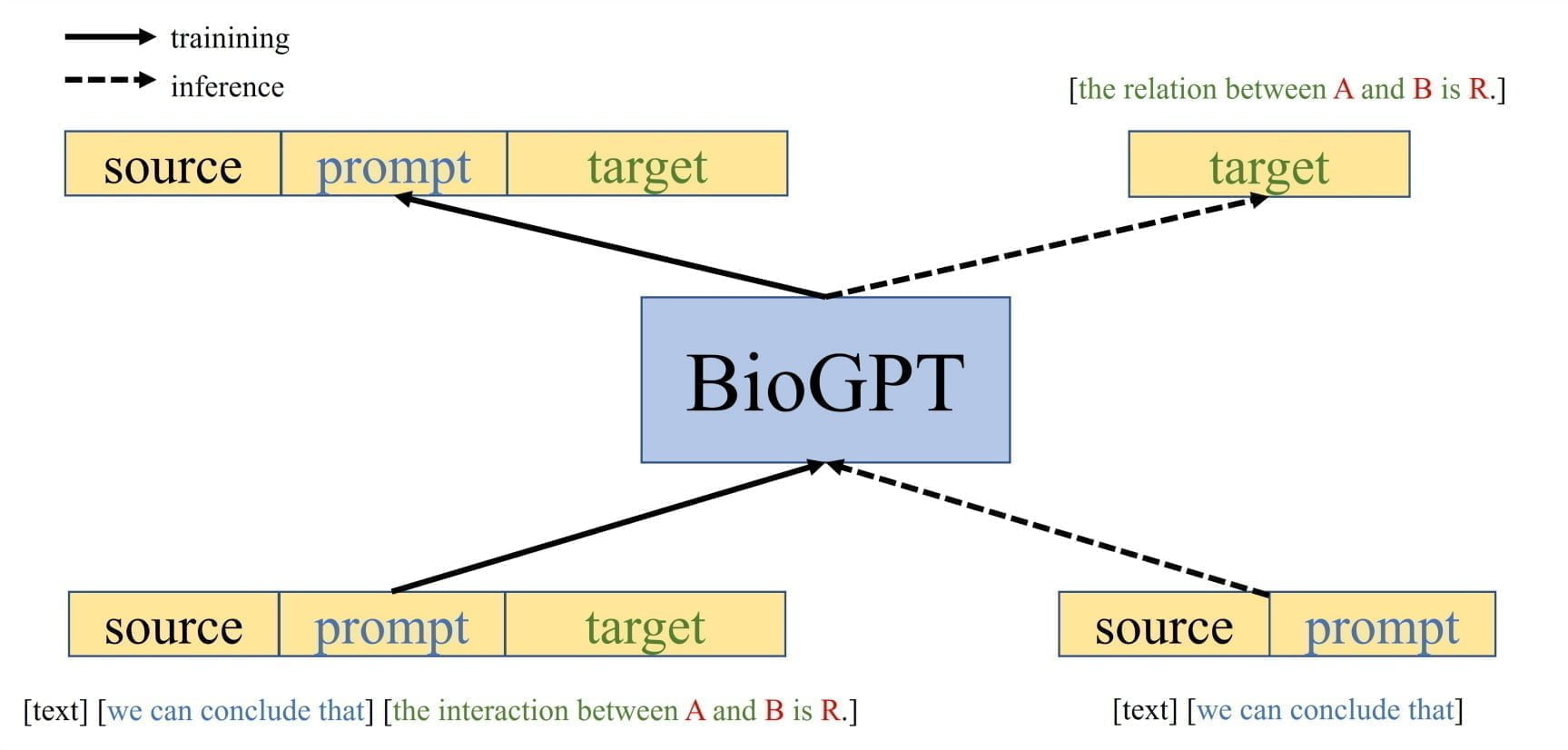
Für das Pre-Training verwendete das Forschungsteam acht Nvidia V100 GPUs für 200.000 Schritte, während die Feinabstimmung mit einer einzigen Nvidia V100 GPU für 32 Schritte durchgeführt wurde.
Das vortrainierte GPT-2-basierte Modell mit 357 Millionen Parametern verfeinerte das Team dann für nachgelagerte Aufgaben: Extraktion von Beziehungen, Beantwortung von Fragen und Klassifizierung von Dokumenten.
BioGPT schlägt größere, generellere Sprachmodelle in biomedizinischen Sprach-Benchmarks
Nach Angaben des Forschungsteams schlägt BioGPT vergleichbare Modelle, die auf Google BERT basieren, in Benchmarks bei der Beantwortung biomedizinischer Fragen und bei End-to-End-Extraktionsaufgaben. Im Vergleich zu einem allgemein trainierten GPT-2 zeigt BioGPT auch bessere Fähigkeiten bei der Textgenerierung für biomedizinische Inhalte.
Input:
The treatment of COVID-19Output GPT-2:
The treatment of COVID-19 is similar to that of COVID-20 and COVID-22, in which COVID-19 is treated
with a variety of ionic, dopaminergic and serotonergic agents. In addition to its effects on COVID-19, the
use of COVID-19 has been suggested to exert effects on the function of other dopamine neurons, including dopamine D2 receptors, D3 receptors and serotonin transporters. These effects include attenuation of the increase in dopamine release induced by the central nervous system stimulant drug amphetamine and its metabolitesOutput BioGPT:
The treatment of COVID-19 with remdesivir (remdesivir for COVID-19) has been approved by the US Food and Drug Administration (FDA) for the treatment of severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) infection in patients with confirmed SARS-CoV-2 infection and is currently being evaluated in clinical trials for the treatment of COVID-19 in patients with confirmed SARS-CoV-2 infection, as well as in patients with suspected or confirmed SARS-CoV-2 infectionBeispiel-Prompt
Die Forscherinnen und Forscher skalierten zudem ihr auf GPT-2 medium basierendes Modell auf die größte verfügbare GPT-2 XL-Architektur. Das fein abgestimmte BioGPTLarge mit (vergleichsweise immer noch wenigen) 1,5 Milliarden Parametern erreichte im PubMedQA-Benchmark eine Genauigkeit von 81 Prozent (BioGPT: 78,2) und übertrifft damit deutlich größere generische Sprachmodelle wie Flan-PaLM (540 Milliarden Parameter, 79,0) und Metas Galactica (120 Milliarden, 77,6).

BioGPT zeigt, dass kleine, aber auf Domänen spezialisierte Sprachmodelle mit wesentlich größeren, allgemeinen Sprachmodellen innerhalb ihrer Domäne konkurrieren können. Ein Vorteil kleinerer Modelle ist der geringere Daten- und Trainingsaufwand.
Der umgekehrte Weg ist das Feintuning sehr großer Sprachmodelle wie PaLM auf spezifische Domänen. Google hat kürzlich mit Med-PaLM gezeigt, dass auch ein großes Sprachmodell mit speziellen Prompts und qualitativ hochwertigen Daten effizient für spezifische Domänen optimiert werden kann. Med-PaLM soll medizinische Laienfragen auf dem Niveau menschlicher Expert:innen beantworten können.
BioGPT soll biomedizinische Inhalte auf dem Niveau menschlicher Experten generieren können
Laut Microsoft Research erreicht BioGPT bei den in den Benchmarks getesteten Aufgaben das Niveau menschlicher Expert:innen und schlägt andere allgemeine und wissenschaftliche Sprachmodelle. BioGPT könne Forschenden helfen, neue Erkenntnisse zu gewinnen, etwa in der Medikamentenentwicklung oder für klinische Therapien.
In Zukunft will das Team mit mehr Skalierung experimentieren und eine noch größere Variante von BioGPT trainieren, die mit noch mehr biomedizinischen Daten und für noch mehr Aufgaben optimiert ist. Der Code des aktuellen BioGPT-Modells ist auf Github verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.