Bytedance entwickelt Code-KI, die 5,4-mal schneller arbeitet als bisherige Modelle

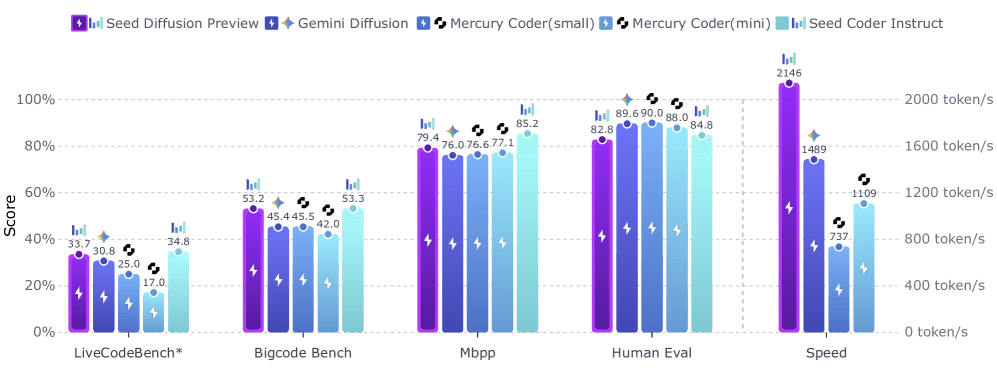
Mit Seed Diffusion Preview stellt Bytedance ein experimentelles KI-Modell vor, das Token parallel statt nacheinander erzeugt. Das Modell erreicht laut Entwickler:innen eine Geschwindigkeit von 2.146 Token pro Sekunde auf industriellen Nvidia-H20-GPUs.
Das Bytedance-Team nutzt einen "Discrete-State Diffusion"-Ansatz. Während Diffusionsmodelle ursprünglich für kontinuierliche Daten wie Bilder entwickelt wurden, passt dieser Ansatz das Verfahren für sogenannte diskrete Daten wie Text und Code an.
Statt Token nacheinander vorherzusagen, lernt das System, Code schrittweise aus einem "verrauschten" Zustand zu rekonstruieren. Dabei werden zunächst alle Positionen mit Platzhaltern gefüllt und dann parallel verschiedene Code-Teile gleichzeitig vervollständigt. Das System behandelt Code-Generierung als Sequenzvorhersageproblem, verwendet aber Transformer-Technologie für die parallele Vorhersage von Code-Abschnitten statt der üblichen sequenziellen Abarbeitung.
Diese Arbeitsweise ermöglicht wesentlich höhere Geschwindigkeiten, worunter jedoch die Qualität des generierten Codes jedoch nicht leiden soll. Auf verschiedenen Code-Benchmarks erreichte Seed Diffusion Preview konkurrenzfähige Leistung zu vergleichbaren Modellen. Besonders bei Code-Bearbeitungsaufgaben übertraf das Diffusionsmodell bisherige Ansätze.
Zweistufiges Training verhindert Fehlverhalten
Die Forschenden entwickelten ein zweistufiges Training, um Probleme traditioneller maskierter Diffusionsmodelle zu lösen. In der ersten Phase nutzte das System mask-basiertes Training, bei dem Teile des Codes durch spezielle Platzhalter-Token ersetzt wurden.
Diese erste Trainingsphase konnte jedoch zu problematischen Mustern führen, bei denen das Modell lernte, nicht-maskierte Token unkritisch zu übernehmen. Um dies zu vermeiden, führten die Forschenden eine zweite Trainingsphase ein.
In dieser verwendete das System edit-basiertes Training mit Einfüge- und Löschoperationen. Dies zwingt das Modell dazu, alle Token zu überprüfen und zu korrigieren, auch die ursprünglich nicht maskierten.
Das Team entwickelte zudem eine Methode zur Optimierung der Generierungsreihenfolge, um strukturelle Eigenschaften von Code zu berücksichtigen. Code enthält starke Abhängigkeiten, Variablen müssen beispielsweise vor ihrer Verwendung deklariert werden.
In einer zusätzlichen Trainingsphase nutzte das System das vortrainierte Modell, um einen großen Datensatz optimaler Generierungsabläufe zu erstellen und zu filtern. Das Modell wurde dann auf diese hochwertigen Abläufe spezialisiert.
Selbstoptimierung für effiziente parallele Dekodierung
Obwohl Diffusionsmodelle theoretisch den Vorteil paralleler Dekodierung bieten, ist die praktische Umsetzung laut den Wissenschaftler:innen herausfordernd. Ein einzelner paralleler Inferenzschritt ist rechenintensiv, und die Reduzierung der Gesamtschritte kann zu Qualitätsverlusten führen.
Das Team entwickelte daher ein "On-Policy Learning"-Verfahren, bei dem das Modell trainiert wurde, seinen eigenen Generierungsprozess zu optimieren. Ziel war es, die Anzahl der Generierungsschritte zu minimieren, während ein Verifikationsmodell die Qualität der finalen Ausgabe sicherstellt.
Für die praktische Umsetzung verwendet das System eine block-weise parallele Verarbeitung, die eine logische Reihenfolge zwischen Code-Blöcken beibehält. Innerhalb jedes Blocks arbeitet es parallel, zwischen den Blöcken jedoch sequenziell.
Bytedance optimierte auch die zugrundeliegende Software-Infrastruktur speziell für diese Art der Verarbeitung, um die theoretischen Geschwindigkeitsvorteile in der Praxis zu realisieren. Das Team nutzte ein internes Framework, das speziell für Diffusions-Verfahren optimiert ist.
Bytedance eifert Google nach
Seed Diffusion Preview ist wie auch Googles vor ein paar Monaten vorgestelltes Gemini Diffusion ein experimentelles Modell, das sich auf Code-Generierung konzentriert. Bytedance will mit weiteren Experimenten die Skalierungseigenschaften erforschen und den Ansatz auf komplexe Reasoning-Aufgaben anwenden. Eine Demo ist auf dieser Website online verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.