Bytedance entwickelt noch eine Methode, um Menschen mit KI tanzen zu lassen

Das neue KI-Framework DreamActor-M1 von Bytedance soll aus einzelnen Fotos Videos von Menschen generieren können. Zentrale Neuerung ist dabei die Kombination verschiedener Steuerungssignale, die eine deutlich bessere Kontrolle über Mimik und Bewegungen ermöglicht als bisherige Systeme.
Das System nutzt drei getrennte, aber koordinierte Steuerungselemente, die zusammen die sogenannte "Hybrid Guidance" bilden. Für natürliche Gesichtsausdrücke kommt ein spezieller Gesichtsencoder zum Einsatz, der die Mimik unabhängig von Identität und Kopfhaltung steuern kann - ein deutlicher Fortschritt gegenüber älteren Systemen, die oft Probleme hatten, diese Aspekte sauber zu trennen.
Das Video links liefert den Ausgangspunkt für Mimik und Tonspur, deren Merkmale auf eine Cartoonfigur und eine echte Person übertragen werden. | Video: Bytedance
Die Kopfbewegungen werden über ein 3D-Modell kontrolliert, das durch farbige Kugeln die gewünschte Blickrichtung und Kopfhaltung anzeigt. Für realistische Körperbewegungen verwendet das System ein 3D-Skelett mit einer speziellen Anpassungstechnik, die automatisch unterschiedliche Körperproportionen berücksichtigt und so natürlich wirkende Bewegungen erzeugt.
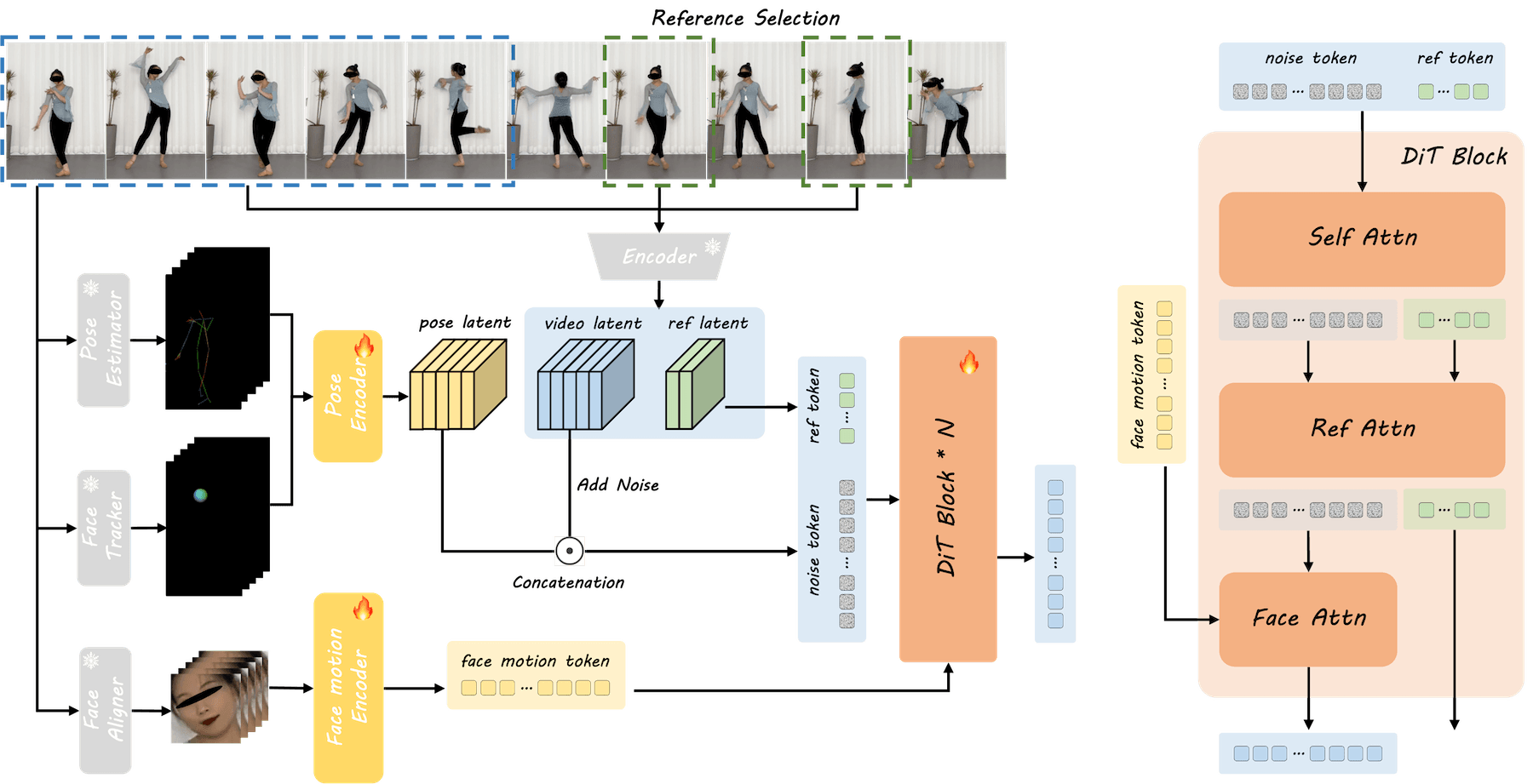
Während des Trainings lernt das System anhand von Bildern mit minimaler, mittlerer und maximaler Rotation. Bei der späteren Anwendung kann es dann bei Bedarf zusätzliche Ansichten selbst generieren. Wenn beispielsweise nur ein Porträtfoto als Ausgangsmaterial vorhanden ist, kann es die fehlenden Informationen wie Kleidung oder Körperhaltung intelligent ergänzen.

Das Training des Systems erfolgt in drei Phasen: Zunächst lernt es grundlegende Körper- und Kopfbewegungen zu generieren. In der zweiten Phase kommen verschiedene Gesichtsausdrücke hinzu, die präzise gesteuert werden können.
In der letzten Phase werden alle diese Komponenten gemeinsam optimiert, um ein harmonisches Zusammenspiel zu gewährleisten. Für diesen Prozess nutzen die Entwickler:innen einen umfangreichen Datensatz mit 500 Stunden Videomaterial, der zu gleichen Teilen aus Ganzkörper- und Oberkörperaufnahmen besteht.
In umfangreichen Tests zeigte DreamActor-M1 deutlich bessere Ergebnisse als vergleichbare Systeme, sowohl bei der visuellen Qualität als auch bei der Präzision der Bewegungssteuerung, sogar im Vergleich zu kommerziellen Lösungen wie Runway Act-One.
Video: Bytedance
Das System kann allerdings keine dynamischen Kamerabewegungen durchführen oder Interaktionen mit Objekten darstellen. Auch bei extremen Unterschieden zwischen den Körperproportionen im Originalfoto und der gewünschten Bewegung könne es zu Problemen kommen. Komplexe Szenenübergänge seien ebenfalls noch eine Herausforderung.
Viele weitere KI-Experimente
TikToks Mutterkonzern Bytedance investiert viele Ressourcen in teilweise parallel laufende Forschungsarbeiten, in denen oft digitale Avatare animiert werden. Auch das Anfang des Jahres präsentierte OmniHuman-1 ist auf ähnliche Ergebnisse ausgelegt.
Hier stellt Bytedance zudem unter Beweis, wie schnell es Forschung in die Praxis umsetzen kann: OmniHuman-1 ist schon jetzt über die CapCut-Plattform Dreamina als Tool zur Lippensynchronisation verfügbar. Andere Experimente umfassen die Video-KI-Reihe Goku oder den Porträtgenerator InfiniteYou.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.