GPT-4 besteht Japans nationale Physiotherapeutenprüfung

Selbst ohne spezielles Training konnte GPT-4 medizinische Prüfungen auf hohem Niveau erfolgreich absolvieren. Dabei wurden jedoch auch die Mängel des Modells deutlich.
Eine aktuelle, extern begutachtete Studie in der Fachzeitschrift Cureus hat gezeigt, dass OpenAIs großes, wenn auch etwas älteres Sprachmodell GPT-4 die staatliche Physiotherapeutenprüfung in Japan bestehen kann. Die Studie analysierte die Leistung von GPT-4 sowohl bei textbasierten als auch bei visuellen Fragen.
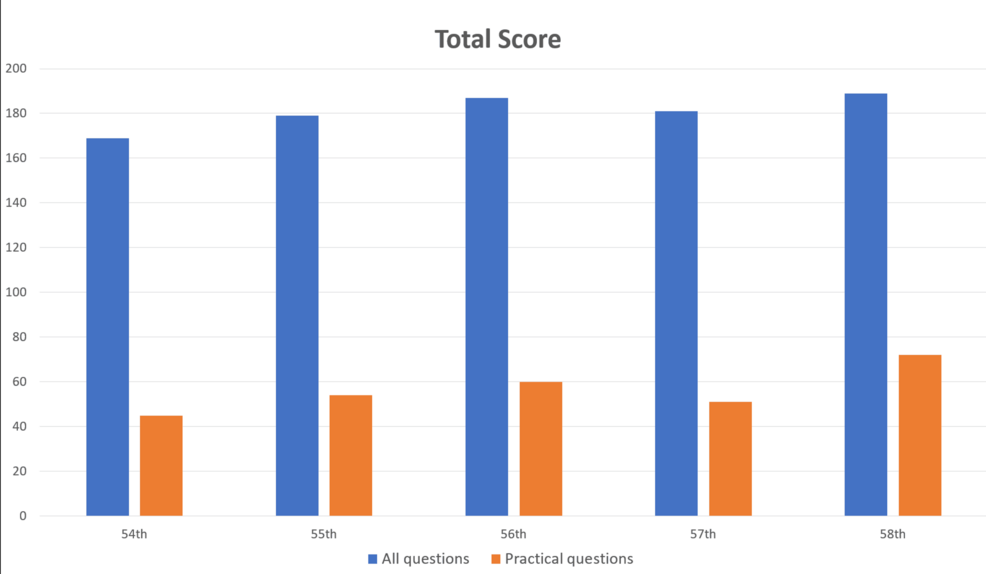
Die Physiotherapeutenprüfung in Japan besteht aus 160 allgemeinen und 40 praktischen Fragen, die Gedächtnis, Verständnis, Anwendung, Analyse und Bewertung testen. Die Forscher:innen gaben 1.000 Fragen in den GPT-4 ein und verglichen die Antworten mit den offiziellen richtigen Antworten.

GPT-4 erfüllte die Anforderungen aller fünf Tests und beantwortete 73,4 Prozent der Fragen richtig. Damit hat GPT-4 die Prüfung bestanden.
Vor allem mangelhaftes Bildverständnis
Allerdings hatte das KI-Modell Schwierigkeiten mit fachpraktischen Fragen und Fragen, die Bilder oder Tabellen enthielten. Die Trefferquote bei den allgemeinen Fragen lag mit 80,1 % deutlich höher als bei den praktischen Fragen mit nur 46,6 Prozent.
Eine ähnliche Diskrepanz in den Trefferquoten zeigte sich auch beim Vergleich von reinen Textfragen (80,5 Prozent) und Fragen mit Bildern und Tabellen (35,4 Prozent). Dieser Befund wird durch frühere Studien gestützt.
Interessanterweise ergab die Studie, dass die Leistung des GPT-4 weder vom Schwierigkeitsgrad des Frageformats noch von der Länge des Fragetextes wesentlich beeinflusst wurde.
Außerdem bemerkten die Forscher:innen die gute Leistung des Modells sogar bei japanischen Eingaben, obwohl GPT-4 hauptsächlich mit einem englischsprachigen Korpus entwickelt wurde.
Bessere Leistung mit GPT-4o?
Während die Studie das Potenzial des GPT-4 als Instrument für die klinische Rehabilitation und die medizinische Ausbildung aufzeigt, warnen die Forscher davor, dass das Modell nicht alle Fragen korrekt beantwortet.
Sie betonen die Notwendigkeit, neuere Versionen und die Fähigkeiten des Modells in schriftlichen und argumentativen Tests weiter zu evaluieren. Das neuere Modell GPT-4o, das von Grund auf multimodal ist, könnte bessere Ergebnisse beim visuellen Verständnis erzielen.
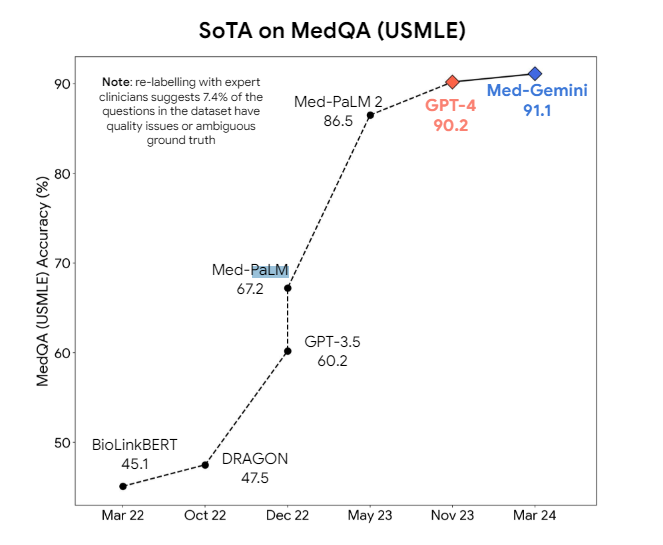
Große Sprachmodelle zeigen schon seit längerem Potenzial für den Einsatz in der Medizin. Bessere Ergebnisse als mit allgemeinen Modellen wie GPT-4 versprechen spezialisierte Versionen. Google hat mit Med-PaLM 2 und Med-Gemini für medizinische Aufgaben optimierte Varianten seiner Sprachmodelle entwickelt. Med-Gemini hat jedoch trotz Spezialisierung nur einen geringen Vorteil gegenüber dem generisch trainierten GPT-4.
Auch Meta hat auf Llama 3 basierende Modellen für den medizinischen Bereich im Portfolio. Die Modelle sollen Ärzte und medizinisches Personal bei verschiedenen Aufgaben wie der Beantwortung komplexer Fragen, der Erstellung von Zusammenfassungen und der Auswertung multimodaler Daten unterstützen.
Es wird jedoch noch einige Zeit dauern, wenn überhaupt, bis sich die medizinischen LLMs in der Praxis durchsetzen. Selbst das derzeitige Benchmark-Niveau lässt noch zu viel Raum für falsche Antworten, die im medizinischen Kontext besonders kritisch sind. Auch hier scheint ein Durchbruch in den logischen Fähigkeiten notwendig, um LLMs wirklich sicher in den medizinischen Alltag zu bringen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.