Chinas KI-Wettlauf: Alibaba stellt Qwen3.5 als kostenloses Open-Weight-Modell vor

Alibaba hat mit Qwen3.5-397B-A17B das erste Modell seiner neuen KI-Serie veröffentlicht. Das Modell verarbeitet Text, Bilder und Video in einer gemeinsamen Architektur und ist als Open-Weight-Modell frei verfügbar.
Das Modell umfasst insgesamt 397 Milliarden Parameter, von denen bei jeder Anfrage nur 17 Milliarden tatsächlich genutzt werden. Wie bei anderen großen KI-Modellen kommt dafür eine Mixture-of-Experts-Architektur zum Einsatz, bei der je nach Aufgabe nur die relevanten Teile des Netzwerks aktiviert werden.
Allerdings ist das Verhältnis von Gesamt- zu aktiven Parametern bei Qwen3.5 wie auch schon bei Qwen3-Next ungewöhnlich hoch, was auf eine besonders feinkörnige Aufteilung in viele spezialisierte Experten hindeutet. Zusätzlich setzt Alibaba auf eine neuartige Aufmerksamkeitsarchitektur namens Gated Delta Networks, die den Rechenaufwand weiter senken soll.
Laut dem Qwen-Team verarbeitet Qwen3.5 bei einem Kontextfenster von 256.000 Token Anfragen 19-mal schneller als der deutlich größere Vorgänger Qwen3-Max und 3,5- bis 7-mal schneller als der direkte Vorgänger Qwen3-235B. Die Leistungsfähigkeit soll dabei auf vergleichbarem Niveau bleiben.

Stark bei Agenten und Bildverständnis, aber kein klarer Gesamtsieger
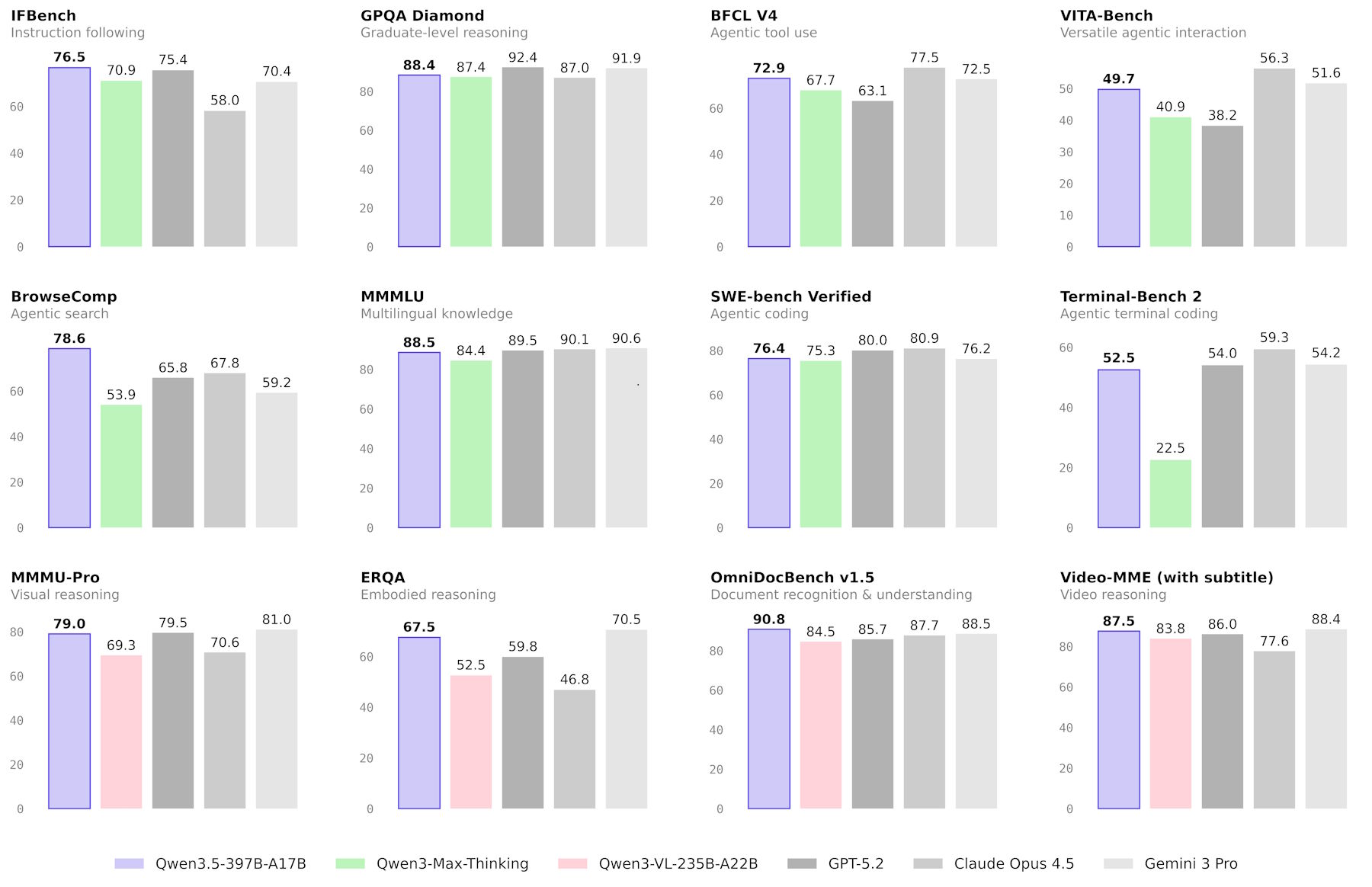
Qwen3.5 setzt in einigen Benchmarks neue Bestmarken, liegt aber in anderen hinter GPT5.2, Claude 4.5 Opus oder Gemini-3 Pro zurück. Den größten Fortschritt macht das Modell im agentischen Bereich: Im TAU2-Bench, der misst, wie gut ein Modell als autonomer Agent Aufgaben erledigt, erreicht Qwen3.5 86,7 Punkte und liegt damit knapp hinter GPT-5.2 (87,1) und Claude 4.5 Opus (91,6). Beim Befolgen komplexer Anweisungen setzt das Modell mit IFBench (76,5) und MultiChallenge (67,6) jeweils den Bestwert im Vergleichsfeld. So soll das Modell aus der Kombination eines Bildes und Prompts etwa ein Slidedeck bauen können.
Bei visuellen Aufgaben erzielt Qwen3.5 laut Alibaba Höchstwerte in mehreren mathematisch-visuellen Benchmarks, darunter MathVision (88,6) und ZEROBench (12). Im Dokumentenverständnis und bei der Texterkennung liegt es ebenfalls größtenteils vorn. Im breiteren Bildverständnis-Benchmark MMMU bleibt es mit 85 allerdings hinter Gemini 3 Pro (87,2) und GPT-5.2 (86,7).
Beim klassischen Reasoning und Coding führen weiterhin andere Modelle: GPT-5.2 erreicht im LiveCodeBench 87,7 gegenüber 83,6 bei Qwen3.5. Bei mathematischen Wettbewerbsaufgaben wie AIME26 liegt das Modell mit 91,3 hinter GPT-5.2 (96,7) und Claude 4.5 Opus (93,3).
Bessere Daten, mehr Reinforcement Learning
Die Verbesserungen gegenüber der Vorgängerserie Qwen3 führt das Team auf eine massiv ausgeweitete Trainingsphase mit Reinforcement Learning zurück. Statt das Modell auf einzelne Benchmarks zu trimmen, habe man die Vielfalt und Schwierigkeit der Trainingsumgebungen systematisch erhöht. Die deutlichsten Fortschritte zeigen sich bei den Agentenfähigkeiten.
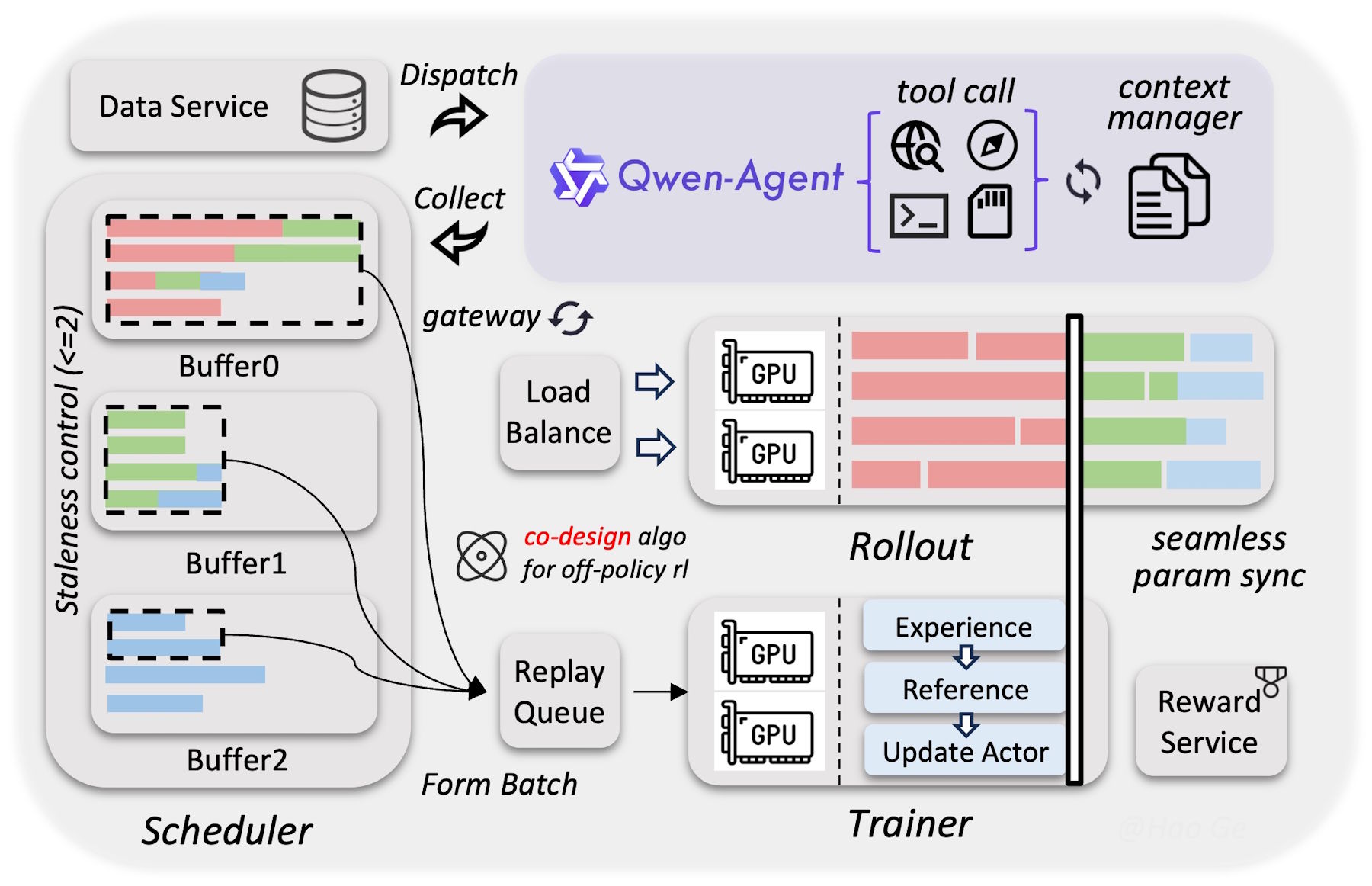
Beim Vortraining wurde das Modell laut Alibaba mit erheblich mehr Daten gefüttert als sein Vorgänger, bei gleichzeitig strengerer Filterung. Qwen3.5 erreiche damit trotz seiner effizienteren Architektur die Leistung des über eine Billion Parameter großen Qwen3-Max-Base.
Die Sprachunterstützung ist von 119 auf 201 Sprachen und Dialekte gewachsen. Ein vergrößertes Vokabular von 250.000 Token (zuvor 150.000) soll die Verarbeitungsgeschwindigkeit bei den meisten Sprachen um 10 bis 60 Prozent steigern.
Agent Qwen: Vom Labyrinth-Löser bis zum Desktop-Agenten
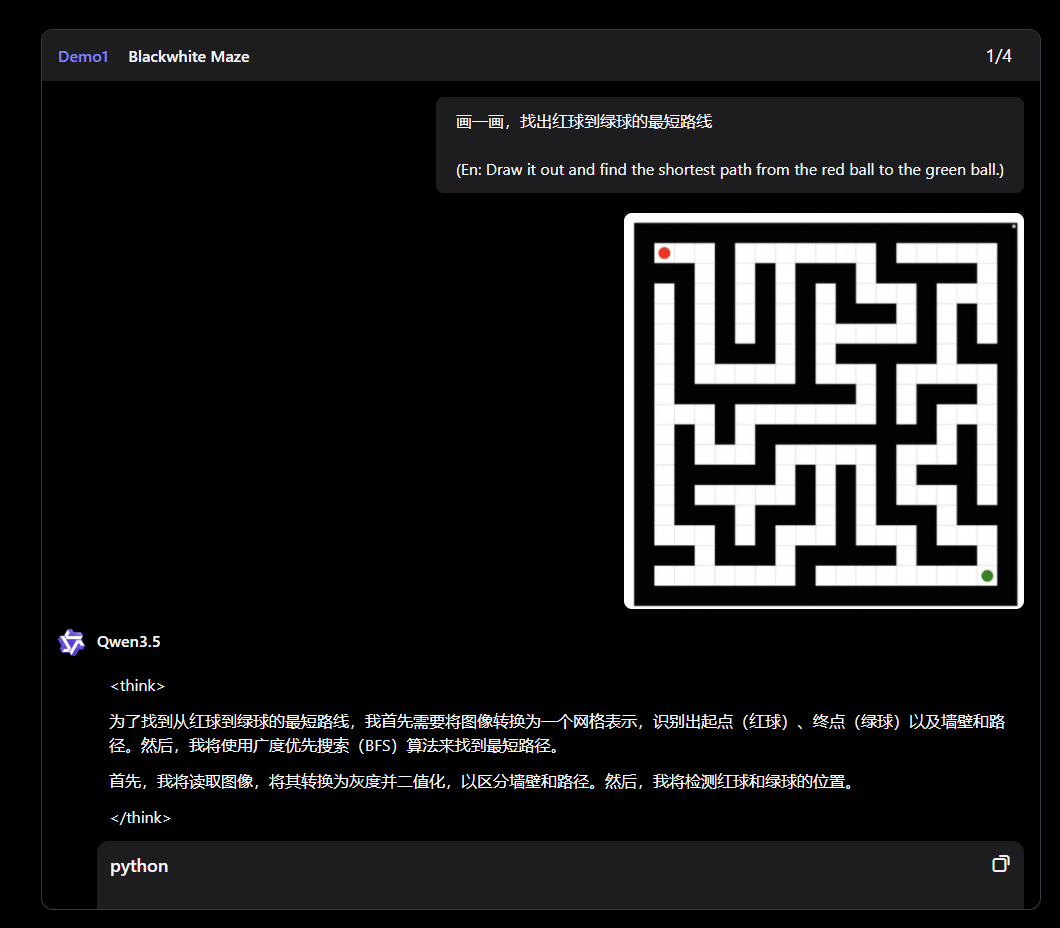
Als nativ multimodales Modell kann Qwen3.5 laut Alibaba bis zu zwei Stunden Video verarbeiten. In den veröffentlichten Demos zeigt das Unternehmen unter anderem, wie das Modell eigenständig Python-Code schreibt, um ein Labyrinth zu lösen und den kürzesten Pfad visuell darzustellen. In einem anderen Beispiel analysiert es Verkehrsvideos und begründet Fahrentscheidungen anhand von Ampelphasen.
Als GUI-Agent soll Qwen3.5 selbstständig Smartphone- und Computeroberflächen bedienen können, etwa um Excel-Tabellen zu vervollständigen oder mehrstufige Arbeitsabläufe am Desktop auszuführen. Für Entwickler bietet Alibaba Integrationen mit Tools wie Qwen Code an, die natürlichsprachliche Anweisungen in funktionierenden Code umsetzen sollen.
Als nächsten Schritt formuliert das Qwen-Team den Übergang von der Modellskalierung zur Systemintegration. Künftige Agenten sollen über ein dauerhaftes Gedächtnis verfügen, sich selbst verbessern und wirtschaftliche Einschränkungen berücksichtigen können. Statt aufgabengebundener Assistenten will Alibaba autonome Systeme schaffen, die komplexe Aufgaben über mehrere Tage hinweg eigenständig bearbeiten.
Verfügbarkeit
Das Open-Weight-Modell Qwen3.5-397B-A17B steht auf Hugging Face zum Download bereit und ist unter der Apache-2.0-Lizenz veröffentlicht, die auch die kommerzielle Nutzung und Modifikation erlaubt. Entwickler können es über die Chat-Oberfläche Qwen Chat direkt im Browser ausprobieren – wahlweise im Auto-, Thinking- oder Fast-Modus.
Die gehostete Variante Qwen3.5-Plus mit einem Kontextfenster von einer Million Token ist über das Alibaba Cloud Model Studio per API verfügbar und unterstützt dort unter anderem Websuche, Code Interpreter und adaptives Reasoning. Für den Einsatz als Coding-Agent lässt sich Qwen3.5 zudem in Tools wie Qwen Code integrieren.
Über die API kostet das Modell 0,40 US-Dollar pro Million Input-Token und 2,40 US-Dollar pro Million Output-Token. Das ist wie mittlerweile üblich bei chinesischen KI-Laboren ein Bruchteil dessen, was OpenAI oder Anthropic laut Benchmarks für vergleichbare Modelle verlangen. Dennoch spielen chinesische Unternehmen bisher keine Rolle im US-B2B-Markt, angeblich aber bei kostenbewussten KI-Start-ups.
Chinas KI-Labore im Dauersprint
Qwen3.5 erscheint inmitten eines verschärften Wettlaufs chinesischer KI-Labore. Zhipu AI hat erst kürzlich mit GLM-5 ein Open-Source-Modell mit 744 Milliarden Parametern veröffentlicht, das bei Coding und Agentenaufgaben mit Claude Opus 4.5 und GPT-5.2 mithalten soll. Moonshot AI hat mit Kimi K2.5 ein Modell vorgelegt, das bis zu 100 parallel arbeitende Sub-Agenten koordiniert.
MiniMax hat derweil M2.5 auf den Markt gebracht, das Spitzenleistung zu einem Bruchteil der Kosten westlicher Anbieter verspricht. Und Baidu hat mit Ernie 5.0 und 2,4 Billionen Parametern Platz 1 unter allen chinesischen Modellen im LMArena-Ranking erreicht.
All diesen Modellen ist gemein, dass sie in Benchmarks ähnliche Leistungen wie westliche Modelle erzielen, zudem frei verfügbar sind und – sofern man dennoch einen API-Service nutzen will – spottbillig im Vergleich zu ihren westlichen Gegenstücken. DeepSeeks nächstes großes Modell mit einer Billion Parametern verzögert sich noch; gerüchteweise startet es diese Woche.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.