COLORBENCH zeigt Schwächen multimodaler KI
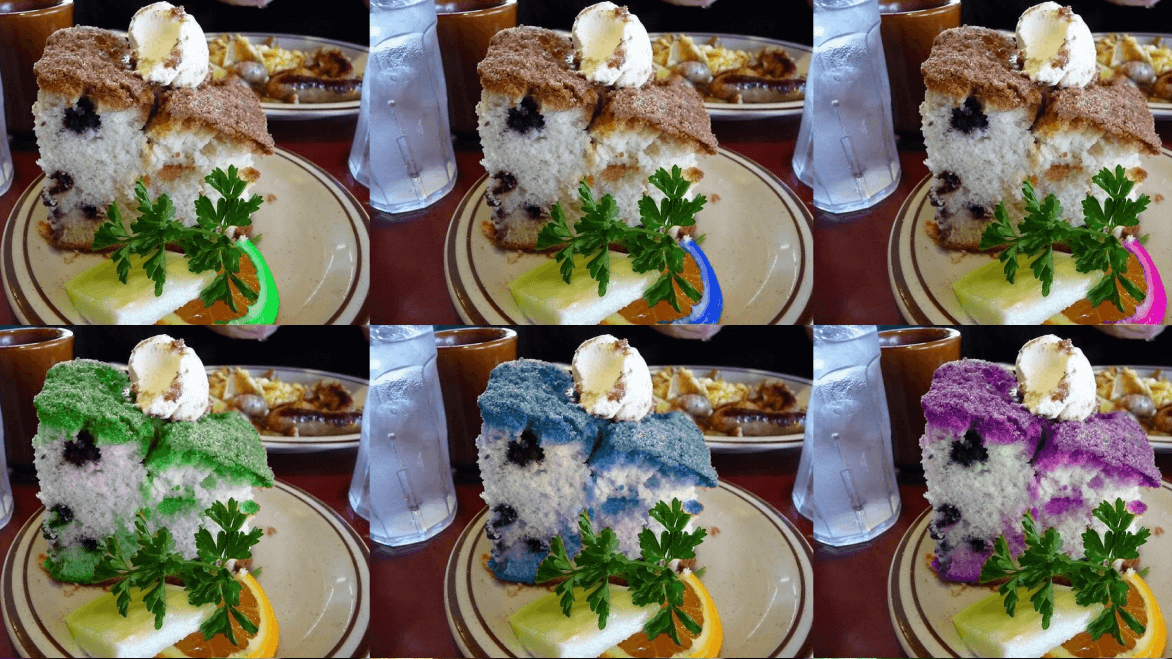
Mit COLORBENCH präsentieren Forscher der University of Maryland erstmals einen spezialisierten Benchmark, der die Farbwahrnehmung und -verarbeitung von Vision-Language-Modellen (VLMs) systematisch untersucht. Die Resultate offenbaren grundlegende Schwächen – auch bei den größten Modellen.
Farben spielen eine zentrale Rolle in der menschlichen visuellen Wahrnehmung und sind essenziell in Anwendungen wie medizinischer Bildanalyse, Fernerkundung oder Produkterkennung. Bisher ist aber unklar, ob VLMs Farben ähnlich verstehen und nutzen können.
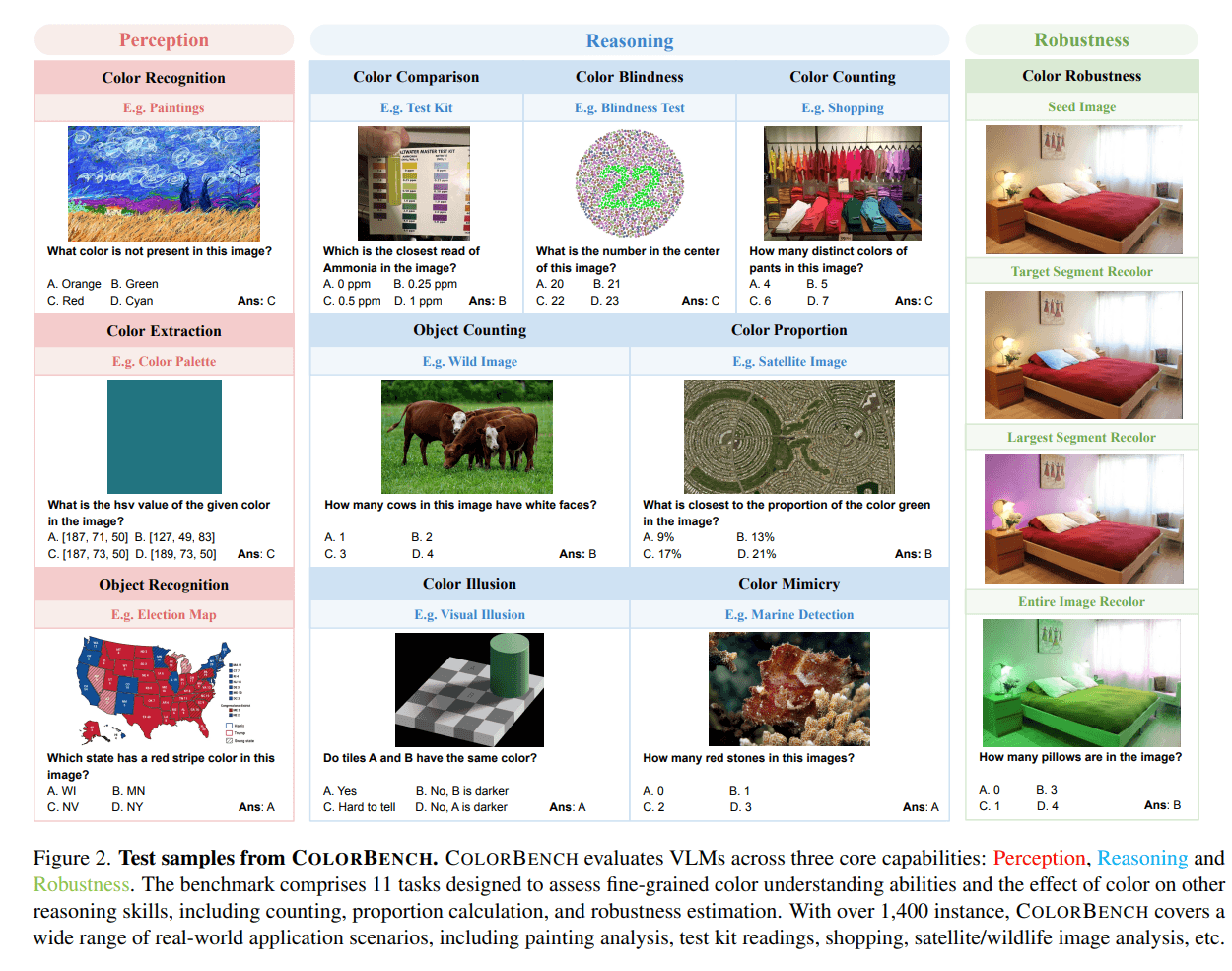
COLORBENCH deckt drei Dimensionen daher ab: Farbwahrnehmung, Farbschlussfolgerung und Robustheit gegenüber Farbveränderungen. In elf Aufgaben mit insgesamt 1.448 Instanzen und 5.814 Bild-Text-Fragen müssen Modelle beispielsweise Farben erkennen, Farbanteile schätzen, Objekte mit bestimmten Farben zählen oder sich von Farbillusionen nicht täuschen lassen. Zusätzlich wird getestet, ob Modelle bei gezielt veränderten Farben konsistent bleiben – etwa wenn Farben einzelner Bildsegmente rotiert werden.
Größere Modelle sind besser - aber nicht viel
Getestet wurden 32 gängige VLMs, darunter GPT-4o und Gemini-2 sowie diverse Open-Source-Modelle mit bis zu 78 Milliarden Parametern. Die Resultate zeigen: Größere Modelle schneiden zwar tendenziell besser ab, der Effekt ist aber schwächer als bei anderen Benchmarks – und die Unterschiede zwischen Open-Source- und proprietären Modellen gering.
Besonders schwach performen alle Modelle bei Aufgaben wie beim Zählen der Farben (Color Counting) oder Farbenblindheitstests, wo viele unter 30 % Genauigkeit bleiben. In der Farbextraktion – der Abfrage von HSV- oder RGB-Werten – erreichen selbst große Modelle oft nur mittlere Werte. Besser schneiden sie bei Objekt- oder Farberkennung ab, was vermutlich auf die Trainingsdaten zurückzuführen ist.
Farben können täuschen
Ein zentrales Ergebnis ist, dass Farbinformationen zwar oft genutzt werden, aber in manchen Aufgaben zu Fehlern führen. In Farbillusionen oder bei getarnter Objekterkennung verbessert sich die Modellleistung, wenn die Bilder in Graustufen umgewandelt werden – ein Hinweis darauf, dass die Farbsignale hier eher irreführend als hilfreich sind. Umgekehrt sind in einigen Aufgaben ohne Farbe kaum sinnvolle Antworten möglich.
Das Team zeigt auch: Chain-of-Thought-Reasoning verbessert nicht nur Schlussfolgerungsaufgaben, sondern auch die Robustheit gegenüber veränderten Farbtönen – obwohl sich nur die Farben und nicht die Fragen ändern. GPT-4o etwa steigert seine Robustheit durch CoT von 46,2 % auf 69,9 %.
Vision-Encoder bleiben vernachlässigt
Die Analyse zeigt außerdem, dass die Größe des Sprachmodells stärker mit der Leistung korreliert als die des Vision-Encoders. Letzterer ist in vielen Modellen kaum skaliert (meist 300–400 Mio. Parameter), was eine differenzierte Bewertung erschwert. Die Forscher sehen darin ein strukturelles Defizit aktueller VLMs und regen an, auch die visuellen Komponenten gezielt weiterzuentwickeln.
COLORBENCH steht öffentlich zur Verfügung und soll die Entwicklung farbsensitiverer und robusterer VLMs forcieren. Künftig wollen die Forscher den Benchmark um Aufgaben erweitern, die Farbe mit Textur, Form und Raumrelationen verknüpfen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.