Cybersecurity: Claude Sonnet 4.5 entdeckt laut Anthropic neue Sicherheitslücken
Anthropic glaubt, dass Sprachmodelle zunehmend bei der Cybersicherheit unterstützen können.
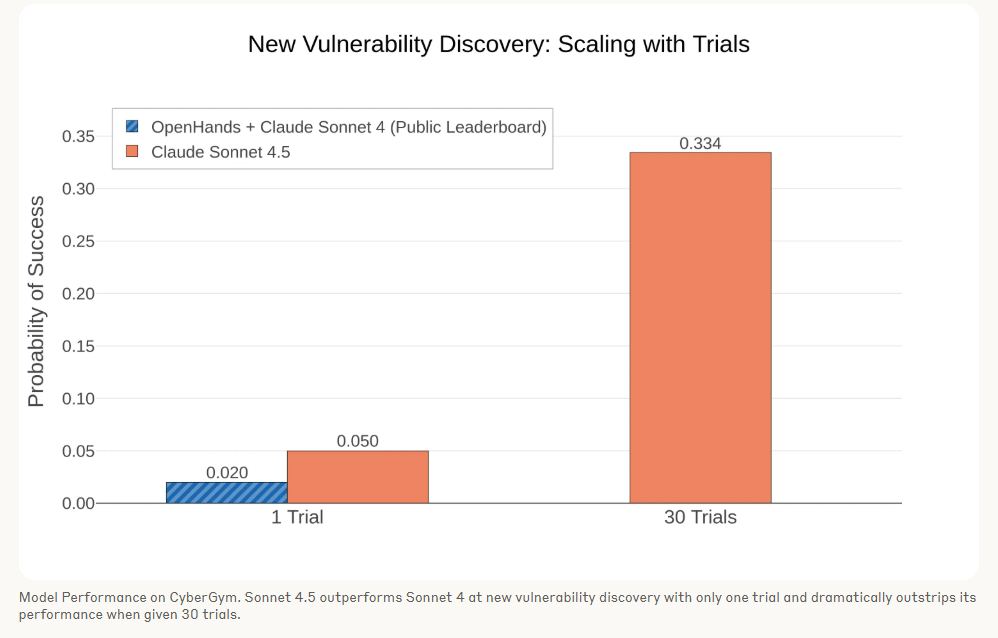
"Während die CyberGym-Bestenliste zeigt, dass Claude Sonnet 4 nur in etwa 2 % der Fälle neue Schwachstellen entdeckt, findet Sonnet 4.5 in 5 % der Fälle neue Schwachstellen. Wenn wir den Versuch 30-mal wiederholen, entdeckt es in über 33 % der Projekte neue Schwachstellen."
Die automatisierte Identifikation bislang unbekannter Schwachstellen in realer Open-Source-Software wird laut Anthropic in externen Evaluierungen bereits sichtbar: In der DARPA AI Cyber Challenge nutzten Teams LLMs (einschließlich Claude) und fanden zuvor unbekannte, nicht-synthetische Schwachstellen. Das Unternehmen spricht von einem möglichen Wendepunkt beim Einfluss von KI auf die Cybersicherheit.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.