Das WWW macht dicht: KI-Unternehmen droht Datenwinter

Eine Studie zeigt, dass KI-Modelle zunehmend von ihren Trainingsdaten im Web abgeschnitten werden. Die rapide wachsende Zahl von Einschränkungen könnte dazu führen, dass Modelle in Zukunft aus weniger, einseitigeren und veralteten Informationen lernen müssen.
Eine großangelegte Studie der unabhängigen akademischen Data Provenance Initiative dokumentiert einen rapiden Rückgang des Zugangs zu Webdaten für KI-Modelle. Das Forscherteam analysierte die Robots.txt-Dateien und Nutzungsbedingungen von 14.000 Webdomänen, die als Quellen für beliebte KI-Trainingsdatensätze wie C4, RefinedWeb und Dolma dienen.
Innerhalb eines Jahres, von April 2023 bis April 2024, stieg der Anteil der für KI-Crawler vollständig gesperrten Token in diesen Datensätzen von etwa 1 Prozent auf 5 bis 7 Prozent. Mit Token sind die einzelnen Satz- und Wortbestandteile gemeint, mit denen ein KI-Modell trainiert wird.
Bei den wichtigsten Datenquellen war der Anstieg noch deutlicher: Hier stieg der Anteil der gesperrten Token von weniger als 3 Prozent auf 20 auf 33 Prozent. Die Forscher prognostizieren, dass sich dieser Trend in den kommenden Monaten fortsetzen wird. Besonders häufig wird OpenAI ausgesperrt, gefolgt von Anthropic und Google.
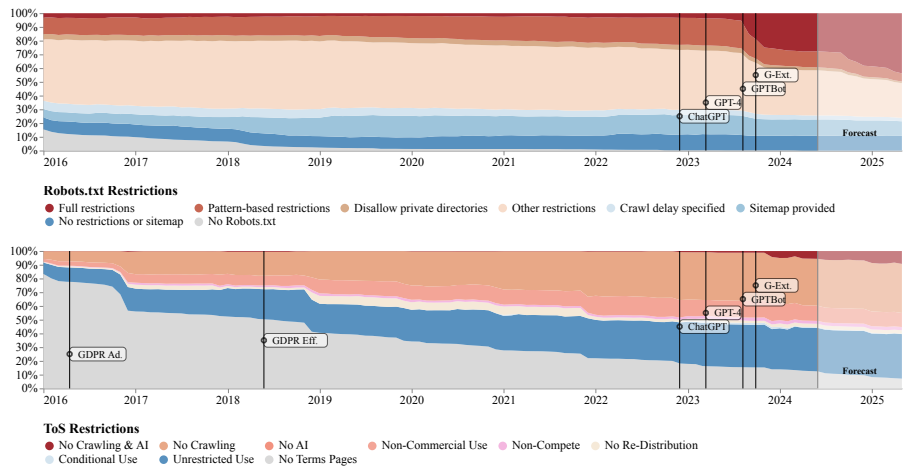
Die Beschränkungen gehen vorwiegend von Nachrichtenwebsites, Foren und Social-Media-Plattformen aus. Bei Nachrichtenseiten stieg der Anteil vollständig gesperrter Tokens innerhalb eines Jahres von drei Prozent auf 45 Prozent. Deren Anteil in den Trainingsdaten dürfte daher zugunsten von Unternehmens- und E-Commerce-Websites, die weniger Restriktionen aufweisen, sinken.
KI-Herstellern dürfte genau dieser Trend besonders treffen: In der Branche hat sich mittlerweile die Erkenntnis durchgesetzt, dass es für die weitere Entwicklung von KI wichtig sein wird, dass die Modelle mehr aus weniger, dafür aber qualitativ hochwertigen Daten lernen.
Die Studie zeigt auch, dass die tatsächliche Nutzung von generativen KI-Modellen vom Inhalt ihrer Trainingsdaten abweicht. Dies könnte insofern relevant sein, als Verlage, die KI-Hersteller verklagen, dies unter der Prämisse tun, dass Angebote wie ChatGPT mit den Informationsangeboten der Verlage konkurrieren und diese Fähigkeit auf Basis der Verlagsinhalte erlangt haben.

Insgesamt könnte diese Entwicklung das Training leistungsfähiger und zuverlässiger KI-Systeme erschweren oder zumindest verteuern. Anbieter hochwertiger Inhalte könnten neue Einnahmequellen erschließen und zu den großen Profiteuren werden.
OpenAI beispielsweise hat in den vergangenen Monaten mehrere millionenschwere Verträge mit Verlagen ausgehandelt, um Zugang zu deren Inhalten für Echtzeit-Anzeige in Chat-Systemen und KI-Training zu erhalten. Andere dürften diesem Beispiel folgen, es sei denn, ein Fair-Use-Urteil stellt die gesamte Entwicklung auf den Kopf.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.