Deepmind stellt den neuen Benchmark mit Datensatz TAP-Vid vor. Er hilft beim Training von Computer-Vision-Systemen, die in Videos jeden beliebigen Punkt tracken können.
Bisherige KI-Systeme mit Weltwissen sind vorwiegend mit Texten und kommentierten Bildern trainiert. Das Training mit Videodaten gilt als Entwicklungshorizont, aber die Daten sind komplex in der Handhabung. Unter anderem ist es für KI-Systeme im Vergleich zu Text oder Bild schwieriger, ein Video zu analysieren, da es in Bewegung ist und viele Details hat.
Deepminds neuer Tracking-Benchmark für jeden beliebigen Punkt in einem Video (TAP, Tracking any Point) könnte die Analysefähigkeit visueller KIs für Videos beschleunigen.
Deepmind stellt Datensatz TAP-Vid und Tracking-Modell TAP-Net vor
Deepmind stellt mit TAP-Vid einen Punkte-Tracking-Benchmark samt Datensatz und mit TAP-Net ein mit diesen Daten trainiertes Demo-KI-System vor, das in Videos beliebige Punkte auf Oberflächen tracken kann. Das folgende Video zeigt eine kurze Demo.
Video: Deepmind
Anstatt nur das Objekt zu verfolgen, kann TAP-Net sich in Bewegung verformende Oberflächen verfolgen. Gängige KI-Tracking-Systeme segmentieren Videos in einzelne Bereiche oder teilen sie in Boxen auf, was ungenauer ist als das gezeigte Tracking einzelner Punkte.
Das Punkte-Tracking hat zudem weitere Vorteile: KI-Systeme können anhand der Veränderung der Oberflächen Rückschlüsse auf die 3D-Form, physikalische Eigenschaften und Objektinteraktionen ziehen und so ein besseres physikalisches Verständnis für die Welt entwickeln.
Dieses umfangreichere Weltwissen wiederum könnte die Grundlage für eine neue Generation KI-Systeme für viele Einsatzbereiche sein wie selbstfahrende Autos oder Roboter, die präziser mit ihrer Umwelt interagieren.
Die Beiträge dieser Arbeit sind dreifach. Erstens entwickeln und validieren wir einen Algorithmus, der Annotatoren dabei unterstützt, Punkte genauer zu verfolgen. Zweitens erstellen wir einen Evaluierungsdatensatz mit 31.951 (31.301+650) Punkten, die in 1.219 (1.189 + 30) echten Videos verfolgt wurden. Drittens untersuchen wir mehrere Basisalgorithmen und vergleichen unseren Punktverfolgungsdatensatz mit dem nächstgelegenen existierenden Punktverfolgungsdatensatz Datensatz - JHMDB Human Keypoint Tracking [30] - und zeigen, dass das Training mit unserer Problemformulierung des Problems die Leistung auf diesem weitaus begrenzteren Datensatz steigern kann.
Aus dem Paper
Die TAP-Vid-Datensätze bestehen aus realen Videos mit genauen menschlichen Annotationen von Tracking-Punkten und synthetischen Videos mit perfekten Tracking-Punkten: TAP-Vid-Kinetics und TAP-Vid-DAVIS enthalten reale Videos mit Punktannotationen, die von Menschen gesammelt wurden. Der synthetische TAP-Vid-Kubric-Datensatz und TAP-Vid-RGB-Stacking wurden in einer simulierten Roboterumgebung erstellt.
TAP-Net trackt genauer als bisherige Systeme
Mit synthetischen Daten trainiert, trackt TAP-Net laut Deepmind im eigenen Benchmark signifikant besser als bisherige Systeme. Einschränkungen sind Flüssigkeiten oder transparente Objekte, die noch nicht verlässlich verfolgt werden können. Bei den von Menschen annotierten Videos sei ein Problem, dass die Annotationen teils ungenau oder falsch seien, schreiben die Forschenden.
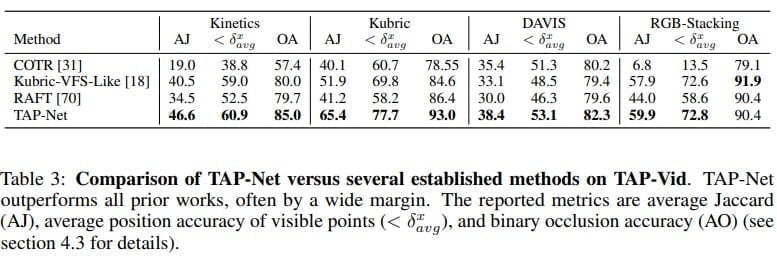
Die Datensätze Kinetics, DAVIS und RGB-stacking sowie das Modell TAP-Net sind bei Github frei verfügbar.