
Deepmind stellt ein neues Forschungs-Framework für KI-Agenten in simulierten Umgebungen wie Videospielen vor, die flexibler und natürlicher mit Menschen interagieren können.
KI-Systeme konnten in Videospielen wie Dota oder Starcraft große Erfolge verbuchen, indem sie menschliche Profi-Spieler:innen besiegten. Möglich ist das durch präzise Belohnungsfunktionen, die auf die Optimierung des Spielergebnisses abgestimmt sind: Die Agenten wurden anhand der vom Computercode berechneten eindeutigen Gewinne und Verluste trainiert. Dort, wo solche Belohnungsfunktionen möglich sind, können KI-Agenten teils übermenschliche Leistungen erreichen.
Doch in vielen Fällen - besonders in dem offenen Verhalten, das Menschen in alltäglichen Interaktionen meistern - gibt es eine solche präzise Belohnungsfunktion nicht. Damit ein KI-Agent die Fähigkeit hätte, etwa "eine Tasse in der Nähe abzustellen", müsste er mit der Vielfalt an Möglichkeiten umgehen können: So gibt es verschiedene sprachliche Formulierungen der gleichen Bitte, sprachimmanente Unklarheiten (Was ist "Nähe"?), irrelevante Faktoren (die Farbe der Tasse etwa) und viele verschiedene Möglichkeiten, die Bitte zu erfüllen.
Deepmind will natürlicher Interaktion zwischen Mensch und KI-Agenten fördern
Forschenden von Deepmind stellen nun ein neues Lern- und Trainingsparadigma vor, das helfen soll, Agenten zu entwickeln, die auf solch natürliche Weise mit Menschen interagieren und von ihnen lernen können.
Deepmind setzt dafür auf Menschen, die sich Aufgaben ausdenken, die KI-Agenten in simulierten Umgebungen durchführen müssen. Die dabei entstehenden Daten verwendet Deepmind für die Optimierung der Agenten. Diese mit menschlichem Feedback trainierten Agenten können laut Deepmind "unscharfe menschliche Konzepte" besser verstehen und "fundierte und ergebnisoffene" Interaktionen mit Menschen haben.
Dieses Paradigma steckt zwar noch in den Kinderschuhen, aber es ermöglicht Agenten, die zuhören, sprechen, Fragen stellen, navigieren, suchen und abrufen, Objekte manipulieren und viele andere Aktivitäten in Echtzeit durchführen können.
Deepmind
Im interaktiven Spielhaus lernen KI-Agenten von Menschen
Für das neue Forschungs-Framework entwickelte Deepmind ein 3D-Spielhaus, indem sich die KI-Agenten und menschliche Nutzer:innen als Avatare frei bewegen und miteinander interagieren und kooperieren können.
Der Austausch zwischen Menschen und Avataren erfolgte per natürlicher Sprache in einem Chat. Dabei setzten die Menschen den Kontext, indem sie den Agenten Aufgaben oder Fragen stellten. Das folgende Video zeigt einige dieser Aufgaben und wie (bereits trainierte) KI-Agenten sie lösen.
In der Spielhaus-Umgebung sammelte das Forschungsteam zudem Interaktionsdaten für das Training mit Reinforcement Learning. Laut Deepmind umfasst der generierte Datensatz 25 Jahre Echtzeit-Interaktionen zwischen Agenten und Hunderten von Menschen.
Vom Menschen lernen heißt für Menschen lernen
Für die fortschrittlichen KI-Agenten klonte Deepmind zunächst das Verhalten und die Interaktionen menschlicher Nutzer:innen im Spielhaus. Ohne dieses Vorabtraining würden die KI-Agenten ansonsten nur zufällig und für Menschen nicht nachvollziehbar handeln, schreibt Deepmind.

Dieses initiale Verhalten wurde dann durch menschliches Feedback in Verbindung mit Reinforcement Learning nach dem klassischen Versuch-und-Irrtum-Prinzip optimiert. Allerdings erfolgte die Belohnung oder Bestrafung nicht anhand einer Punktzahl, sondern Menschen bewerten, ob die Aktionen zur Zielerfüllung beiträgt.
Mit diesen Interaktionen trainierte Deepmind wiederum ein Belohnungsmodell, das menschliche Präferenzen vorhersagen kann. Dieses Belohnungsmodell diente dann als Feedback-Mechanismus für die weitere Optimierung der Agenten per Reinforcement Learning.
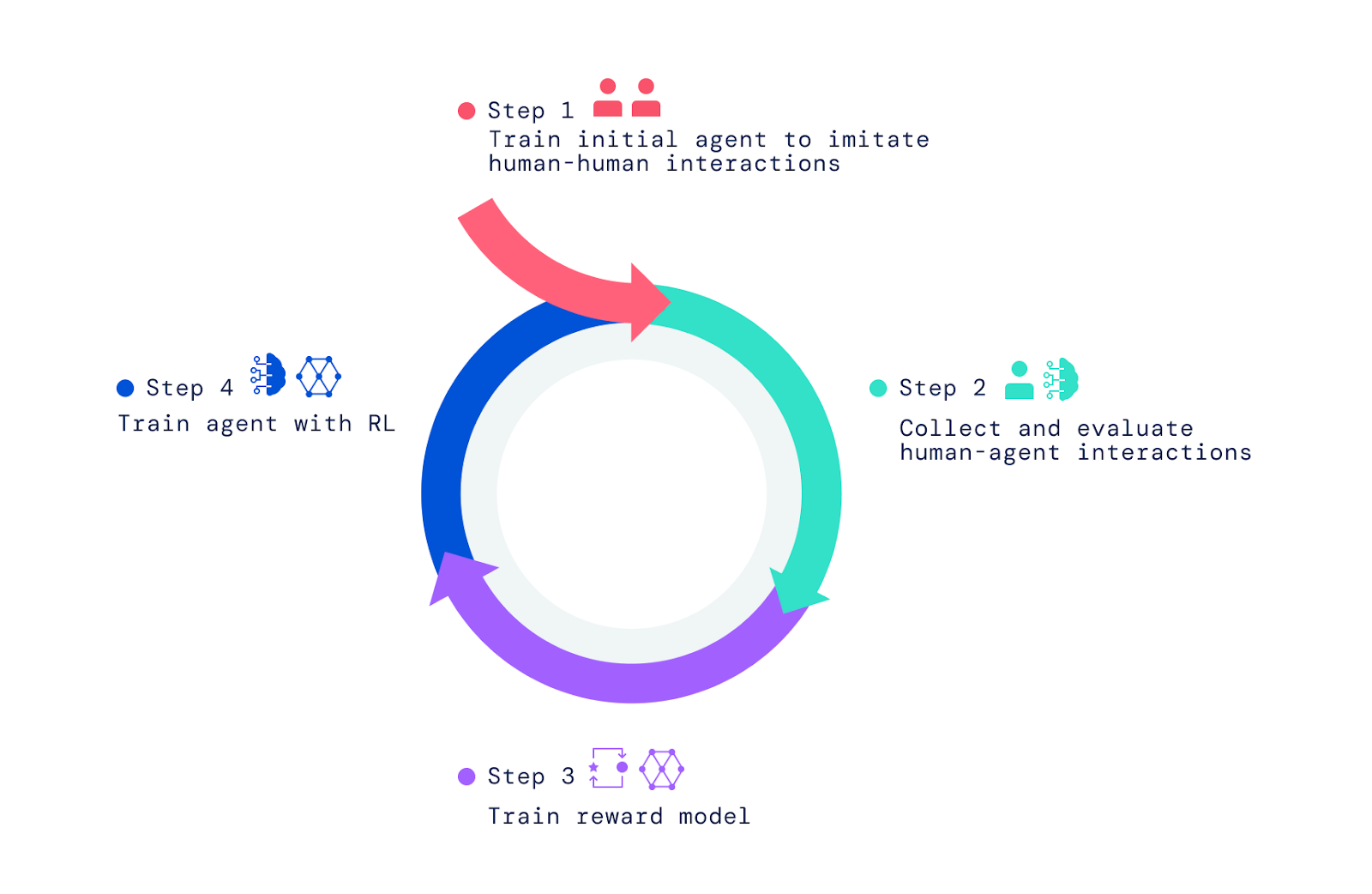
Die Aufgaben und Fragen für den Lernprozess stammten von Menschen und zusätzlich von Agenten, die menschliche Aufgaben und Fragen imitierten: Ein Agent stellte Fragen und Aufgaben, der andere reagierte darauf.
Vielfältige und überraschende Verhaltensweisen
Laut Deepmind können die mit menschlichem Feedback trainierten Agenten eine Vielzahl von Aufgaben lösen, die vom Team selbst nicht vorhergesehen wurden. Sie reihten etwa Objekte anhand von zwei sich abwechselnder Farben aneinander oder brachten Nutzer:innen ein ähnliches Objekt passend zu dem, das diese in der Hand hielten.
Diese Überraschungen entstehen, weil die Sprache durch die Zusammensetzung einfacher Bedeutungen eine schier endlose Reihe von Aufgaben und Fragen ermöglicht. Außerdem legen wir als Forscher die Details des Agentenverhaltens nicht fest. Stattdessen haben sich die Hunderte von Menschen, die an Interaktionen beteiligt sind, im Laufe dieser Interaktionen Aufgaben und Fragen ausgedacht.
Deepmind
Bei der Evaluation mit menschlichen Nutzer:innen schnitten mit Imitationslernen und Reinforcement Learning trainierte KI-Agenten signifikant besser ab als Agenten, die nur die Imitation beherrschten.
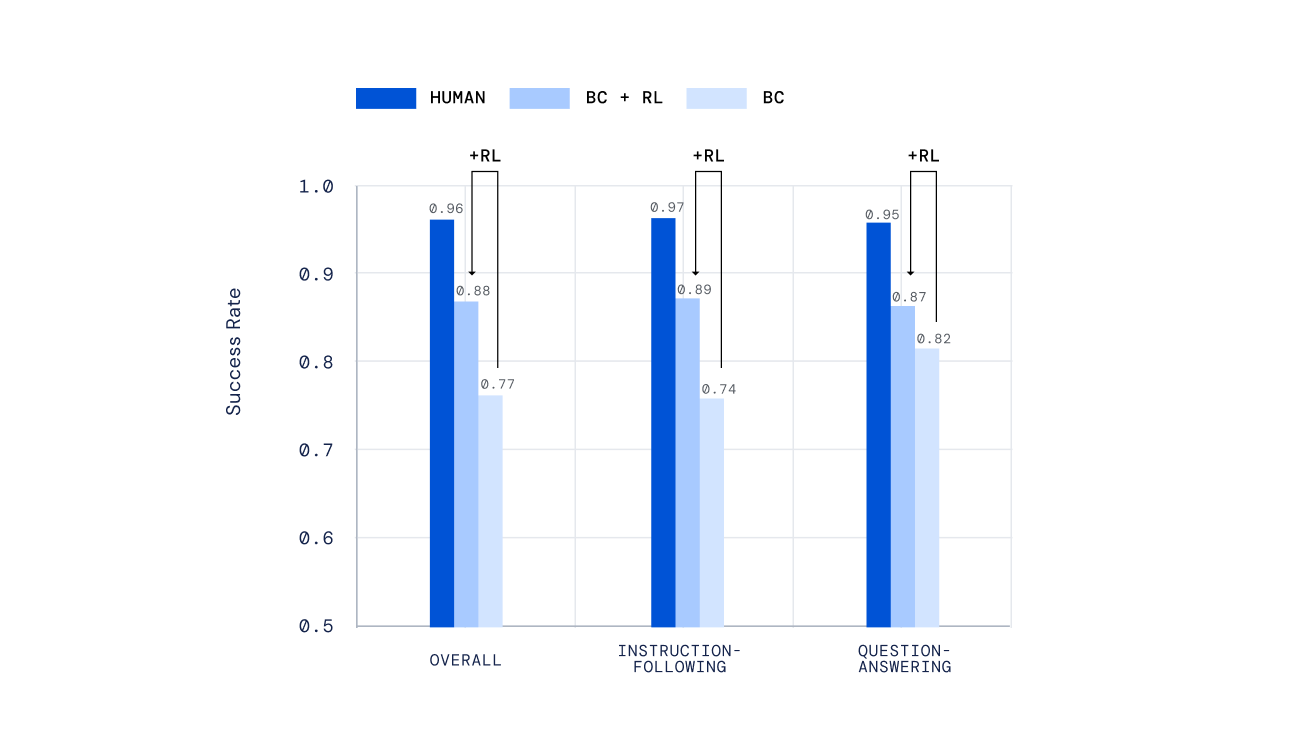
Der Trainingsprozess könne zudem mehrfach durchlaufen werden, um die Agenten mit einem aktualisierten Belohnungsmodell weiter zu optimieren. Auf diese Art trainierte Agenten konnten bei einigen komplexen Instruktionen die Leistung menschlicher Nutzer:innen sogar durchschnittlich übertreffen.
Das vorgestellte Framework sieht Deepmind als Beitrag zur Entwicklung von KI-Agenten, die in Videospielen natürlicher mit Menschen interagieren können, anstatt nur entlang vorprogrammierter Verhaltensweisen zu agieren. Das Framework könne zudem bei der Entwicklung alltagstauglicher digitaler oder robotergestützter Assistenten hilfreich sein.
Der Mensch als Maßstab für maschinelles Verhalten
Die Integration von menschlichem Feedback in das Training von KI-Systemen wird von verschiedenen Institutionen als Möglichkeit gesehen, KI besser auf menschliche Bedürfnisse abzustimmen. Deepmind stellte etwa zuvor einen Chatbot vor, bei dem menschliches Feedback in den Trainingsprozess integriert ist. Das Forschungslabor CarperAI will eine entsprechende Open-Source-Sprach-KI veröffentlichen.
OpenAI sieht menschliches Feedback bei der KI-Entwicklung als zentralen Bestandteil einer positiven Ausrichtung von KI. Mit den Instruct-GPT-Modellen hat OpenAI bereits große Sprachmodelle mit menschlichem Feedback optimiert, die trotz weniger Parameter von Menschen präferierte Texte generieren.




