Deepseek setzt Meta mit Open Source KI-Modellen zu Bruchteil der Kosten unter Druck

Mit seinen hocheffizienten KI-Modellen bringt das chinesische Open-Source-Unternehmen Deepseek die etablierten KI-Labore unter Druck. Meta-CEO Mark Zuckerberg kündigt massive Investitionen an.
Das chinesische KI-Start-up Deepseek zeigt, dass Spitzen-KI auch ohne Milliardenbudget möglich ist. Sein Sprachmodell Deepseek-V3 erreichte in unabhängigen Tests eine vergleichbare Leistung wie die weltweit führenden KI-Modelle - und das für nur 5,6 Millionen Dollar reine Trainingskosten.
Für das Training von Deepseek-V3 wurden laut Deepseek nur 2,78 Millionen GPU-Stunden benötigt. Zum Vergleich: Meta benötigte für sein kleineres Llama-3-Modell mit 405 Milliarden Parametern etwa elfmal so viele GPU-Stunden.
Kurz nach Deepseek-V3 erschien mit Deepseek-R1 ein Reasoning-Modell, das mit OpenAIs o1 mithalten kann. Ein solches Modell hat Meta bislang nicht einmal am Markt. Deepseeks Kosteneffizienz setzt die etablierten KI-Labore unter Druck.
Zuckerberg kündigt weitere Milliardeninvestitionen an
Jetzt positioniert sich Metas Führungsspitze. 2025 will Meta das führende KI-Assistenzmodell für mehr als eine Milliarde Menschen entwickeln, Llama 4 zum State-of-the-Art-Modell ausbauen und einen KI-Ingenieur schaffen, der zunehmend zur eigenen Forschung und Entwicklung beiträgt, schreibt Meta-CEO Mark Zuckerberg bei Facebook
Dafür baut Meta laut Zuckerberg ein riesiges Rechenzentrum mit mehr als zwei Gigawatt Leistung. Allein 2025 sollen rund ein Gigawatt Rechenleistung und über 1,3 Millionen GPUs in Betrieb gehen. Meta plant Investitionen von 60 bis 65 Milliarden Dollar und will seine KI-Teams deutlich vergrößern.
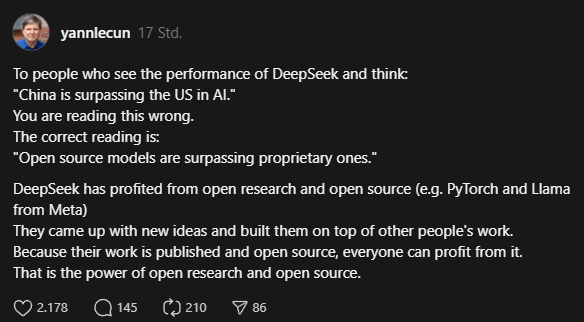
Metas KI-Chefforscher Yann LeCun sieht in Deepseeks Erfolg keinen Beleg für eine Überlegenheit Chinas, sondern für die Stärke von Open Source. Deepseek habe von offener Forschung und Open Source profitiert und darauf aufbauend neue Ideen entwickelt. Bei der Veröffentlichung von Deepseek-V3 Ende 2024 bezeichnete LeCun das Modell als "exzellent".
Gerüchte über Unruhe in Metas KI-Abteilung
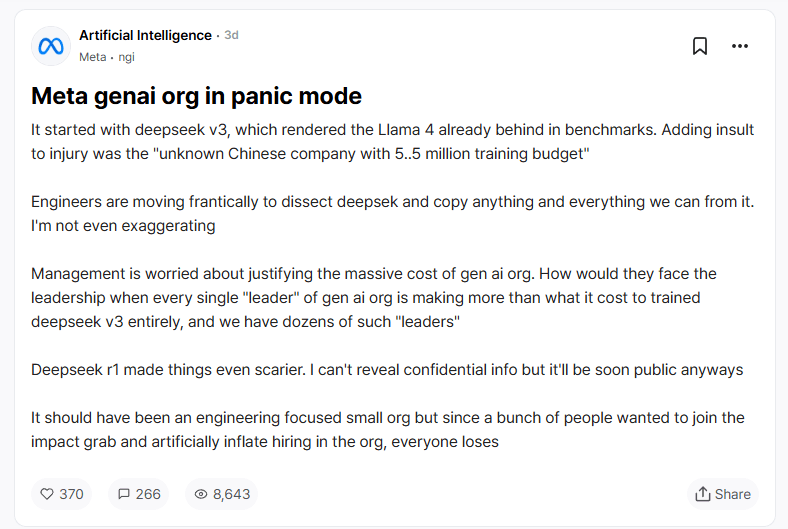
Laut eines anonymen Beitrags auf der Plattform Teamblind, einem Forum für verifizierte Big-Tech-Mitarbeitende, herrscht bei Metas Generative-AI-Abteilung Alarmstimmung. Auslöser sei eben Deepseek-v3, das Metas unveröffentlichtes Llama-4-Modell in Benchmarks bereits überholt habe - und das zu einem Bruchteil der Kosten.
Meta-Ingenieure würden fieberhaft daran arbeiten, die Technologie zu analysieren und möglichst viel davon zu übernehmen. Das Management sei besorgt, die massiven Kosten der Generative-AI-Abteilung zu rechtfertigen, wenn ein "unbekanntes chinesisches Unternehmen mit einem Trainingsbudget von 5,5 Millionen Dollar" bessere Ergebnisse erzielt.
Jeder einzelne "Leiter" der Abteilung verdiene mehr, als das gesamte Training von Deepseek-V3 gekostet habe. Noch beunruhigender für Meta sei das Reasoning-Modell Deepseek-R1. Er kritisiert, dass die KI-Abteilung von Meta eigentlich technisch fokussiert und klein sein sollte, stattdessen aber aufgebläht wurde, weil viele Mitarbeiter vom Zukunftsthema KI profitieren wollten. Der Beitrag stellt nur eine Einzelmeinung dar.
Die Aussagen von Zuckerberg und LeCun, die fast zeitgleich veröffentlicht wurden, könnten eine indirekte Reaktion auf diesen Beitrag und die dadurch ausgelöste Diskussion in den sozialen Medien sein.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.