Deepseek V3.2 soll GPT-5 und Gemini 3 Pro Konkurrenz machen
Das chinesische KI-Unternehmen Deepseek hat mit Deepseek V3.2 ein neues Sprachmodell vorgestellt, das in vielen Tests mit GPT-5 mithalten soll. Beim sogenannten "Reasoning" soll es Googles neues Gemini 3 Pro übertreffen.
Die Deepseek-Forscher haben drei zentrale Schwächen aktueller Open-Source-Modelle identifiziert: ineffiziente Verarbeitung langer Texte, zu geringe Investitionen ins Posttraining und schwache Fähigkeiten bei autonomen Agentenaufgaben.
Deepseek V3.2 soll diese Probleme durch eine neue Aufmerksamkeitsarchitektur und ein deutlich skaliertes Posttraining lösen, wie der nun veröffentlichte technische Bericht zu V3.2 ausführt. Im September hatte Deepseek bereits eine vorläufige Version unter dem Namen V3.2-Exp vorgestellt.
Deepseek setzt erneut auf innovative Architektur
Die zentrale Neuerung heißt Deepseek Sparse Attention (DSA). Herkömmliche Sprachmodelle prüfen bei jeder Antwort erneut alle vorherigen Tokens. Das ist bei langen Gesprächen sehr rechenintensiv. DSA macht es anders: Ein kleines Indexierungssystem bewertet zuerst, welche früheren Textteile wichtig sind. Das Modell berücksichtigt danach nur diese als relevant eingestuften Abschnitte.
Statt alles noch einmal zu lesen, liest das Modell nur das Wesentliche. Laut Deepseek sinkt dadurch der nötige Rechenaufwand deutlich, ohne dass die Antwortqualität leidet. Außerdem berichtet Deepseek von einer spürbaren Gesamtbeschleunigung bei sehr langen Eingaben, ohne aber konkrete Zahlen zu nennen.
Post-Trainingsbudget massiv erhöht
Deepseek hat nach eigenen Angaben die Investitionen ins Posttraining deutlich erhöht. Das Budget für diese Phase, also Verstärkungslernen und Alignment nach dem Pretraining, übersteigt zehn Prozent der ursprünglichen Pretraining-Kosten. Vor zwei Jahren lag es eher bei rund einem Prozent.
Für die Datenbasis entwickelten die Forscher zunächst spezialisierte Modelle in sechs Bereichen: Mathematik, Programmierung, allgemeines logisches Reasoning, allgemeine Agentenaufgaben, agentisches Coding und agentische Suche. Diese Spezialisten erzeugten Trainingsdaten für das finale Modell. Für das Training autonomer Agenten baute Deepseek zusätzlich 1.827 synthetische Aufgabenumgebungen mit insgesamt 4.417 komplexen Szenarien sowie zehntausende ausführbare Umgebungen aus echten GitHub-Issues.
Performance vergleichbar mit GPT-5
Bei AIME 2025, einem anspruchsvollen Mathematik-Wettbewerb, erreicht Deepseek V3.2 eine Erfolgsquote von 93,1 Prozent. GPT-5 (High) liegt mit 94,6 Prozent knapp darüber, allerdings hat OpenAI mit GPT-5.1 sowie den Codex-Modellen inzwischen leicht weiterentwickelte Modelle im Portfolio.
Bei LiveCodeBench, einem Benchmark für Programmieraufgaben, erzielt Deepseek 83,3 Prozent, wieder knapp hinter GPT-5 mit 84,5 Prozent. Googles Gemini 3 Pro bleibt allerdings in den meisten Tests führend mit 95,0 Prozent bei AIME und 90,7 Prozent bei LiveCodeBench.
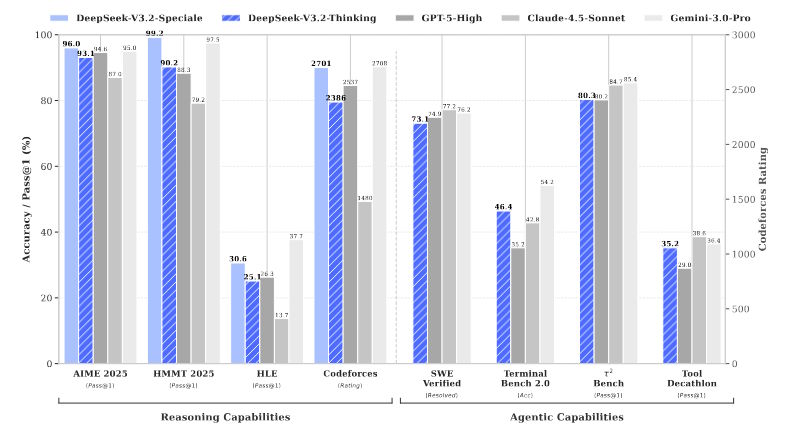
Bei praktischen Aufgaben zeigt Deepseek starke Ergebnisse. Bei SWE Multilingual, einem Test für mehrsprachige Software-Entwicklung mit echten GitHub-Problemen, löst das Modell 70,2 Prozent der Issues. GPT-5 erreicht 55,3 Prozent. Im Benchmark Terminal Bench 2.0 liegt Deepseek mit 46,4 Prozent vor GPT-5 mit 35,2 Prozent, aber hinter Gemini 3 Pro mit 54,2 Prozent.
Speciale-Variante erreicht Olympiaden-Niveau
Parallel entwickelte Deepseek eine experimentelle Variante namens Deepseek V3.2 Speciale, die die Längenbeschränkungen für Reasoning- und Antwortketten lockert. In offiziellen Wettbewerbstests wurde jedoch eine maximale Generationslänge von 128 000 Tokens verwendet.
Bei der International Olympiad in Informatics 2025 erreichte Speciale Goldniveau und landete auf Rang 10. Beim ICPC World Final 2025, der Weltmeisterschaft im Wettbewerbsprogrammieren, erreichte das Modell Rang 2 mit Gold. Auch bei der International Mathematical Olympiad 2025 erzielte Speciale durch Integrationen von Komponenten aus dem spezialisierten DeepSeek-Math-V2 Goldniveau.
Die Leistung ist mit Gemini 3 Pro vergleichbar. Allerdings benötigt Speciale deutlich mehr Tokens. Bei Codeforces sind es im Mittel 77 000 gegenüber 22 000 bei Gemini. Wegen der Kosten und der Latenz entwickelte Deepseek die Standardversion V3.2 mit strengeren Tokenbeschränkungen.
Das ist womöglich eine große Sache. Sowohl OpenAI als auch Google DeepMind kündigten diesen Sommer Modelle an, die dieses Niveau erreichen können – etwas, das viele Forscher bei reinen Sprachmodellen für unmöglich hielten. Deepseek hat nun mit dieser Leistung gleichgezogen, ist beiden Unternehmen bei der Veröffentlichung zuvorgekommen und hat das Modell als Open Source veröffentlicht. OpenAI hat lediglich erklärt, dass eine verbesserte Version seines Mathematik-Modells in den nächsten Monaten erscheinen wird.
Deepseek will mehr aus dem Pretraining rausholen
Deepseek benennt drei zentrale Schwächen gegenüber kommerziellen Frontier-Modellen: Die Wissensbreite ist geringer, die Token-Effizienz muss verbessert werden, und die Performance bei den komplexesten Aufgaben bleibt hinter proprietären Systemen zurück. Die Forscher planen, die Wissenslücke durch mehr Pretraining zu schließen, einer Strategie, die vor einem Jahr eigentlich noch in eine Sackgasse zu führen schien.
Das Modell steht unter der Apache‑2.0‑Lizenz auf Hugging Face zur Verfügung und wird zusätzlich über eine API angeboten. Damit schickt Deepseek ein weiteres System in den Preiskampf mit Konkurrenten wie OpenAI. Vor allem in agentischen Szenarien, in denen Sprachmodelle mit Werkzeugen interagieren müssen, könnte Deepseek‑V3.2 eine besonders kostengünstige Alternative sein und den Druck auf das ohnehin schon finanziell belastete US-Unternehmen weiter erhöhen. Beim Umgang mit den zunehmend verbreiteten MCP‑Servern schneidet Deepseek‑V3.2 zudem besser ab als andere Open‑Weight‑Schwergewichte wie Kimi K2 Thinking und MiniMax M2.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.