Deepseek neuestes Open-Source-Sprachmodell konkurriert mit GPT-4.5
Update –
DeepSeek-V3-0324 ergänzt
Deepseek aus China hat eine neue Version von DeepSeek-V3 unter MIT-Lizenz veröffentlicht - und die macht den besten Modellen ernsthafte Konkurrenz.
Deepseek-V3-0324 zeigt deutliche Verbesserungen bei mathematischen Tests wie MMLU-Pro, vGPQA und AIME und übertrifft in einigen dieser Benchmarks die derzeit stärksten reinen LLMs wie OpenAIs GPT-4.5 oder Anthropics Claude 3.7 Sonnet. Auch die Webentwicklung und die Sprachfähigkeiten für Chinesisch wurden verbessert.
Im unabhängigen Polyglot-Benchmark erreicht das Modell 55 Prozent und liegt damit auf Platz 2 der Modelle ohne spezielle "Thinking"-Fähigkeiten. Die Vorgängerversion diente als Grundlage für Deepseeks R1 Reasoning-Modell, das als erstes Open-Source-Modell mit OpenAIs o1 konkurrieren konnte und in den Tagen nach seiner Veröffentlichung den US-Aktienmarkt in Aufruhr versetzte.
Die neue Version von V3 könnte als Basis für R2 dienen und damit einen ersten Ausblick auf die zu erwartenden Leistungssprünge geben.
Ursprünglicher Artikel vom 27. Dezember 2025:
Das chinesische Start-up Deepseek beweist, dass Spitzen-KI auch ohne Milliardenbudget möglich ist. Sein neues Sprachmodell kann es mit den Besten aufnehmen - zu einem Bruchteil der üblichen Kosten.
Deepseeks neues Sprachmodell v3 kann laut einer unabhängigen Analyse von Artificial Analysis mit den weltweit führenden KI-Modellen konkurrieren - und das für nur 5,6 Millionen Dollar reine Trainingskosten.
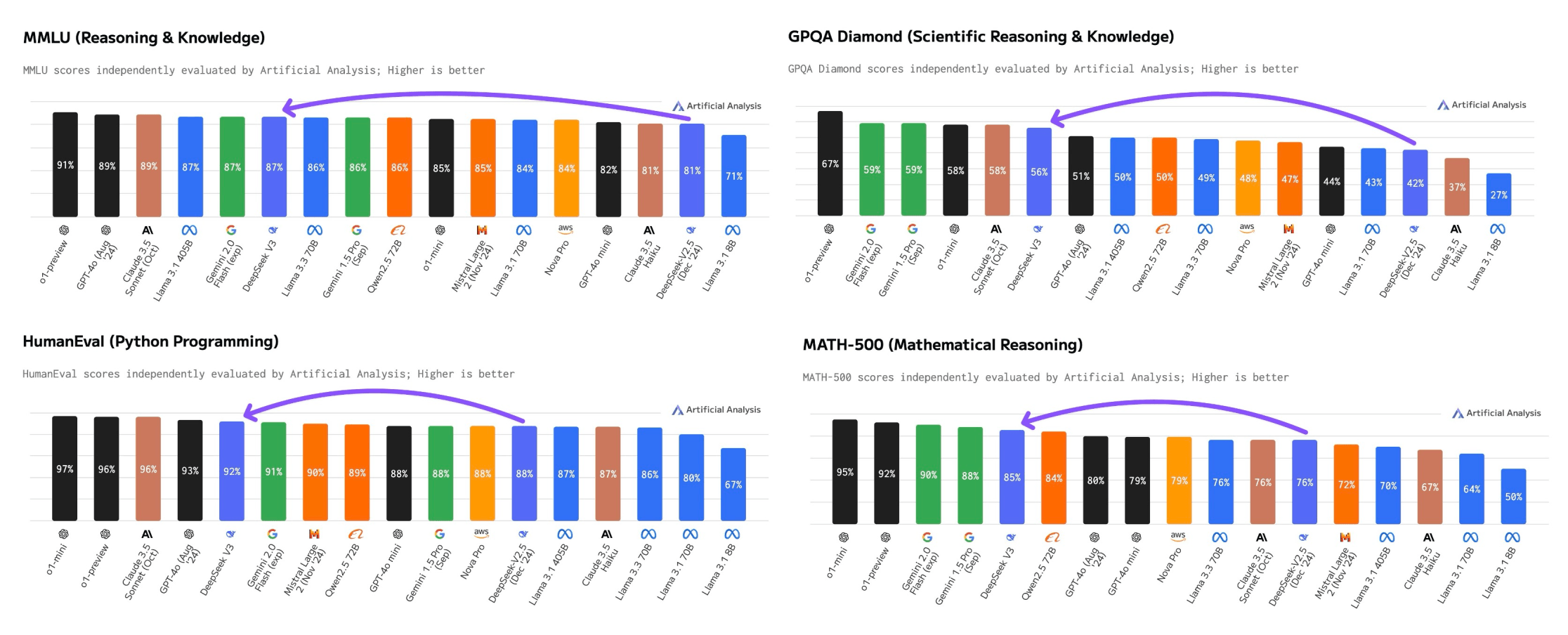
Das Modell übertrifft nach Angaben von Artificial Analysis alle bisher veröffentlichten Open-Source-Modelle und erreicht im "Quality Index", der verschiedene Benchmarks kombiniert, nahezu die Leistung von Anthropics Claude 3.5 Sonnet. Lediglich die Google Gemini-Modelle und OpenAIs o-Modelle liegen noch vor Deepseek-V3.

Vor allem bei technischen Aufgaben zeigt das System Stärken: Beim HumanEval-Benchmark für Programmierung erreicht es 92 Prozent, beim MATH-500-Test für mathematisches Denken 85 Prozent. Selbst Metas KI-Chefforscher Yann LeCun bezeichnet das Modell als "exzellent".
Den Fortschritt speziell bei Schlussfolgerungen erzielte Deepseek anhand von Daten seines Ende November vorgestellten Reasoning-Modells R1.
Wie üblich gilt jedoch: Benchmarks sind nicht die Praxis. Deepseek-V3 wird sich in realen Anwendungsszenarien erst beweisen müssen. Dennoch begeistern die guten Benchmarkergebnisse in Kombination mit den geringen Trainingskosten und der ausführlichen Erklärung im technischen Bericht derzeit die KI-Fachwelt.
Deutlich effizienter als die Konkurrenz
Für das Training des Mixture-of-Experts-Modells mit 671 Milliarden Parametern wurden nach Unternehmensangaben nur 2,78 Millionen GPU-Stunden auf NVIDIA H800-GPUs benötigt.
Zum Vergleich: Meta benötigte für sein kleineres Llama-3-Modell mit 405 Milliarden Parametern etwa elfmal so viele GPU-Stunden (30,8 Millionen).
KI-Experte Andrej Karpathy hebt diese bemerkenswerte Effizienz hervor: Üblicherweise würden für Modelle der Deepseek-V3 Leistungsklasse Cluster mit 16.000 bis 100.000 GPUs benötigt. Das chinesische Start-up hingegen nutzte nur 2.048 GPUs über einen Zeitraum von 57 Tagen.
Das Budget sei für ein Modell dieser Klasse "ein Witz", so Karpathy. Die Entwicklung zeige vor allem, wie wichtig die effiziente Nutzung der vorhandenen Ressourcen sei - und dass es noch viel Optimierungspotenzial bei Daten und Algorithmen gebe. Große GPU-Cluster für Frontier-Modelle seien aber nach wie vor notwendig.

Laut technischem Bericht führt Deepseek die enormen Effizienzgewinne auf ein Co-Design von Algorithmen, Frameworks und Hardware zurück. Dazu war das Unternehmen gezwungen. Denn als chinesisches Start-up hat Deepseek aufgrund von US-Exportbeschränkungen nur begrenzten Zugang zu den neuesten Nvidia-Chips.
Die für das Training verwendeten H800-GPUs - von Nvidia speziell für den chinesischen Markt in ihrer Leistung limitierte Chips - haben eine deutlich geringere GPU-Verbindungsbandbreite als die in westlichen Labors verwendeten H100-Chips. Deepseek hat daher eigene Optimierungen für die Prozessorkommunikation entwickelt, anstatt auf vorgefertigte Lösungen zurückzugreifen - ein Beispiel für Effizienzsteigerungen auf der Softwareseite.
Preisdruck auf etablierte Anbieter
Die niedrigen Entwicklungskosten und aggressive Preispolitik von Deepseek setzen die etablierten KI-Labore unter Druck. Während Unternehmen wie OpenAI noch Milliardenverluste schreiben, bietet Deepseek sein Spitzenmodell deutlich günstiger und sogar als Open Source an.
Nach Angaben von Artificial Analysis ist Deepseek-V3 zwar etwas teurer als OpenAIs Sparmodell GPT-4o-mini oder Googles Gemini 1.5 Flash, aber deutlich günstiger als andere Spitzenmodelle mit vergleichbarer Leistung. Mit einem automatischen 90-Prozent-Rabatt für zwischengespeicherte Anfragen (Prompt Caching) sei es derzeit das kosteneffizienteste Modell seiner Klasse.
Die Preise pro Million Token sind im Vergleich zum Vorgänger Deepseek v2.5 zwar gestiegen - bei der Eingabe um das Doppelte auf 0,27 Dollar und bei der Ausgabe um das Vierfache auf 1,10 Dollar. Das Unternehmen bietet sein neues Modell aber noch bis Anfang Februar zum Preis des Vorgängers an. Kostenlos testen kann man V3 auf Deepseeks eigener Chat-Plattform.
Weniger Ressourcen zwingen zu Innovation
Die Entwicklung von Deepseek-V3 zeigt einen interessanten Nebeneffekt der US-Exportbeschränkungen: Die technischen Limitierungen zwangen das Unternehmen zu softwareseitigen Innovationen, um die verfügbare Hardware optimal zu nutzen.
Diese Erkenntnis könnte auch für die europäische KI-Entwicklung wegweisend sein: Spitzen-KI ist offenbar auch ohne die größten GPU-Cluster möglich, wenn die vorhandenen Ressourcen optimal genutzt werden.
Das bedeutet jedoch nicht das Ende der großen Rechenzentren. Die KI-Industrie konzentriert sich zunehmend auf die Skalierung der Inferenzzeit, also der Zeit, die ein Modell erhält, um Antworten zu generieren. Wenn dieses Skalierungsprinzip erfolgreich ist, werden weiterhin große Rechenkapazitäten benötigt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.