Googles neue KI versteht das Licht

Google forscht an der digitalen Rekonstruktion der echten Welt. Eine neue KI kann anhand von Fotos neue Ansichten bis hin zu hochauflösenden 3D-Modellen generieren. Die Grundlage ist ein Verständnis der KI für Licht.
Wer schon einmal Städte in Google Maps oder Earth erkundet hat, kennt die 3D-Modelle berühmter Gebäude. Sie werden häufig von Modellierern in ihrer Freizeit nachgebaut und über Googles 2006 gegründetes 3D-Warehouse in der digitalen Welt verteilt. Durch das Crowdsourcing konnte Google Earth schnell Sehenswürdigkeiten in vielen Städten in 3D darstellen.
Doch dem Arbeitsvermögen der Hobby-Modellierer sind Grenzen gesetzt. Um die Realität beinahe vollständig und detailgetreu in die virtuelle Welt zu überführen, braucht es automatisierte Techniken.
Seit einigen Jahren setzt Google auf Künstliche Intelligenz und Photogrammetriedaten, die Tiefeninformationen mit Texturen zu 3D-Modellen verbinden. Dafür nutzt Google primär Satelliten- und Luftbilder.
Diese Technik ist die Grundlage der 3D-Welt, die VR-Nutzer in Google Earth VR besonders eindrucksvoll besuchen können.
Photogrammetrie oder KI?
Wer sich schon einmal in der virtuellen Realität in New York gestellt hat, weiß auch, dass der aktuelle Ansatz Grenzen hat: Die Satelliten- und Luftbilder sind nicht detailliert genug, um hochauflösende, realistische 3D-Modelle zu erzeugen.
Die Alternative: Per Photogrammetrie können mit Nahaufnahmen von Objekten fotorealistische 3D-Umgebungen erstellt werden. Das zeigen Projekte wie Blueplanet VR (Test), The Homestead (Test) und andere VR-Reisen. Doch der Prozess ist zeit- und kostenintensiv.
Google müsste hunderte oder gar tausende Fotos aus unterschiedlichen Blickwinkeln für jedes Objekt machen und zusammenführen. Das wäre selbst für den Tech-Giganten eine Mammutaufgabe in ungeahntem Ausmaß.
Mehr Daten, mehr Details
Doch es existiert eine Abkürzung: Das Internet ist voller Fotos von Straßenzügen, Naturaufnahmen und Sehenswürdigkeiten. Was bislang noch fehlte, ist eine KI, die all diese visuellen Informationen wieder zu einer virtuellen Welt zusammenführt, die der Realität entspricht.
Google arbeitet daher an der sogenannten „Neural Radiance Fields“-Methode (NeRF), die einen solchen KI-Prozess ermöglichen soll. Mit NeRF kann ein neuronales Netzwerk 3D-Tiefendaten aus 2D-Bildern wie Fotos extrahieren, indem es erkennt, wo Lichtstrahlen enden. Aus diesen Informationen kann die NeRF-KI dann texturierte 3D-Modelle erstellen.
NeRF produziert beeindruckende Ergebnisse – hat aber einen Nachteil: Alle Fotos müssen bei gleichen Bedingungen geschossen werden.
Ändern sich die Lichtverhältnisse oder Personen stehen im Weg, führt das zu Farbveränderungen der 3D-Rekonstruktion oder schemenhaften Verzerrungen. NeRF ist daher nicht für den Einsatz mit Internetfotos geeignet.
Verbesserte KI-Methode versteht das Licht
Jetzt veröffentlicht Google den Nachfolger NeRF-in-the-Wild (NeRF-W). Die neue KI bügelt die größte Schwäche von NeRF aus, indem sie lernt, welche Details sich in Fotos ändern, etwa Lichtverhältnisse, Personen, Fahnen oder Schilder, und welche gleichbleiben, wie die Architektur einer Sehenswürdigkeit.
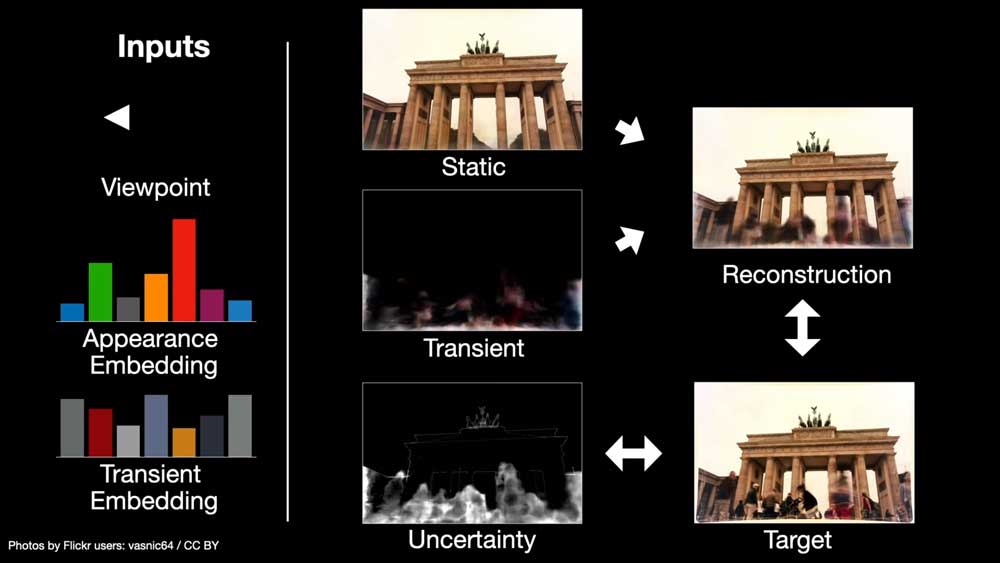
Da die KI lernt, statische und veränderliche Details auf Fotos auseinanderzuhalten, kann sie anschließend neue Ansichten der statischen Strukturen wie eines Gebäudes rekonstruieren.
Mehr noch: Die KI-Forscher können Details wie Lichtverhältnisse auf dem generierten Bild gezielt steuern. Während die Vorgänger-KI eine generierte 3D-Szene des Brandenburger Tors je nach Blickwinkel in völlig unterschiedlichen Lichtverhältnissen zeigte, bleiben die von NeRF W generierten Fotos in der gewünschten Tageszeit.

Die wohl bedeutendste Konsequenz der neu gewonnenen Fähigkeit: Googles KI kann jetzt auf die unzähligen Fotos von Sehenswürdigkeiten im Internet zurückgreifen und Menschen im Vordergrund oder variierende Lichtverhältnisse ausblenden.
So kann die KI beispielsweise ein hochauflösendes, fotorealistisches 3D-Modell des Brandenburger Tors ohne Bildfehler generieren. Es braucht also keine aufwendigen Aufnahmetermine mehr, in denen hunderte Fotos im perfekten Licht geschossen werden.
Noch ist die Simulation nicht perfekt
Da nicht jeder Winkel jeder Sehenswürdigkeit fotografiert ist, gibt es noch Unstimmigkeiten auf den generierten Aufnahmen wie verwaschene Ecken oder geometrische Fehler. Das Problem der Rekonstruktion von 3D-Außenszenen aus Bilddaten sei daher noch lange nicht vollständig gelöst, schreiben die Google-Forscher.
Die Methode erfasst selbst kleinste Details des Trevi-Brunnens in Rom.
Doch der hohe Grad der Automatisierung und die schon jetzt hohe Qualität der generierten Bilder zeigt, dass Google auf dem richtigen Weg ist: Mit NeRF-W kann der Tech-Riese unzählige Internetfotos mit den umfangreichen Aufnahmen von Satelliten und Streetview kombinieren. So wird langfristig eine immer bessere 3D-Repräsentation unserer Welt im Digitalen entstehen.
Bis dahin können PC-Spieler die weltschöpferische Kraft von KI in Microsoft neuem Flugsimulator erleben. Auch der Redmonder Softwareriese setzt auf KI-Technologie, um aus Satelliten- und Fotoaufnahmen eine möglichst detailgetreue 3D-Version der Erde nachzubauen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.