ElevenLabs Scribe v2 schlägt Google und OpenAI im neuen Speech-to-Text-Benchmark
Artificial Analysis hat Version 2.0 seines Speech-to-Text-Benchmarks AA-WER veröffentlicht, der die Genauigkeit von Spracherkennungsmodellen misst. Im Gesamtranking führt Scribe v2 von ElevenLabs mit einer Wortfehlerrate von nur 2,3 Prozent. Auf den Plätzen zwei und drei folgen Googles Gemini 3 Pro (2,9 %) und Voxtral Small von Mistral (3,0 %). Auch Gemini 3 Flash von Google (3,1 %) und Scribe v1 von ElevenLabs (3,2 %) schneiden gut ab. Im Mittelfeld landen unter anderem OpenAIs GPT-4o Transcribe (4,0 %) und Whisper Large v3 (4,2 %). Am unteren Ende liegen Modelle wie Qwen3 ASR Flash von Alibaba (5,9 %), Amazons Nova 2 Omni (6,0 %) und Rev AI (6,1 %).
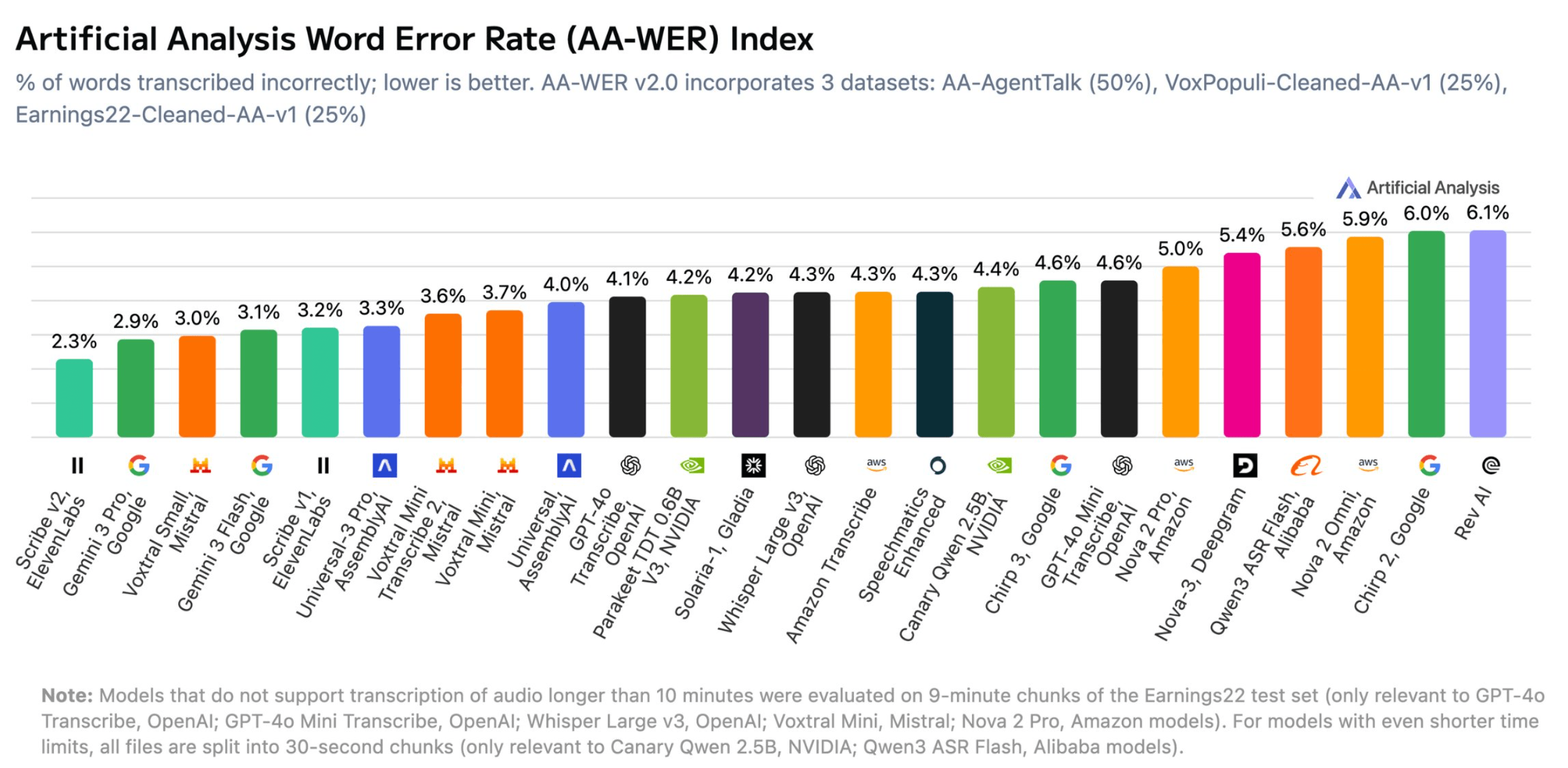
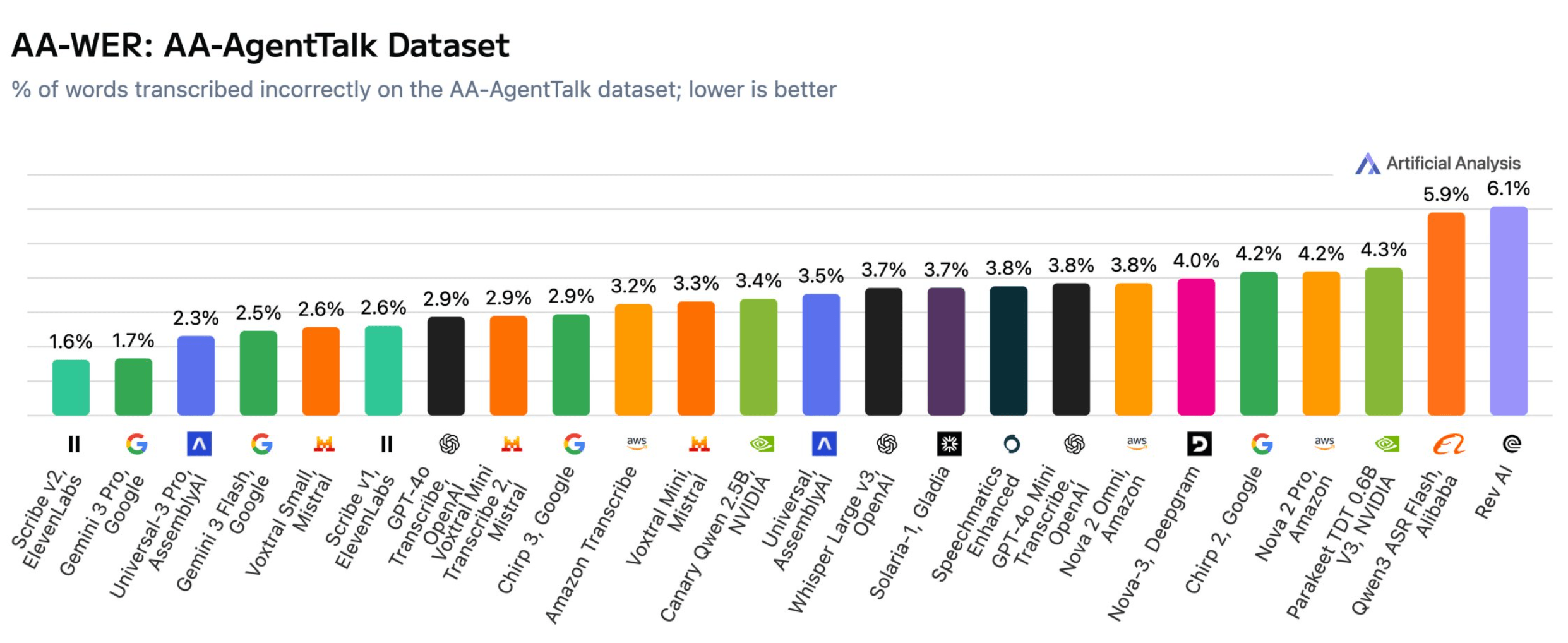
Im separaten Test mit Sprache, die speziell an Sprachassistenten gerichtet ist, bestätigt sich das Bild: Scribe v2 (1,6 %) und Gemini 3 Pro (1,7 %) liegen klar vorn. Universal-3 Pro von AssemblyAI folgt mit 2,3 Prozent auf Platz drei.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren