Facebook-KI erreicht Meilenstein bei der maschinellen Übersetzung

Übersetzungssoftware macht seit der Renaissance neuronaler Netze große Fortschritte. KI-Forscher von Facebook stellen einen neuen Algorithmus vor, der ohne Vorkenntnisse gute Übersetzungen schreibt.
Als Douglas Adams 1979 „Per Anhalter durch die Galaxis“ veröffentlichte, galt der schräge Allesübersetzer „Babelfisch“ noch als Parodie auf in Science-Fiction-Literatur verbreitete Übersetzungsmaschinen.
Mittlerweile ist der Symbiont zu einem Symbol für Übersetzungssysteme geworden, die enorm von maschinellen Lernverfahren profitieren. Doch es gibt deutliche Unterschiede bei der Qualität moderner Übersetzungsalgorithmen.

Lernen mit Daten
Diese Qualitätsunterschiede werden in standardisierten Tests herausgestellt. Am häufigsten wird dazu der Algorithmus „Bilingual Evaluation Understudy“ (BLEU) genutzt.
Er nimmt eine automatische Evaluation der Qualität der maschinellen Übersetzung vor. Dafür vergleicht er das Ergebnis mit menschlichen Referenzübersetzungen. Am Ende steht der BLEU-Score, der über die Qualität der Übersetzung Auskunft gibt.
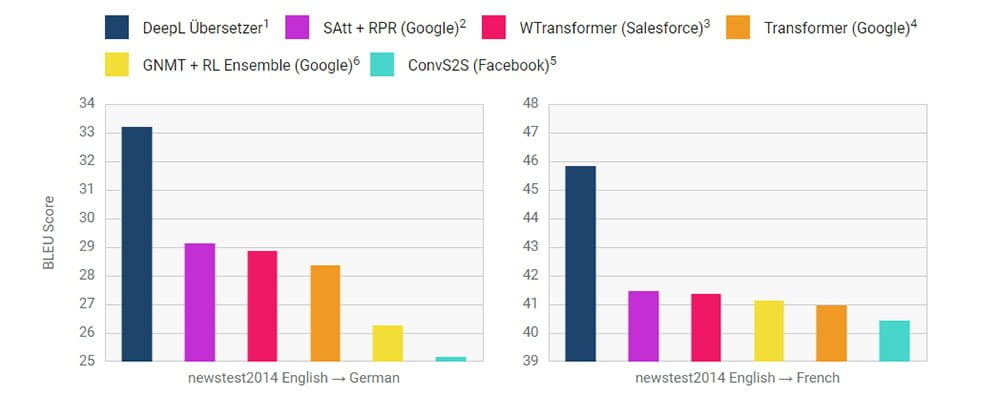
Als Maßstab: Die Google-Forschungsabteilung erreichte in einem Englisch-Deutsch-Test von 2014 einen BLEU-Wert von etwa 29. Im gleichen Test erreichte der Übersetzungsdienst DeepL einen BLEU-Wert von etwa 33.
Moderne Übersetzungssysteme wie DeepL erreichen in bestimmten Sprachen immer häufiger Ergebnisse, die es mit menschlichen Übersetzungen aufnehmen können. Doch der Erfolg dieser Algorithmen beruht auf der Verfügbarkeit großer Mengen paralleler Sätze zweier Sprachen, also Original und Übersetzung.
Da es viele Übersetzungen englischer Werke in die deutsche Sprache und umgekehrt gibt, ist es relativ leicht, dem Algorithmus für diese Sprachen große Datenmengen zur Verfügung zu stellen. Bei vielen anderen Sprachen ist das allerdings nicht möglich.
Facebooks KI braucht keine fertigen Übersetzungen
KI-Forscher von Facebook stellen jetzt eine Methode vor, die qualitativ hochwertige Übersetzungen mit unüberwachtem Lernen ermöglicht. Sie erreichte in den oben genannten Tests einen Wert von 25,2 BLEU-Punkten – elf Punkte mehr als bisherige unüberwachte Versuche.
Beim unüberwachten Lernen ackert sich die Künstliche Intelligenz eigenständig durch große, nicht gekennzeichnete Datenmengen auf der Suche nach Mustern. Das Training der Facebook-KI lässt sich grob in drei Schritte unterteilen:
Der Algorithmus wird zuerst mit unabhängigen, einsprachigen Texten in zwei unterschiedlichen Sprachen gefüttert. Aus diesen Texten leitet die KI ein Regelverständnis für die jeweilige Sprache ab. So entstehen zwei unabhängige Sprachmodelle. Die KI kann danach zum Beispiel falsche Personalpronomen ersetzen und erkennt, wann Indikativ oder Konjunktiv angebracht ist.
Im zweiten Schritt erstellt die KI auf Grundlage der Sprachmodelle erste Übersetzungen. So entstehen für beide Sprachen Übersetzungsmodelle. Da der Algorithmus bis zu diesem Schritt keinerlei Vergleich zu menschlichen Übersetzungen hat, sind die Ergebnisse ziemlich fehlerhaft.
Rückübersetzung als Kontrolle
Im dritten, entscheidenden Schritt übersetzt der Algorithmus daher die ersten Übersetzungsergebnisse zurück in die Ausgangssprache. Diese Rückübersetzung gleicht die KI mit ihrem Sprachmodell ab, das ja anhand eines Originaltextes erstellt wurde. So kann sie Unregelmäßigkeiten feststellen. Wer schon einmal Google Translate die eigene Übersetzung hat übersetzen lassen, weiß, dass das Ergebnis selten etwas mit dem ursprünglichen Satz zu tun hat.
Die KI erkennt so über Umwege, dass ihre erste Übersetzung fehlerhaft ist und verbessert das Übersetzungsmodell. Diesen Prozess führt sie für beide Sprachen parallel durch.
Auf diese Art entwickelt die KI neue Übersetzungsmodelle, deren Ergebnisse immer wieder mit den Sprachmodellen verglichen und verbessert werden. Der dritte Schritt schafft so eine Überwachung im unüberwachten Lernen.

Facebooks Übersetzungs-KI könnte zukünftig helfen, verlorene und seltene Sprachen zu entschlüsseln, weil sie womöglich Muster in Sprachen erkennt, die Forscher übersehen.
Das grundsätzliche Vorgehen beim maschinellen Training könnte auch auf andere Einsatzgebiete angewandt werden: Unüberwachtes Lernen könnte einer Maschine beibringen, einen Hund zu erkennen, ohne dass diese jemals zuvor einen Hund gesehen hat.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.