
Das KI-Framework FinGPT soll den Zugang zu optimierten Sprachmodellen für Finanzaufgaben erleichtern. Es ist als Open Source verfügbar und kann kommerziell genutzt werden.
Mit FinGPT will das Forschungsteam der Columbia University und der New York University (Shanghai) nach eigenen Angaben den Zugang zu finanzmarktoptimierten Sprachmodellen demokratisieren.
Proprietäre Modelle wie BloombergGPT hätten hier den Vorteil, auf exklusive Finanzdaten im eigenen Bestand zugreifen zu können. Zudem sei BloombergGPT mit geschätzten fünf Millionen US-Dollar zu teuer und zu unflexibel im Training.
Stattdessen setzt FinGPT auf Schnittstellen zu vortrainierten Sprachmodellen und der Verfeinerung nach der effizienten Low-Rank-Adaptation-Methode (LoRA). Mit der LoRA-Methode kann die Anzahl der zu adaptierenden Parameter laut des Teams von 6,17 Milliarden auf nur 3,67 Millionen reduziert werden. Dies mache den Feinabstimmungsprozess wesentlich schneller und weniger rechenintensiv, während das Modell weiterhin in der Lage sei, Finanztexte effizient zu verstehen und zu erstellen.
Fokus auf Qualität und Aktualität der Datenpipeline
Der Erfolg eines Finanz-Sprachmodells sei von den Fähigkeiten des Sprachmodells ebenso abhängig wie von der Qualität der Daten, heißt es in dem Forschungspapier. Die Forscherinnen und Forscher sehen FinGPT als direkte Antwort auf BloombergGPT und legen daher besonderen Wert auf die Qualität und Aufbereitung der Daten.
Das Team entwickelte zunächst eine automatisierte Pipeline von kuratierten Finanzdaten hoher Qualität. Dabei greifen sie auf etablierte Quellen wie Yahoo Finance oder Bloomberg zurück, beziehen aber auch Inhalte beispielsweise aus Twitter, Reddit oder SEC-Filings. Hinzu kommen Informationen aus Trendbarometern wie Google Trends und etablierten Datensätzen wie AShare oder Stocknet.
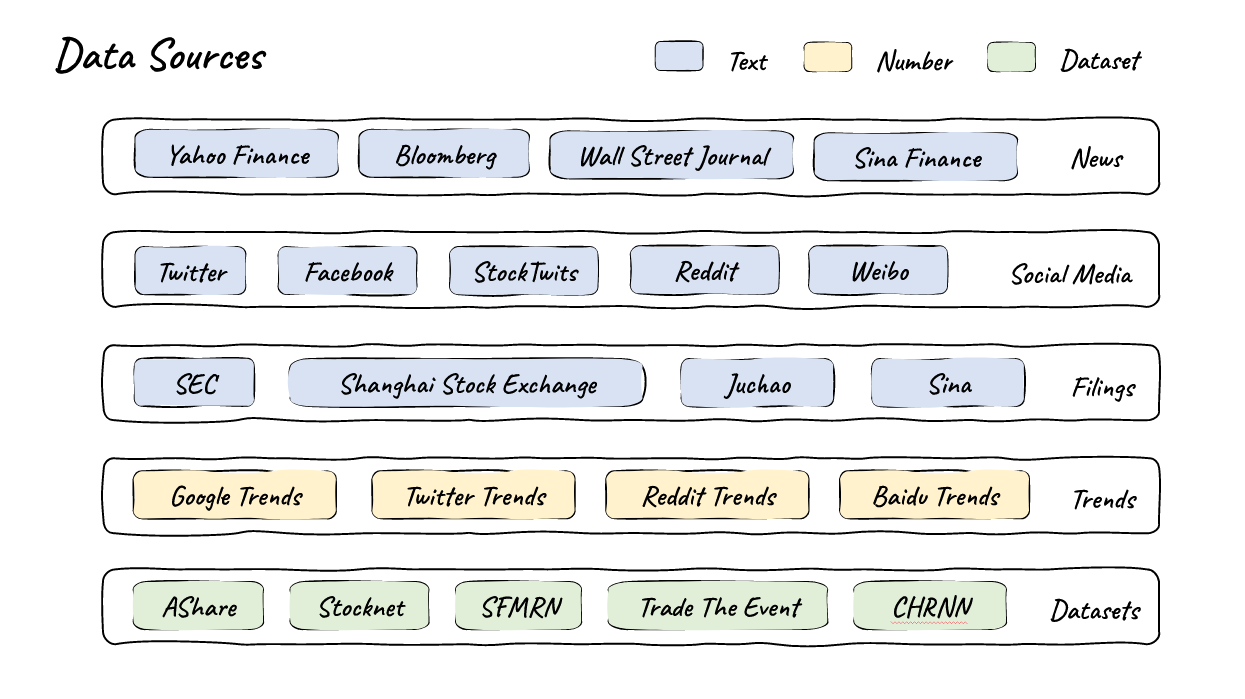
Diese Daten durchlaufen nach Angaben des Teams einen gründlichen Bereinigungs- und Formatierungsprozess, um ihre Qualität und Verwertbarkeit sicherzustellen.
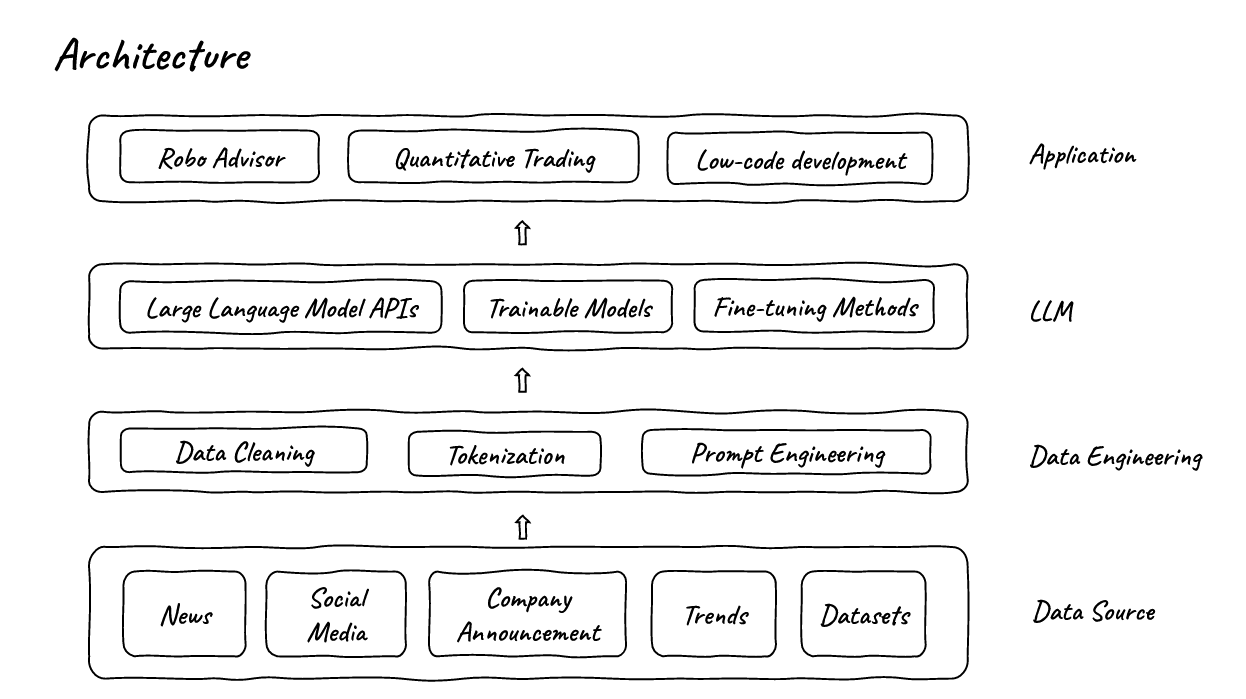
Anschließend können sie auf verschiedene Weise im FinGPT-Framework mit Sprachmodellen verarbeitet werden, zum Beispiel über die Schnittstellen gängiger Anbieter und über trainierbare oder feinabstimmbare Modelle, die je nach gewünschter Anwendung mit eigenen Daten angereichert werden. Da das Feintuning schneller ist als das komplette Training eines Modells, soll FinGPT aktueller und dynamischer sein als BloombergGPT.
Automatisiertes menschliches Feedback über Umwege
Für die Feinabstimmung eines Modells ist in der Regel eine größere Menge qualitativ hochwertiger, markierter Daten erforderlich. Markierte Daten bedeutet, dass die Daten zusätzliche Informationen enthalten, aus denen das Modell lernen kann, zum Beispiel, ob eine Meldung als gut oder schlecht bewertet wird. Diese Art von Daten zu beschaffen kann schwierig und teuer sein, besonders in spezialisierten Bereichen wie dem Finanzsektor.

Deshalb hat das FinGPT-Team eine elegante Methode entwickelt: Anstatt die Daten manuell zu markieren, verwendet es die Reaktionen des Aktienmarktes auf Nachrichten als Marker. Steigt etwa der Aktienkurs nach einer Nachricht, kann diese als "positiv" eingestuft werden.
Die Forscherinnen und Forscher verwendeten Schwellenwerte für die drei Stimmungen: positiv, negativ und neutral. Bei der Feinabstimmung des Modells wird es angewiesen, je nach Nachricht eine der drei Stimmungen "positiv", "negativ" oder "neutral" auszuwählen.
In Anlehnung an OpenAIs RLHF (Reinforcement Learning with Human Feedback) nennen die Forschenden ihr Prinzip RLSP: Reinforcement Learning on Stock Prices, was wiederum als eine indirekte Form menschlichen Feedbacks gesehen werden könnte. Das System soll von der "Weisheit des Marktes" lernen und so die Finanzmärkte besser verstehen und vorhersagen können.
Open-Source-Framework für KI im Finanzsektor
Als mögliche Anwendungen für das FinGPT-Framework nennt das Team Robo-Beratung, quantitatives Trading, Portfoliooptimierung auf Basis einer Vielzahl von Faktoren, Sentiment-Analyse an den Finanzmärkten, Risikomanagement, Betrugserkennung, Kreditbewertung, Vorhersage von Insolvenzen oder des Potenzials von Übernahmen, Analyse von ESG-Profilen auf Basis öffentlicher Berichte und Nachrichten, Low-Code-Entwicklung und Finanzbildung.
Die Forschenden stellen FinGPT als Open Source unter der MIT-Lizenz bei Github zur Verfügung. Kommerzielle Nutzung ist erlaubt. Die Entwickler übernehmen keine Garantie oder Verantwortung für finanzielle Entscheidungen, die auf Basis des Modells getroffen werden.



