Forscher bringen Sprachmodellen wissenschaftlichen Geschmack bei

Kurz & Knapp
- Mit Zitationsdaten von Millionen wissenschaftlicher Arbeiten haben chinesische Forscher Sprachmodellen beigebracht, den potenziellen Einfluss von Forschung vorherzusagen.
- Statt auf teure menschliche Annotatoren setzen sie auf ein neues Trainingsverfahren, das Zitationen als Gemeinschaftssignal nutzt.
- Das trainierte Modell übertrifft deutlich größere Systeme wie GPT-5.2 und Gemini 3 Pro bei der Vorhersage, welche Arbeit mehr zitiert wird, und generalisiert sogar auf Fachgebiete wie Biologie, die gar nicht in den Trainingsdaten vorkamen.
Ein chinesisches Forschungsteam nutzt Zitationsdaten von 2,1 Millionen wissenschaftlichen Arbeiten, um Sprachmodellen beizubringen, den potenziellen Einfluss von Forschungsideen vorherzusagen und selbst wirkungsvollere Ideen zu formulieren.
Bisherige Ansätze für KI-gestützte Wissenschaft konzentrieren sich auf Literaturrecherche und die Automatisierung von Experimenten. Die Frage, welche Forschungsrichtungen überhaupt verfolgenswert sind, bleibt dabei weitgehend unbeantwortet. Ein Forschungsteam der Fudan University, der Tsinghua University und weiterer Institutionen will genau diese Lücke schließen. In einem neuen Paper formalisieren die Forscher das, was sie "wissenschaftlichen Geschmack" nennen: "die Fähigkeit, Forschungsideen mit hohem potenziellen Einfluss zu beurteilen und vorzuschlagen."
Ihr Ansatz besteht aus zwei Komponenten: Scientific Judge, ein Modell, das vorhersagt, welche von zwei Arbeiten mehr Zitationen erhalten wird, und Scientific Thinker, ein Modell, das eigenständig Forschungsideen mit möglichst hohem Wirkungspotenzial formuliert. Beide werden mit einem neuen Trainingsparadigma namens "Reinforcement Learning from Community Feedback" (RLCF) trainiert, das Zitationszahlen als Gemeinschaftssignal nutzt.
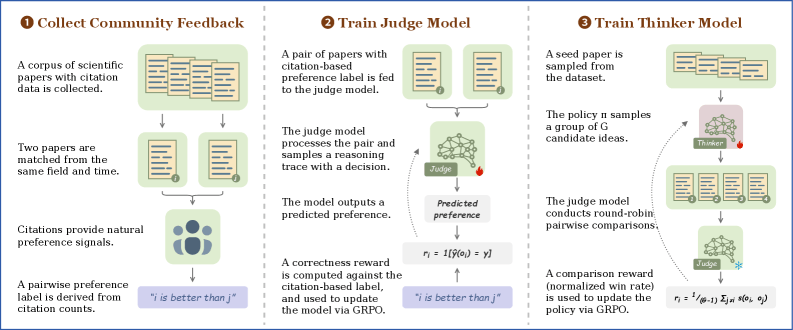
Zitationen statt menschlicher Annotatoren als Trainingsgrundlage
Die Forscher argumentieren, dass menschliches Feedback (RLHF) und verifizierbare Belohnungen (RLVR) für wissenschaftliche Urteilsbildung an Grenzen stoßen: RLVR sei für offene Aufgaben wie wissenschaftliche Bewertung schwer anwendbar, da es an verifizierbare Grundwahrheiten gebunden ist. RLHF sei durch die hohen Kosten menschlicher Annotationen und die Schwierigkeit, über individuelle Präferenzen hinaus Gemeinschaftsurteile abzubilden, limitiert. Stattdessen greifen sie auf Zitationen zurück.
Die philosophische Begründung holen sie sich bei David Hume und Immanuel Kant: Ein Geschmacksurteil entstehe nicht aus willkürlicher Einzelmeinung, sondern aus dem gemeinsamen Urteil qualifizierter Beobachter. In der Wissenschaft manifestiere sich dieses Gemeinschaftsurteil durch Zitationen, "die gebräuchlichste Methode, den Einfluss wissenschaftlicher Forschung zu messen", so das Paper.
Um Verzerrungen zu minimieren, bilden die Forscher Paare aus demselben Fachgebiet und Zeitfenster, wobei das höher zitierte Paper als "bevorzugt" gilt. Der resultierende Datensatz SciJudgeBench umfasst rund 700.000 solcher Paare aus 2,1 Millionen arXiv-Papieren.
30-Milliarden-Modell schlägt GPT-5.2 bei der Zitationsvorhersage
Scientific Judge liest Titel und Abstracts zweier Paper, formuliert eigenständig eine Begründung und sagt vorher, welches mehr Zitationen erhalten wird. Ein Beispiel aus dem Paper: Das Modell soll zwischen zwei Arbeiten entscheiden, eine stellt einen neuen Optimierungsalgorithmus für das Training von Sprachmodellen vor, die andere eine Methode, um synthetische Trainingsdaten zu erzeugen.
Scientific Judge urteilt korrekt zugunsten des Algorithmus und begründet das so: Optimierungsverfahren würden typischerweise zu festen Bausteinen in Trainings-Pipelines und entsprechend häufig zitiert, während Methoden zur Datenerzeugung schneller veralten, weil sich Daten-Pipelines ständig änderten.
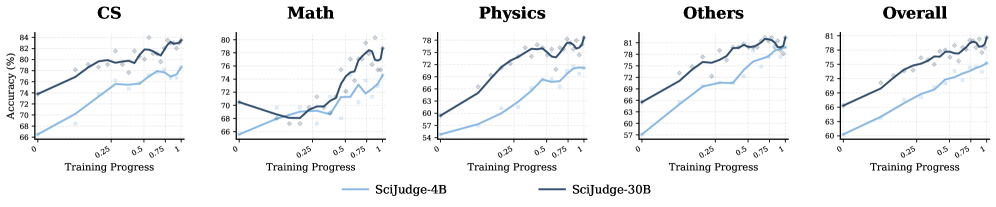
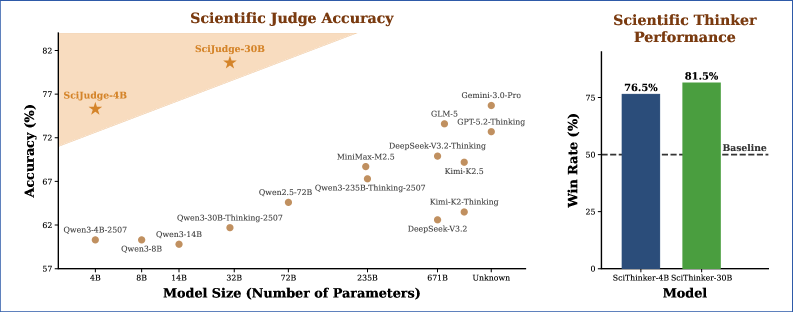
Das beste Modell, SciJudge-Qwen3-30B, erreicht laut den Forschern 80,6 Prozent Genauigkeit auf dem In-Domain-Testset und übertrifft damit GPT-5.2 (72,7 Prozent) und Gemini 3 Pro (75,7 Prozent). In der Qwen2.5-Modellfamilie skaliert die Genauigkeit von 72,1 Prozent bei 1,5 Milliarden Parametern auf 83,7 Prozent bei 32 Milliarden.
Auf Informatik trainiert, in Mathematik und Physik anwendbar – und selbst Biologie profitiert
Die vielleicht überraschendsten Ergebnisse betreffen die Generalisierung. Ein ausschließlich auf Informatik-Papieren trainiertes Modell verbessert die Vorhersage auch für Mathematik und Physik erheblich. Noch weiter geht ein Test auf Biorxiv-Papieren aus der Biologie – einer Plattform und einem Fachgebiet, die komplett außerhalb der Trainingsdaten liegen: Hier springt die Genauigkeit von 45,0 auf 71,2 Prozent, wobei dieses Ergebnis aus Modellen stammt, die auf arXiv-Papieren aus mehreren Feldern (Informatik, Mathematik, Physik und weiteren) trainiert wurden. Und ein auf Zitationsdaten trainiertes Modell sagt korrekt vorher, welches Paper bei der ICLR-Konferenz bessere Peer-Review-Bewertungen erhält, obwohl es nie Review-Scores gesehen hat (87,7 Prozent Genauigkeit).
"Das liefert Belege dafür, dass KI einen breit generalisierbaren wissenschaftlichen Geschmack lernen kann", schreiben die Forscher.
Trainierte Modelle formulieren wirkungsvollere Forschungsideen als GPT-5.2
Scientific Judge dient auch als Belohnungsmodell für Scientific Thinker. Dieses zweite Modell erhält ein existierendes Paper und soll eine Folge-Forschungsidee mit hohem Wirkungspotenzial vorschlagen. Für jeden Input generiert es mehrere Kandidatenideen, die Scientific Judge in einem Round-Robin-Turnier paarweise vergleicht. Die Win-Rate dient als Belohnung für das Training.
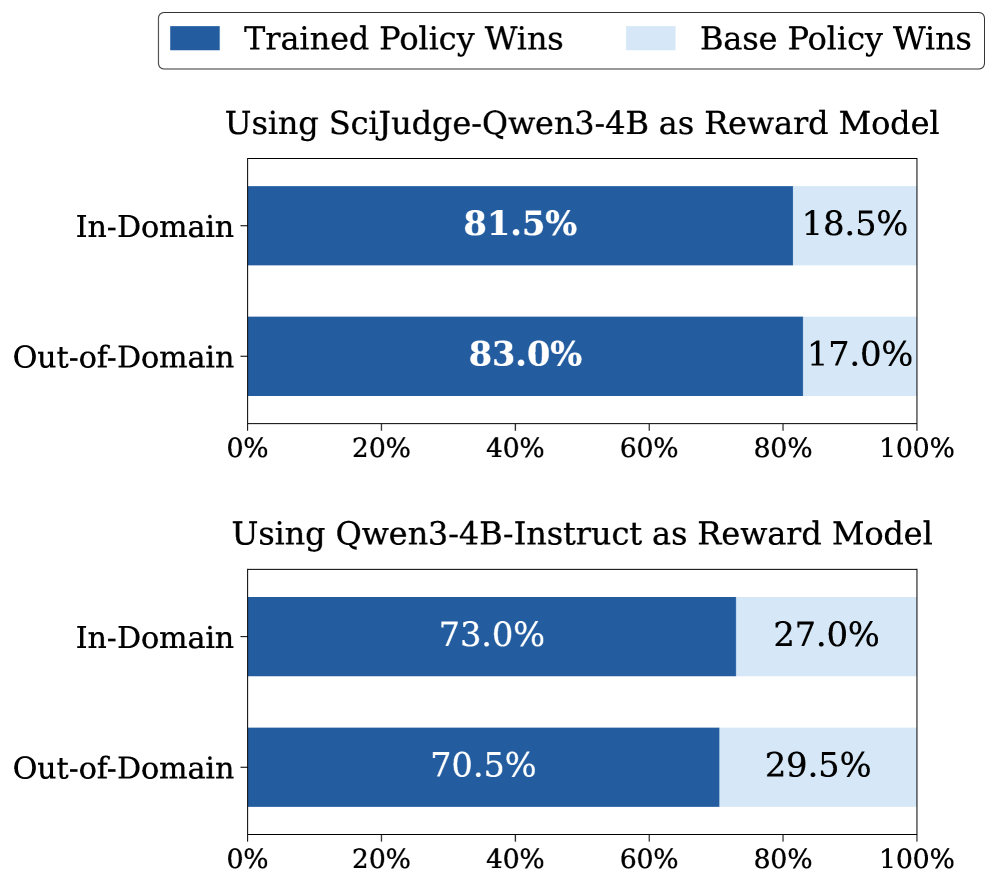
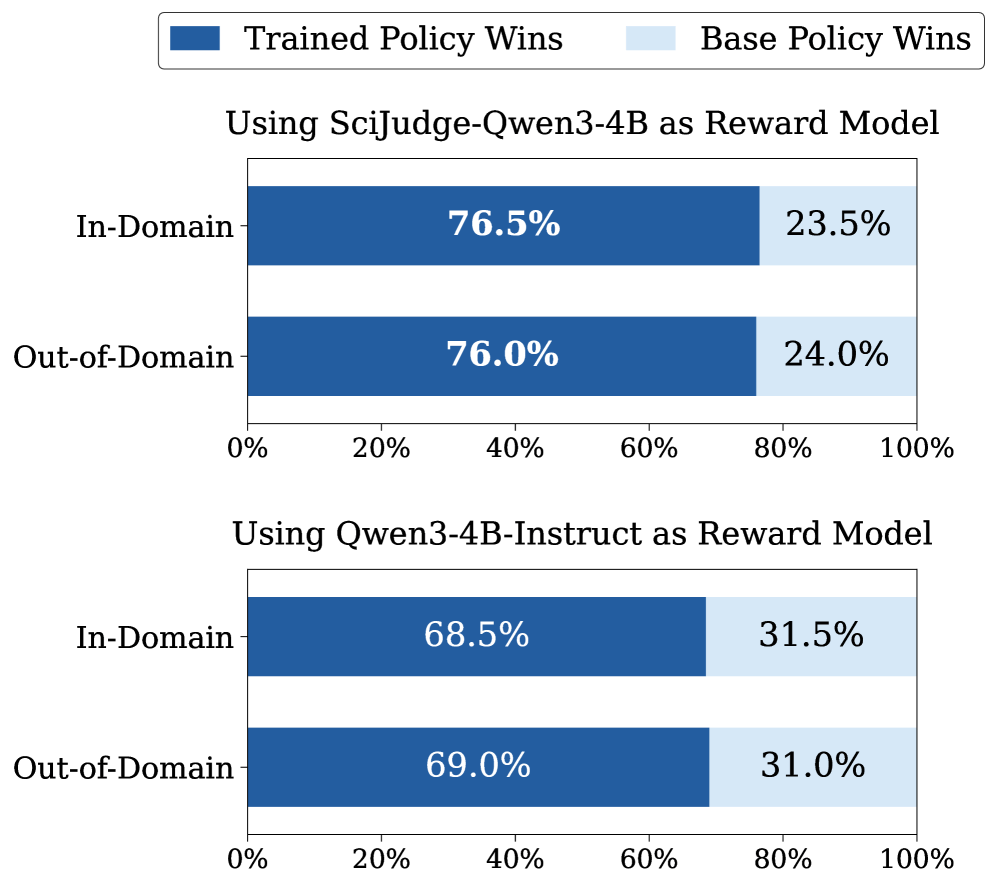
SciThinker-30B gewinnt gegen seine untrainierte Basis-Policy in 81,5 Prozent der Fälle. Gegen GPT-5.2, GLM-5 und Gemini 3 Pro erreicht es eine durchschnittliche Win-Rate von 54,2 Prozent, die untrainierte Basis-Policy kommt nur auf 30,3 Prozent.
Die Forscher benennen selbst Einschränkungen: Zitationen seien ein unvollkommenes Signal, das Modell arbeite hauptsächlich mit Titeln und Abstracts, und die generierten Ideen würden nicht experimentell umgesetzt.
Zudem warnen sie vor Missbrauchspotenzial zur Massenproduktion oberflächlich vielversprechender Forschungsideen. Gleichzeitig halten sie an ihrem zentralen Befund fest: "Wissenschaftlicher Geschmack ist keine mystische menschliche Eigenschaft, sondern ein lernbares Ziel." Der Code ist auf GitHub verfügbar. Eine Demo gibt es hier.
Branche ringt um die Rolle von KI in der Forschung
Die Frage, wie weit KI in der wissenschaftlichen Forschung tatsächlich reicht, beschäftigt die Branche derzeit intensiv. Google Deepminds KI-Agent Aletheia etwa schrieb eigenständig ein Mathematik-Paper und widerlegte eine jahrzehntealte Vermutung, scheiterte aber an einer systematischen Auswertung von 700 offenen Problemen: Nur 6,5 Prozent der Antworten waren brauchbar.
OpenAI-Manager Kevin Weil prognostiziert dennoch, dass 2026 für die Wissenschaft werde, "was 2025 für Software-Engineering war", und seine Firma will bis 2028 einen autonomen Forschungsagenten entwickeln. Gleichzeitig zeigt eine Umfrage unter fast 5.000 Forschern, dass zwar mehr als die Hälfte KI in bestimmten Bereichen für leistungsfähiger hält als Menschen, ethische Bedenken und die Angst vor Halluzinationen den breiten Einsatz aber weiterhin bremsen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren