Forscher entwickeln universelles OCR-Modell für die nächste Generation der Texterkennung

Wissenschaftler:innen haben ein neues universelles optisches Zeichenerkennungsmodell (OCR) mit dem Namen GOT (General OCR Theory) entwickelt. In ihrem Forschungspapier definieren sie damit auch die Ära von OCR-2.0, die die Stärken traditioneller OCR-Systeme und großer Sprachmodelle vereinen soll.
Laut den Forschenden zeichnet sich ein OCR-2.0-Modell durch eine einheitliche Ende-zu-Ende-Architektur sowie geringeren Ressourcenbedarf als LLMs aus. Dennoch müsse es vielseitig einsetzbar sein und nicht nur reinen Fließtext erkennen.
GOT besteht aus einem Bildencoder mit rund 80 Millionen Parametern und einem Sprachdecoder mit 500 Millionen Parametern. Der Encoder komprimiert Bilder mit einer Auflösung von 1.024 x 1.024 Pixeln effizient in Tokens, die der Decoder in Text mit bis zu 8.000 Zeichen Länge umwandelt.
GOT macht Formeln, Musiknoten und mehr editierbar
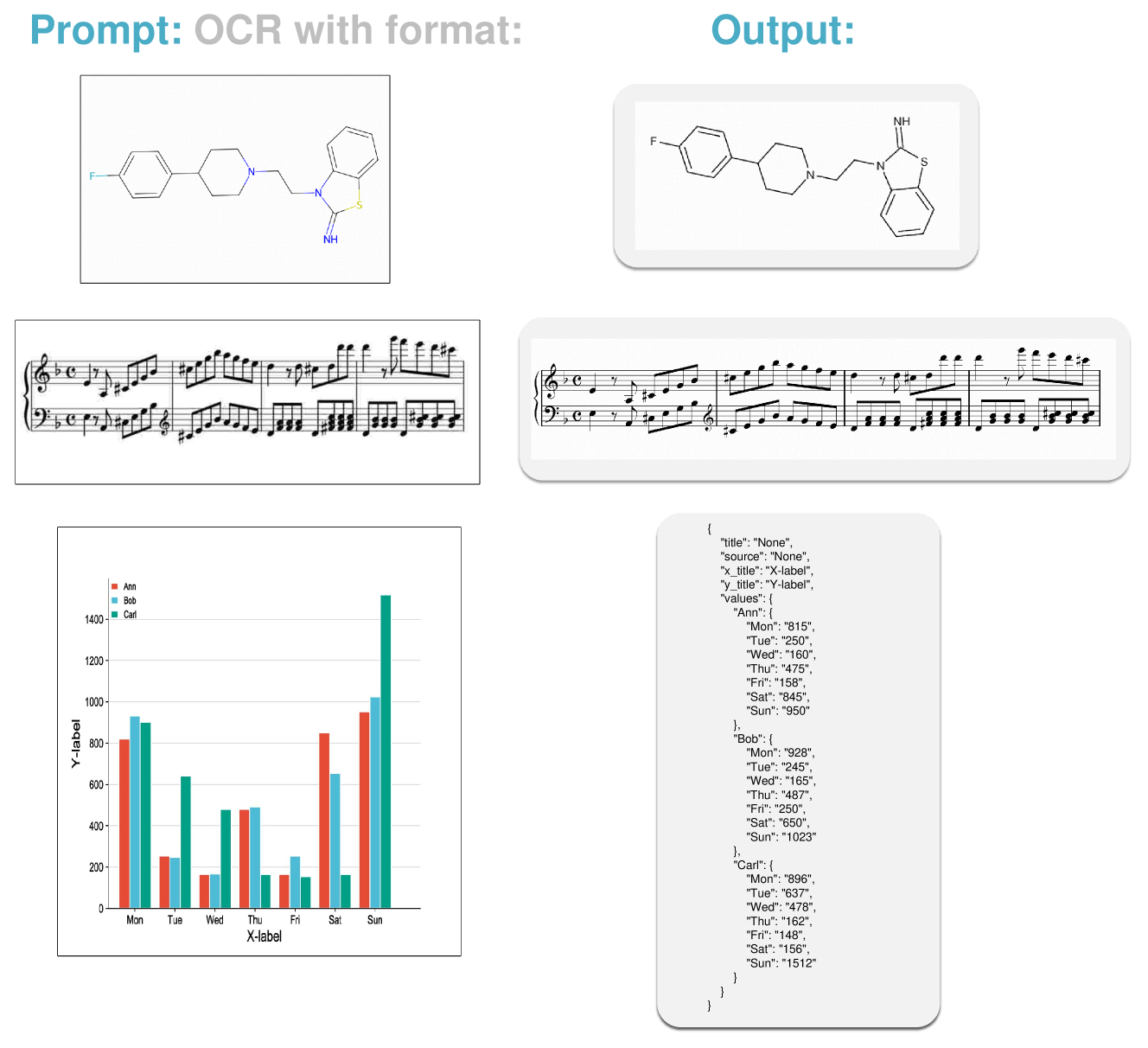
GOT kann eine Vielzahl von visuellen Informationen erkennen und in editierbaren Text umwandeln, z.B. Szenen- und Dokumententexte in Englisch und Chinesisch, mathematische und chemische Formeln, Musiknoten, einfache geometrische Formen sowie Diagramme und deren Bestandteile wie Titel und Achsenbeschriftungen.
Um das Training zu beschleunigen und Rechenressourcen zu sparen, haben die Forschenden in einem dreistufigen Verfahren zunächst nur den Encoder auf Texterkennungsaufgaben trainiert.
Anschließend haben sie Alibabas Qwen-0.5B als Decoder hinzugefügt, da das kleine Modell vergleichsweise viele verschiedene Sprachen beherrscht, und das gesamte Modell mit vielfältigeren, synthetischen Daten optimiert.
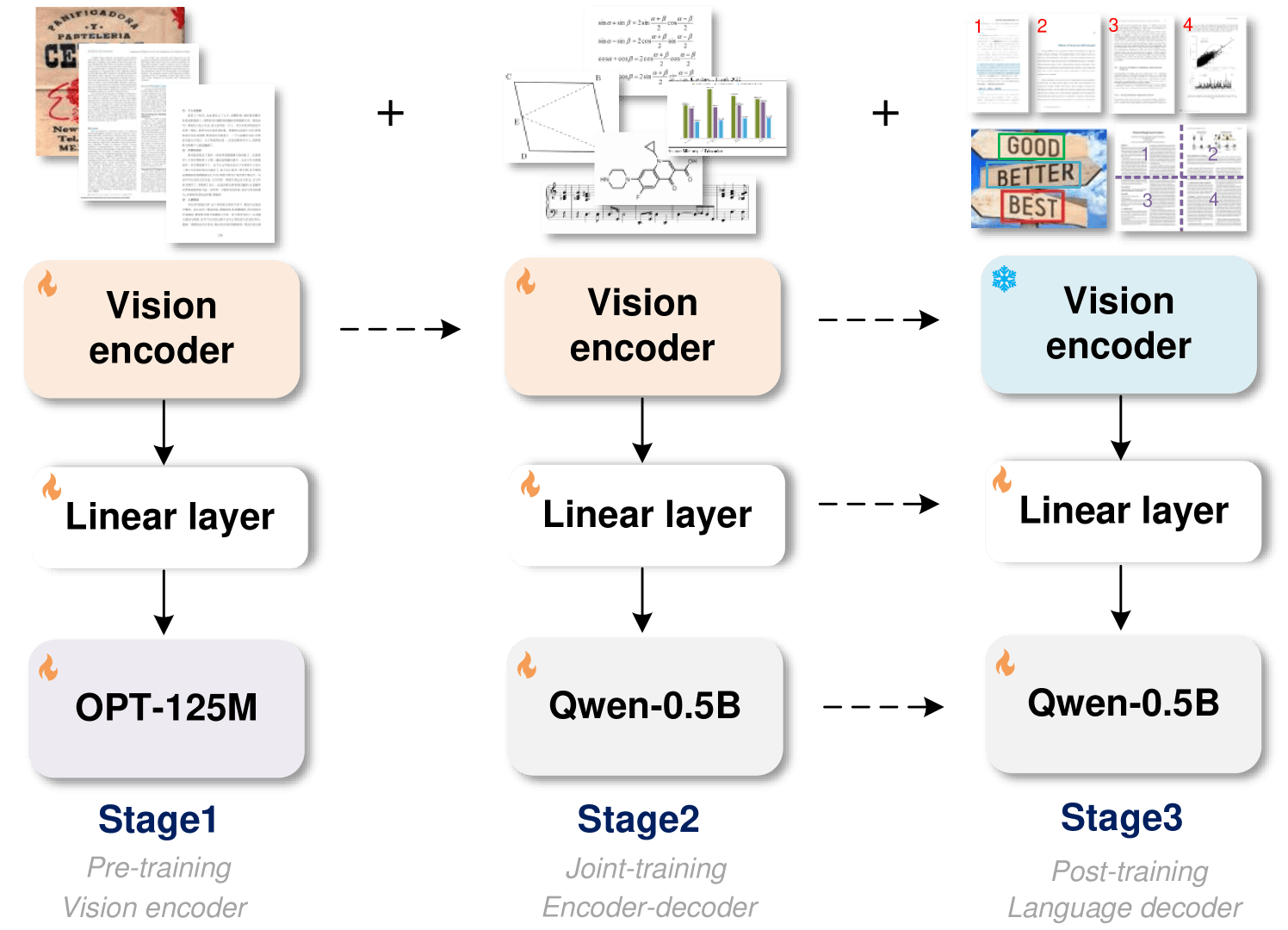
Zuletzt wurde lediglich der Decoder verfeinert, um zusätzliche Funktionen wie die Erkennung von Bildregionen, die Verarbeitung hochauflösender Bilder und die Erkennung mehrseitiger Dokumente zu ermöglichen. Dabei kann GOT auch die Formatierung des Dokuments beibehalten.

Modulare Architektur ermöglicht flexible Erweiterung
Durch den modularen Aufbau und das Training auf synthetischen Daten kann GOT laut den Forschenden flexibel um neue Fähigkeiten erweitert werden, ohne dass sie das gesamte Modell neu trainieren müssen.
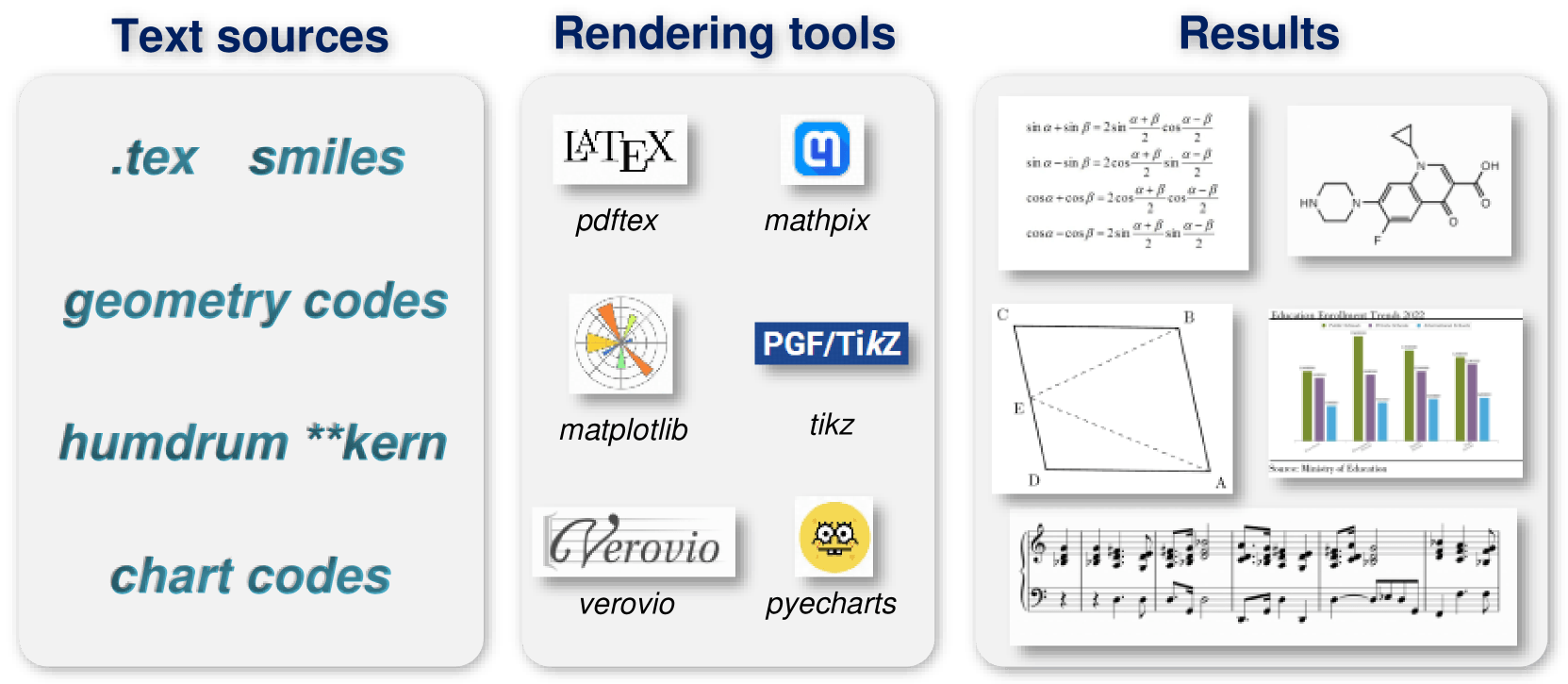
Für die Erzeugung der Trainingsdaten setzten die Forscher:innen auf Rendering-Tools wie LaTeX, Mathpix-markdown-it, TikZ, Verovio, Matplotlib und Pyecharts. Damit wandelten sie gesammelte Textquellen in Millionen von Bild-Text-Paaren um.
In den Experimenten der Forscher schnitt GOT bei verschiedenen OCR-Aufgaben gut ab. Bei der Erkennung von Text in Dokumenten und Szenen erzielte es Bestwerte. Zudem übertraf es bei der Erkennung von Diagrammen sogar spezialisierte Modelle und große Sprachmodelle.
Eine kostenlose Demo sowie den Code haben die Forschenden auf Hugging Face bereitgestellt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.