Forscher liefern weiteren Grund zur Skepsis bei KI-Benchmarks
Eine unabhängige Untersuchung zeigt, dass OpenAIs o1 bei Programmiertests nur etwa 30 Prozent der Aufgaben löst - deutlich weniger als vom Unternehmen angegeben. Der Fall wirft erneut grundsätzliche Fragen zur Aussagekraft von KI-Benchmarks auf.
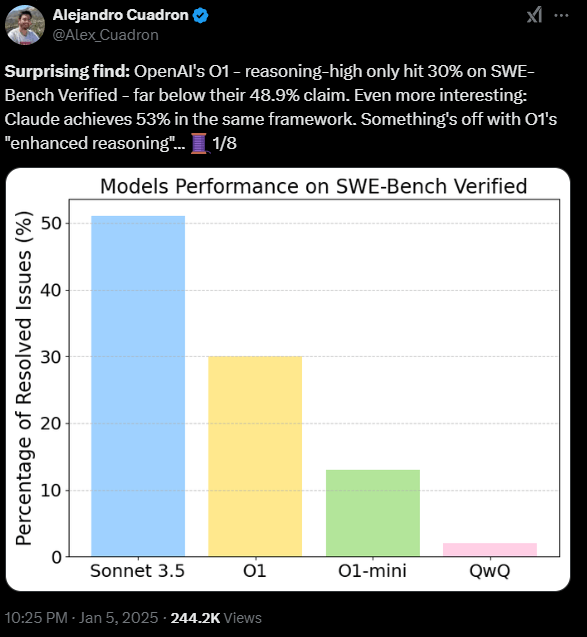
Laut einer Untersuchung des KI-Forschers Alejandro Cuadron löst OpenAIs neuestes Sprachmodell o1 bei Programmieraufgaben im "SWE-Bench Verified"-Benchmark nur etwa 30 Prozent der gestellten Aufgaben - deutlich weniger als die vom Unternehmen angegebenen knapp 49 Prozent. Der Benchmark testet, ob KI-Modelle reale Aufgaben von Github lösen können.
Anthropics Sonnet 3.5 löste im gleichen Test 53 Prozent der Aufgaben, was aber darauf zurückzuführen sein könnte, dass das Modell an der Entwicklung des verwendeten Testverfahrens beteiligt war. Aber auch das deutlich billigere Modell Deepseek v3 konnte in den Tests von Cuadron fast die gleichen Ergebnisse wie OpenAI o1 erzielen.
Unterschiedliche Testverfahren, unterschiedliche Ergebnisse
Die Diskrepanz zwischen den Testergebnissen ist auf unterschiedliche Messmethoden zurückzuführen: OpenAI nutzte für seine Tests das Open-Source-Framework "Agentless", das der KI sehr enge Vorgaben für die Lösung von Programmieraufgaben macht.
Cuadron hingegen verwendete das Framework "OpenHands", das der KI mehr Freiheiten bei der Problemlösung lässt. Laut Cuadron war OpenHands zum Zeitpunkt der Tests von OpenAI der Goldstandard, OpenAI verwendete es trotzdem nicht.
Die Forscher vermuten, dass die starre Testmethode von OpenAI KI-Modelle begünstigt, die einfach Lösungen aus den Trainingsdaten auswendig lernen, anstatt wirklich zu planen und Probleme selbstständig zu lösen.
Bereits zuvor hatte ein Benchmark zur Reiseplanung gezeigt, dass o1-preview von OpenAI im Bereich der Planung noch Schwächen aufweist. Eine Studie von Apple zeigte, dass leicht veränderte mathematische Probleme zu einer deutlich schlechteren Leistung führten - was darauf hindeutet, dass das Modell nicht gut darin ist, Wissen zu verallgemeinern.
Das wiederum steht in direktem Widerspruch zu den Behauptungen von OpenAI, dass die Stärke ihrer o-Modelle in ihren logischen Fähigkeiten liegt, mit denen sie neue, noch nie gesehene Probleme lösen können.
Unabhängig davon, welche Messung der Wahrheit am nächsten kommt: Der Fall zeigt wieder einmal, dass die Ergebnisse in KI-Benchmarks von vielen Faktoren abhängen. Diese Art der direkten oder indirekten Optimierung auf Testverfahren macht es für Außenstehende schwierig, die tatsächliche Leistungsfähigkeit eines KI-Systems zu beurteilen.
Dennoch sind Benchmark-Resultate häufig der Motor für PR und Marketingkommunikation, die wiederum ihren Teil dazu beitragen, dass die beteiligten Unternehmen etwa Geld von Investoren erhalten.
Logan Kilpatrick, Produktleiter bei Google AI Studio, betont die Bedeutung von überprüfbaren und offenen Testverfahren. Er vermutet zwar keine böse Absicht seitens OpenAI, sieht aber die Notwendigkeit, solche Bewertungsprobleme zu lösen - besonders auf dem Weg zu fortgeschritteneren KI-Systemen.
"Die Welt benötigt mehr, bessere, härtere etc. Benchmarks für KI. Das ist eines der wichtigsten Themen unserer Zeit und entscheidend für den weiteren Fortschritt", schreibt Kilpatrick, der letztes Jahr von OpenAI zu Google wechselte.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.