Galactica ist ein Open-Source-Sprachmodell für wissenschaftlichen Fortschritt

Update –
Meta AI hat die Demo-Funktion der Galactica-Webseite deaktiviert. Das könnte eine Reaktion auf Kritik von Wissenschaftlern sein.
Das große Sprachmodell Galactica ist mit Millionen akademischer Inhalte trainiert. Es soll der Forschungsgemeinschaft helfen, die "Explosion an Informationen" besser zu handhaben.
Entwickelt wurde das große Sprachmodell (LLM) Galactica von Meta AI in Zusammenarbeit mit der Plattform "Papers with Code". Das Team hat die Informationsflut als "ein großes Hindernis für den wissenschaftlichen Fortschritt" ausgemacht. "Forscher werden unter einer Flut von Papieren begraben und sind immer weniger in der Lage, zwischen dem Sinnvollen und dem Unwichtigen zu unterscheiden."
Galactica soll helfen, wissenschaftliche Informationen zu sortieren. Trainiert wurde es mit 48 Millionen Inhalten aus wissenschaftlichen Artikeln, Lehrbüchern, Referenzmaterial, Verbindungen, Proteinen und anderen wissenschaftlichen Wissensquellen aus dem "NatureBook"-Datensatz.
Sprachmodelle als neues Forschungs-Interface
Galactica kann laut des Forschungsteams Wissen speichern, kombinieren und schlussfolgern und übertrifft in Benchmarks wie dem mathematischen MMLU teils weit größere Sprachmodelle wie Chinchilla (41,3 % zu 35,7 %) oder PaLM 540B (20,4 % zu 8,8 %) deutlich.
Bei technischen Wissenstests wie LaTeX-Gleichungen übertrifft Galactica GPT-3 um 68,2 % gegenüber 49,0 %. Auch bei der Beantwortung von Fachfragen aus Biologie und Medizin (PubMedQA und MedMCQA) erzielt Galactica neue Bestwerte (77,6 % und 52,9 %).

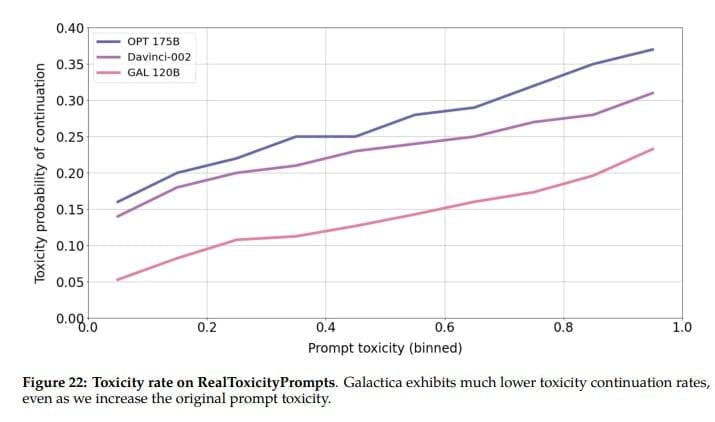
Zudem schlägt Galactica die großen Open-Source-Sprachmodelle Bloom und OPT-175B im "BIG-Bench"-Benchmark mit generellen Sprachaufgaben, obwohl es nicht für diese optimiert wurde. Die Textgenerierung sei im Vergleich außerdem signifikant weniger toxisch.
Wir vermuten, dass dieses Ergebnis die höhere Qualität des Galactica-Korpus widerspiegelt, die sich aus der Tatsache ergibt, dass er kuratiert ist und außerdem hauptsächlich aus akademischen Texten besteht. Frühere offene LLM-Bemühungen haben sich wahrscheinlich zu sehr auf die Skalierung und zu wenig auf die Datenfilterung konzentriert:
Aus dem Paper
Als konkrete Anwendungsszenarien nennt das Galactica-Team die Generierung von Literature Reviews, von Wiki-Artikeln oder Lectures Notes zu wissenschaftlichen Themen oder Antworten auf wissenschaftliche Fachfragen samt Zitationen.
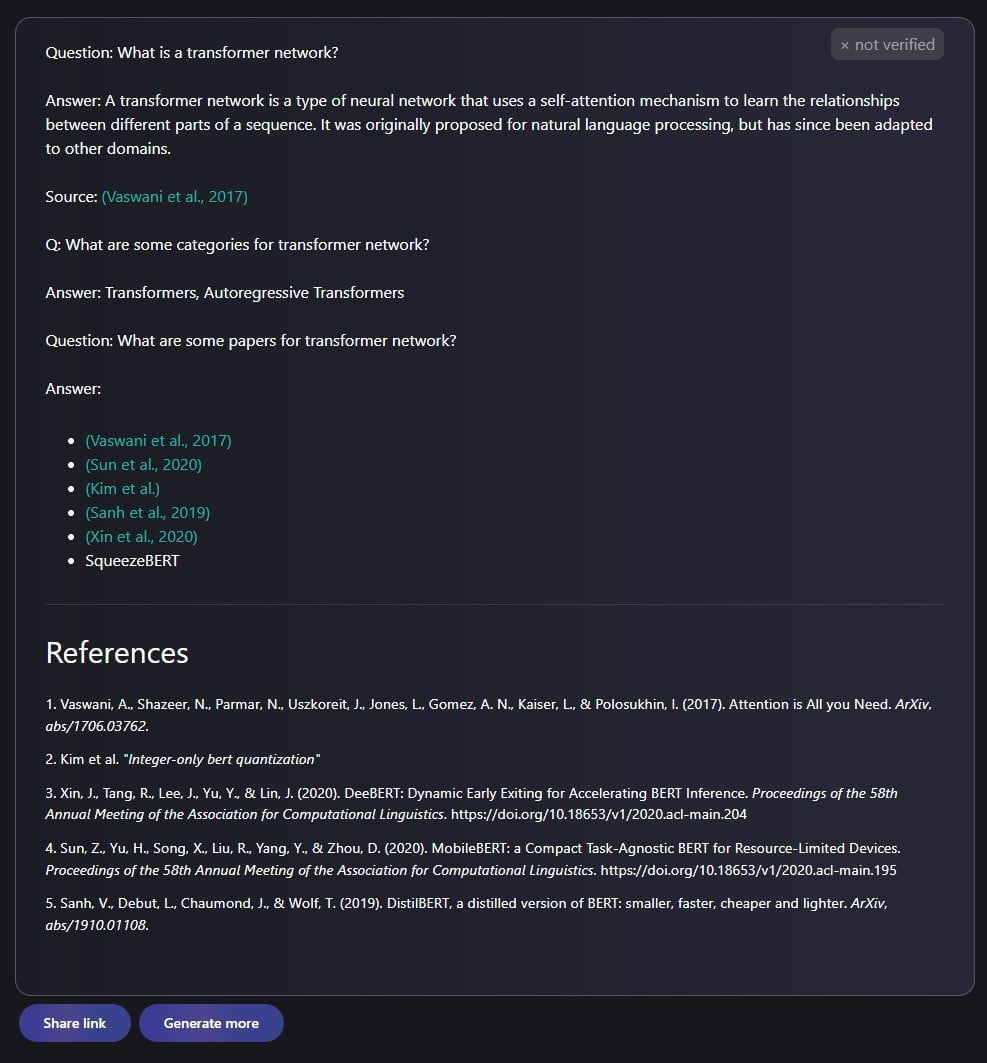
Auf die Frage, was ein "Transformer-Netzwerk" ist, generiert Galactica die folgende kurze Erklärung mit Literaturverweisen samt Links auf Paper.
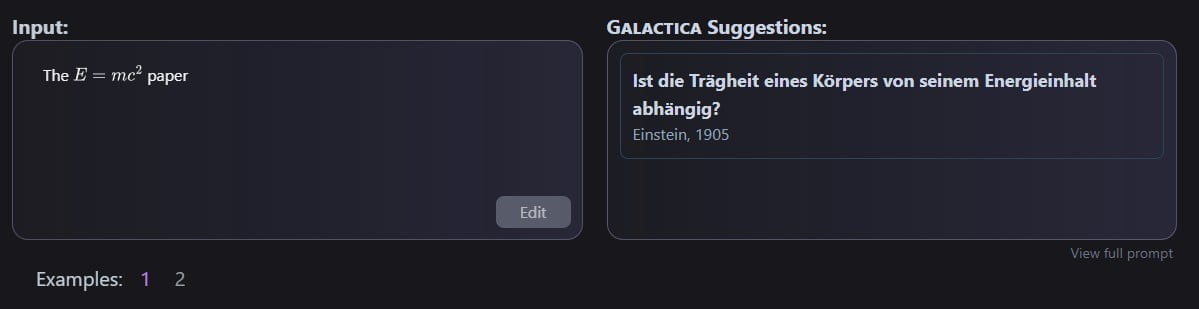
Das Modell bietet zudem eine Art Paper-Suche, bei der man den Inhalt eines Papers beschreiben und ein möglicherweise passendes angezeigt bekommt. Es kann nach spezifischen mathematischen Formeln suchen oder diese in natürlicher Sprache beschreiben oder Zitationen vorschlagen. Bei letztgenannter Funktion liegt die Genauigkeit allerdings nur zwischen 36,6 und 69,1 Prozent je nach Testdatensatz und zeigt einen Bias zugunsten bekannter Paper.
Viel Verbesserungspotenzial
"Wir glauben, dass diese Ergebnisse das Potenzial von Sprachmodellen als neue Schnittstelle für die Wissenschaft zeigen", schreiben die Forschenden. Galactica sei nur der erste Schritt auf dieser Reise.
Im begleitenden wissenschaftlichen Artikel beschreibt das Team zahlreiche Verbesserungspotenziale, unter anderem die Verwendung von mehr und nicht öffentlich verfügbaren akademischen Quellen sowie multimodales Training mit Daten abseits von Text wie Proteinmodelle.
Demo-Video zu Galactica. | Video: Galactica / Meta AI
"Alles in allem sind wir der Meinung, dass Sprachmodelle ein großes Potenzial haben, Wissensaufgaben zu übernehmen, die derzeit menschliche Spezialgebiete sind", schreibt das Team. Die ultimative Vision sei ein einziges neuronales Netz für sämtliche wissenschaftliche Aufgaben, das als "nächste Schnittstelle" für den Zugriff auf Wissen fungiert.
Insgesamt trainierte das Team fünf Galactica-Modelle zwischen 125 Millionen und 120 Milliarden Parametern. Die Leistungsfähigkeit von Galactica steigert sich laut des Teams gleichmäßig mit der Skalierung. Alle Modelle sind Open Source und bei Github frei verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.