Gemma 3: Google bringt leistungsstarke KI-Modelle auf Consumer-Hardware
Mit quantisierungsoptimierten Varianten der Gemma-3-Modelle bringt Google leistungsstarke KI auf Consumer-GPUs. Möglich macht das ein spezielles Training, das auch bei stark reduzierter Rechenpräzision die Modellqualität erhält.
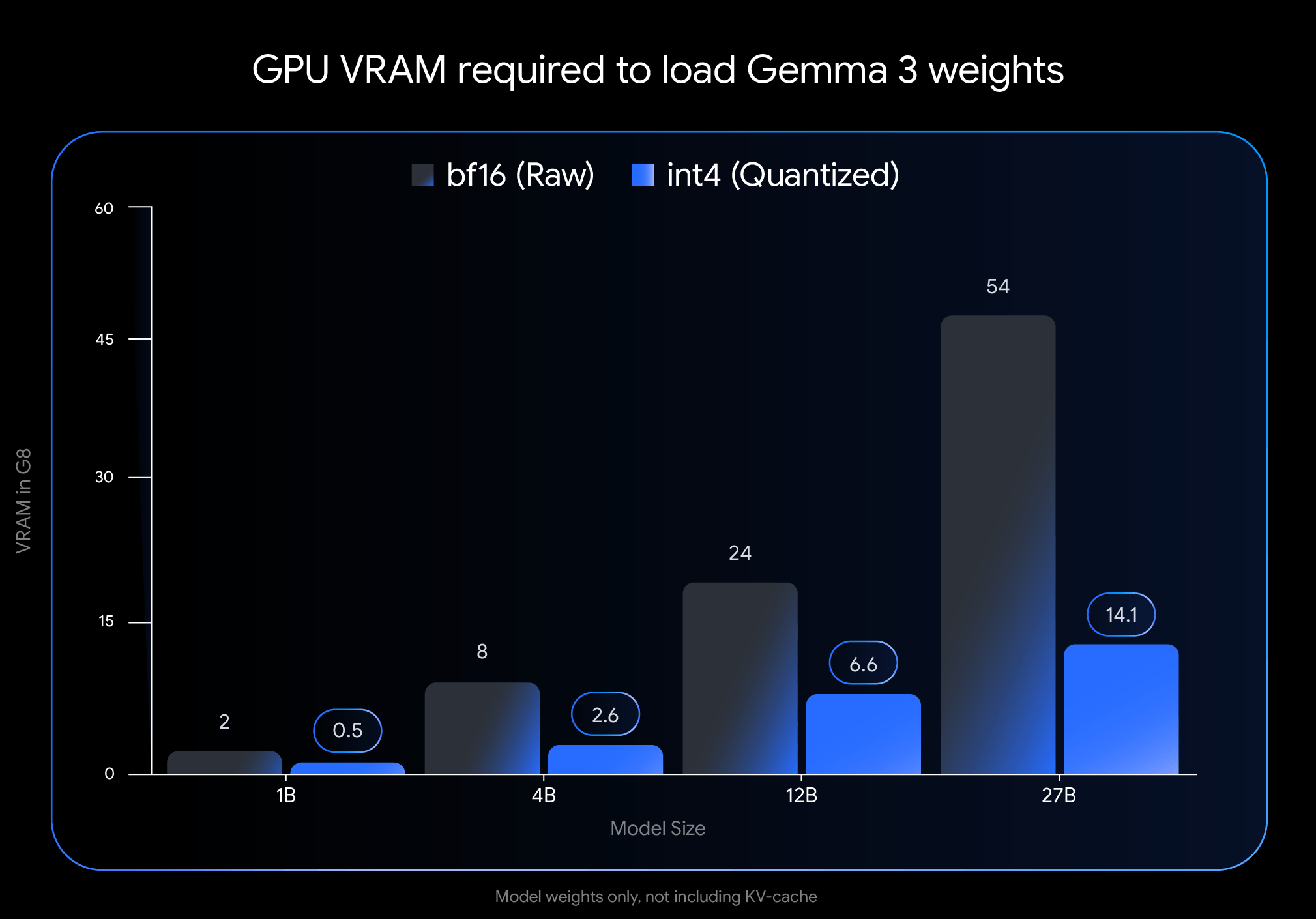
Google hat neue Varianten seiner Open-Source-Sprachmodelle Gemma 3 veröffentlicht, die sich durch einen deutlich reduzierten Speicherbedarf auszeichnen. Das größte Modell, Gemma 3 27B, kann nun auf einer handelsüblichen NVIDIA RTX 3090 mit 24 GB VRAM betrieben werden. Das 12B-Modell läuft auf Laptop-GPUs wie der RTX 4060 mit 8 GB VRAM. Kleinere Varianten wie 1B oder 4B eignen sich laut Google sogar für mobile Geräte.
Ursprünglich waren diese Modelle auf Hochleistungshardware wie der NVIDIA H100 mit BFloat16-Präzision ausgelegt. Doch durch die Reduktion der Quantisierung wurde der benötigte Speicher deutlich verringert. Die Modelle und Checkpoints sind auf Hugging Face und Kaggle verfügbar.
Reduzierte Präzision, kaum Qualitätsverlust
Quantisierung in der KI bezeichnet den Vorgang, bei dem die numerischen Werte eines Modells – insbesondere Gewichtungen und Aktivierungen – mit weniger Bits dargestellt werden. Statt wie üblich 16 oder 32 Bit pro Zahl zu verwenden, reichen bei starker Quantisierung oft schon 8, 4 oder sogar 2 Bit. Das spart Speicherplatz und beschleunigt die Modellausführung, da kleinere Zahlen schneller verarbeitet werden und der Datenverkehr zwischen Speicher und Prozessor sinkt.
Google setzt bei der Quantisierung der Gemma-Modelle auf einen besonderen Ansatz, der bereits im Training greift. Beim sogenannten Quantization-Aware Training (QAT) wird die reduzierte Präzision während des Trainingsprozesses simuliert. Das Modell lernt so, mit den Ungenauigkeiten der späteren Quantisierung umzugehen – und bleibt trotz geringerer Bitbreite leistungsfähig.
Tatsächlich zeigen die quantisierten Modelle deutliche Einsparungen beim GPU-Speicherbedarf: Gemma 3 27B benötigt im int4-Format nur noch 14,1 GB statt 54 GB VRAM, Gemma 3 12B kommt mit 6,6 GB statt 24 GB aus. Auch kleinere Modelle profitieren: 4B schrumpft auf 2,6 GB, 1B auf lediglich 0,5 GB.
Zur Integration in bestehende Workflows sind die Modelle mit verbreiteten Inferenz-Engines kompatibel. Native Unterstützung gibt es unter anderem für Ollama, LM Studio, und MLX (für Apple Silicon). Auch Tools wie llama.cpp und gemma.cpp bieten Unterstützung für die quantisierten Gemma-Modelle im GGUF-Format.
Neben den offiziellen QAT-Modellen gibt es in der Community weitere Varianten unter dem Namen "Gemmaverse". Diese setzen meist auf Post-Training-Quantisierung und bieten alternative Kombinationen aus Modellgröße, Geschwindigkeit und Qualität.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.