Gemma 3n bringt lokale multimodale KI-Funktionen nativ auf Googles Pixel
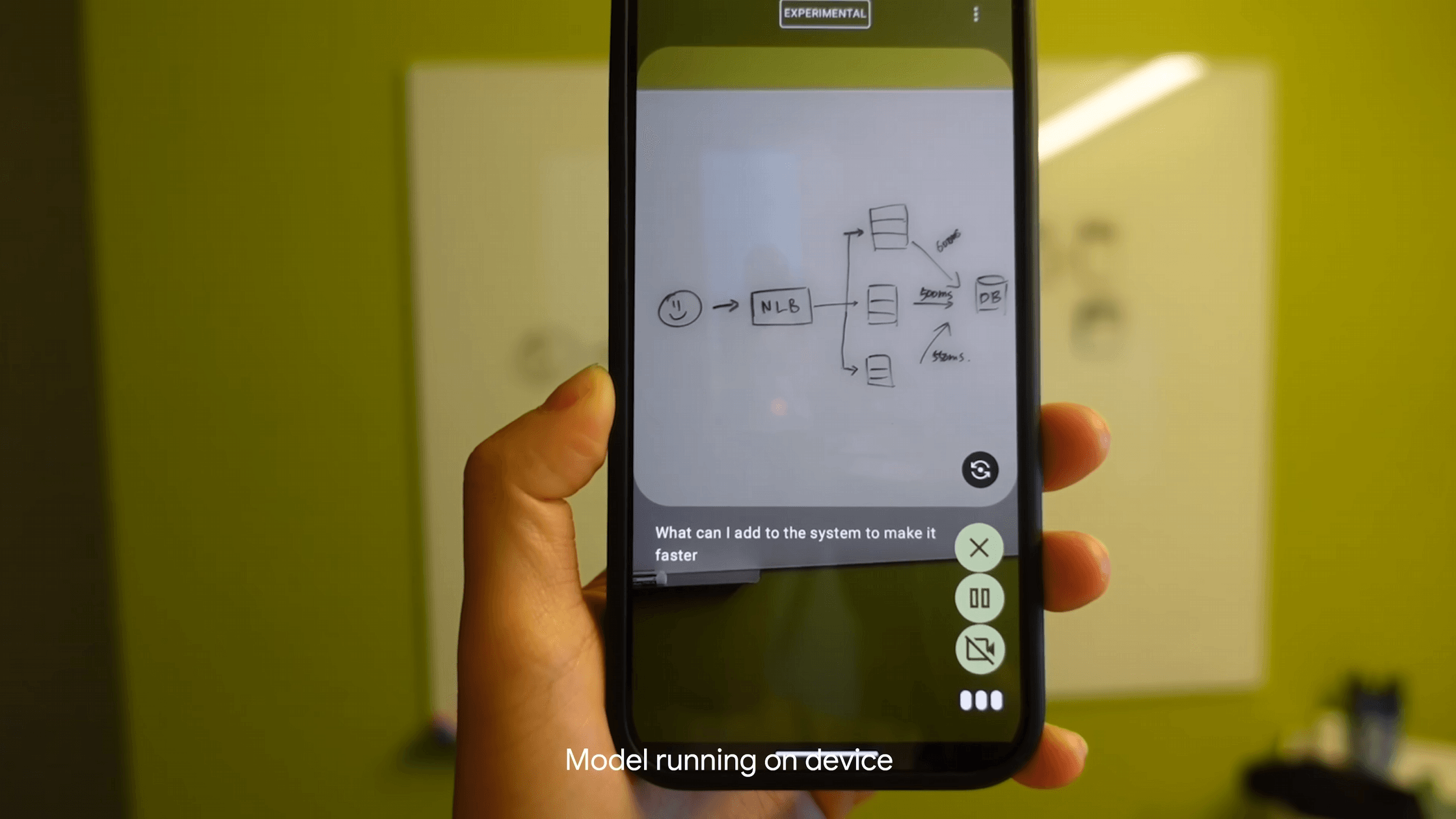
Google stellt mit Gemma 3n ein multimodales KI-Modell vor, das speziell für mobile Endgeräte entwickelt wurde.
Gemma 3n unterstützt Bild-, Audio-, Video- und Texteingaben nativ. Die Textausgabe erfolgt in bis zu 140 Sprachen, während multimodale Aufgaben in 35 Sprachen verarbeitet werden können. Zwei Modellgrößen stehen zur Verfügung: E2B mit 5 Milliarden und E4B mit 8 Milliarden Parametern. Beide Modelle benötigen dank architektonischer Optimierungen nur 2 GB (E2B) bzw. 3 GB (E4B) Arbeitsspeicher, sind aber in unterschiedlichen Quantisierungen und damit Größen verfügbar.
Im Zentrum von Gemma 3n steht die sogenannte MatFormer-Architektur, ein verschachtelter Transformer-Ansatz, der laut Google vom Konzept der Matroschka-Puppen inspiriert ist. Innerhalb des größeren E4B-Modells ist so ein vollständig funktionsfähiges E2B-Modell enthalten. Entwicklerinnen und Entwickler können beide Varianten direkt nutzen oder mit der Mix-n-Match-Methode eigene Modellgrößen generieren. Dabei lassen sich Layer gezielt deaktivieren und die Feedforward-Dimension anpassen.
Die MatFormer-Architektur soll perspektivisch auch eine dynamische Umschaltung zwischen Modellgrößen zur Laufzeit ermöglichen, um Leistung und Speicherverbrauch an die jeweilige Gerätesituation anzupassen.
Ein weiteres Merkmal von Gemma 3n ist der Einsatz von Per-Layer Embeddings (PLE). Diese Technik erlaubt es, die Einbettungen pro Layer auf der CPU zu berechnen, während nur die Kerngewichte auf der GPU oder TPU verbleiben. Dadurch reduziert sich der Speicherbedarf auf dem Accelerator auf etwa 2 Milliarden (E2B) bzw. 4 Milliarden (E4B) Parameter.
Audio und Vision: Echtzeitverarbeitung auf mobilen Geräten
Gemma 3n verarbeitet Audiodaten mit einem Encoder, der auf Googles Universal Speech Model (USM) basiert. Alle 160 Millisekunden wird ein Abschnitt des Audiosignals in ein einzelnes Token umgewandelt. Damit sind Anwendungen wie automatische Spracherkennung (ASR) und Sprachübersetzung (AST) direkt auf dem Gerät möglich, zum Beispiel für Übersetzungen zwischen Englisch und verschiedenen romanischen Sprachen. Die maximale Länge eines Audioclips beträgt aktuell 30 Sekunden, kann aber durch weiteres Training verlängert werden.
Für Bild- und Videoverarbeitung nutzt Gemma 3n den neuen MobileNet-V5-300M-Encoder. Dieser erkennt laut Google verschiedene Bildauflösungen bis zu 768x768 Pixel und soll auf einem Google Pixel Smartphone bis zu 60 Bilder pro Sekunde analysieren können. Die hohe Geschwindigkeit und Effizienz werden durch eine optimierte Architektur erreicht, die auf den Vorgängermodellen MobileNet-V4 aufbaut, aber deutlich größer und leistungsfähiger ist. Im Vergleich zur bisherigen Architektur soll MobileNet-V5 mit Quantisierung 13-mal schneller sein, und fast die Hälfte der Parameter und nur ein Viertel des Speichers benötigen.
Benchmark-Erfolge und offene Nutzung
Das E4B-Modell erreicht über 1300 Punkte im LMArena-Benchmark – ein neuer Höchstwert für Modelle unter 10 Milliarden Parametern. Auch die mit Mix-n-Match erzeugten Zwischenstufen zeigen laut Google gute Leistung bei Benchmarks wie MMLU. Ein kurzer Test des Programmierers Simon Willison zeigt allerdings, dass es deutliche Unterschiede zwischen den verschiedenen Quantisierungen gibt.
Begleitend zur Veröffentlichung startet Google die Gemma 3n Impact Challenge. Gesucht werden Anwendungen, die die multimodalen und offline-fähigen Funktionen des Modells nutzen, um konkrete gesellschaftliche Probleme zu lösen. Insgesamt sind Preisgelder von 150.000 US-Dollar ausgelobt.
Gemma 3n steht ab sofort auf Plattformen wie Hugging Face und Kaggle zum Download bereit und ist mit gängigen Entwicklungstools wie Hugging Face Transformers, llama.cpp, Docker und MLX kompatibel. Die Modelle können über Google AI Studio, Cloud Run oder Vertex AI direkt eingesetzt werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.