German Commons: Forschende veröffentlichen größten offen lizenzierten deutschen Textkorpus

Ein Forschungsteam hat mit German Commons die bisher umfangreichste Sammlung explizit offen lizenzierter deutscher Texte zusammengestellt. Der Korpus soll die Entwicklung rechtlich unbedenklicher deutscher Sprachmodelle ermöglichen.
Anders als die meisten großen Sprachmodelle, die auf Web-Crawls mit unklaren Lizenzierungen trainiert werden, stammen alle Texte in German Commons von etablierten Institutionen mit verifizierbarer Lizenzierung; die Autor:innen vertrauen dabei den von den Anbietern bereitgestellten Lizenzangaben und haben keine unabhängige Lizenzprüfung durchgeführt. Das Forschungskollektiv um die Universität Kassel, die Universität Leipzig und hessian.AI hat laut ihrer Studie 154,56 Milliarden Token deutscher Texte aus 35,78 Millionen Dokumenten zusammengestellt.
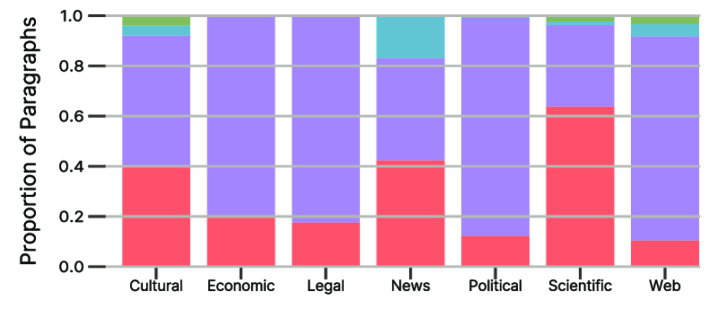
Die Forschenden haben Daten von 41 Quellen aus sieben thematischen Bereichen gesammelt: Web-Inhalte, politische Dokumente, Rechtstexte, Nachrichten, Wirtschaftstexte, kulturelle Inhalte und wissenschaftliche Texte. Zu den Datenlieferanten gehören die Deutsche Nationalbibliothek, die Österreichische Nationalbibliothek, das Deutsche Digitale Wörterbuch (DWDS), das Leibniz-Institut für Deutsche Sprache (IDS) sowie Wikimedia-Projekte.
Nachrichteninhalte und historische Texte dominieren
Den größten Anteil am Korpus stellen Nachrichtentexte, gefolgt von kulturellen Inhalten. Diese stammen größtenteils aus historischen Zeitungsarchiven und digitalisierten Büchern des 18. bis 20. Jahrhunderts. Web-Inhalte machen einen kleineren Anteil aus, während wissenschaftliche und wirtschaftliche Texte unterrepräsentiert sind.
Bei der Lizenzierung dominieren gemeinfreie Inhalte. Alle verwendeten Lizenzen erlauben die Weiterverbreitung, Modifikation und kommerzielle Nutzung.
Die Wissenschaftler:innen haben eine mehrstufige Verarbeitungspipeline entwickelt, die umfassende Qualitätsfilterung, Deduplizierung und Textformatierungskorrekturen umfasst. Da ein großer Teil der Daten aus eingescannten Texten stammt, die per Computer erkannt wurden, setzten sie spezielle Filter ein, um typische Erkennungsfehler zu reduzieren. Sie verweisen darauf, dass deutsche Sonderzeichen wie Umlaute besonders fehleranfällig bei der automatischen Texterkennung sind.
Die Qualitätsfilterung entfernte 46 Prozent der ursprünglich gesammelten Daten, hauptsächlich nicht-deutsche Texte aus mehrsprachigen Quellen und sehr kurze Texte. Insgesamt blieben 51 Prozent der ursprünglich gesammelten Daten erhalten.
Eine Analyse von 385.467 Textabschnitten ergab minimale toxische Inhalte: In fünf verschiedenen Kategorien wie Gewalt oder Diskriminierung erhielten durchschnittlich 95 Prozent der Texte die niedrigste Bewertung, was bedeutet, dass sie als unbedenklich eingestuft wurden.
Open-Source-Pipeline ermöglicht Community-Erweiterungen
Neben dem Korpus veröffentlichen die Forschenden ihre Datenverarbeitungsbibliothek llmdata, um vollständige Reproduzierbarkeit zu gewährleisten. Die Pipeline ist speziell auf deutsche Texte zugeschnitten und kann von der Community erweitert werden.
German Commons ist über Hugging Face frei verfügbar und soll die Entwicklung rechtlich unbedenklicher deutscher Sprachmodelle ohne die Lizenzierungsprobleme web-basierter Korpora ermöglichen.
Vor kurzem hatte bereits das Common-Pile-Projekt einen wichtigen Schritt in Richtung rechtssicherer KI-Entwicklung unternommen. Das internationale Forschungsteam um die University of Toronto und EleutherAI veröffentlichte einen 8 TB großen, englischsprachigen Textdatensatz aus offen lizenzierten Quellen. Die darauf trainierten Comma-Modelle zeigten, dass explizit lizenzierte Daten durchaus konkurrenzfähige Sprachmodelle ermöglichen, allerdings mit Schwächen bei alltagsnahen Texten.
Davor hatte das deutsche OpenGPT-X-Projekt mit Teuken-7B gezeigt, wie europäische Mehrsprachigkeit in KI-Modellen umgesetzt werden kann. Das 7-Milliarden-Parameter-Modell wurde mit allen 24 EU-Amtssprachen trainiert, basierte jedoch auf konventionellen Trainingsdaten ohne explizite Lizenzprüfung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.