


ChatGPT Search hatte in den letzten sechs Monaten bis Ende März 2025 laut eigenen Angaben circa 41,3 Millionen monatliche Nutzer. Das sind rund viermal so viele wie im Zeitraum bis Ende 31. Oktober 2024 (11,2 Millionen), wie ein Screenshot der Seite aus dem Januar zeigt. Die Zahlen stammen aus einem Pflicht-Bericht im Rahmen des EU-Digital Services Act (DSA). Zum Vergleich: Die KI-Suchmaschine Perplexity lag 2024 weltweit bei circa 15 Millionen monatlich aktiven Nutzern und im Oktober 2024 bei circa 400 Millionen Suchanfragen pro Monat. In Relation zu Google ist das alles noch klein: Der Quasi-Monopolist kommt laut Schätzungen auf rund 8,5 Milliarden Suchanfragen - pro Tag. Google baut zudem seine KI-Suche weiter aus.



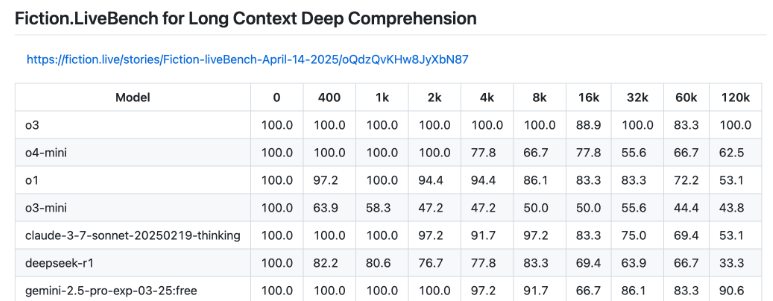
Der wohl interessanteste o3-Benchmark ist die Ausperformance bei der Verarbeitung langer Kontexte. Bei 128K Token (etwa 96.000 Wörter) von maximal 200K Token erreicht o3 im Fiction.live-Benchmark als erstes Modell 100 Prozent – das ist vielversprechend für KI-Anwendungen mit sehr langen Texten. Nur Googles Gemini 2.5 Pro kann mithalten und kommt auf 90,6 Prozent. o3-mini und o4-mini fallen deutlich ab. Fiction.LiveBench prüft, wie gut KI-Modelle komplexe Geschichten und Zusammenhänge bei sehr langen Texten komplett verstehen und korrekt wiedergeben. Ein Negativbeispiel ist Metas Llama 4, das zwar mit einem Kontextfenster von bis zu zehn Millionen Token wirbt, das aber über eine einfache Wortsuche hinaus kaum brauchbar ist.