Ein chinesisches Sprachmodell hängt OpenAIs GPT-3 und Googles PaLM ab. Huawei zeigt eine Codex-Alternative.
Große KI-Modelle für Text, Code und Bilddaten spielen eine zentrale Rolle in der Verbreitung Künstlicher Intelligenz in unseren Alltag. Forschende der Universität Stanford wollen solche Modelle daher sogar "Foundational Models" nennen.
Vorreiter der Entwicklung hin zu großen Modellen ist das amerikanische KI-Unternehmen OpenAI, dessen Sprachmodell GPT-3 die Nützlichkeit solcher KI-Systeme zuerst verdeutlichte.
Neben vielen unterschiedlichen Text-Aufgaben zeigte GPT-3 auch rudimentäre Code-Fähigkeiten. OpenAI nutzte daraufhin die enge Zusammenarbeit mit Microsoft, um mit Github-Daten das große Code-Modell Codex zu trainieren. Codex dient auch als Grundlage für Githubs CoPilot.
Chinas KI-Firmen entwickeln leistungsstarke Alternativen zu westlichen KI-Modellen
Mittlerweile ist die Liste großer Sprachmodelle westlicher Unternehmen und Institutionen lang: Neben GPT-3 gibt es etwa Googles PaLM, AI21 Labs Jurassic-1, Metas OPT-Modelle, BigScience BLOOM oder Aleph Alphas Luminous. Code-Modelle gibt es zudem etwa von Google, Amazon, Deepmind und Salesforce.
Diese Modelle sind jedoch primär mit westlichen Daten trainiert und eignen sich daher nicht für den Einsatz in China - sofern überhaupt ein Zugang möglich oder erlaubt ist.
Chinesische Unternehmen und Forschungsinstitutionen begannen daher spätestens mit der Vorstellung von GPT-3 mit der Produktion eigener Alternativen. 2021 zeigte etwa Huawei PanGu-Alpha, ein 200 Milliarden Parameter großes Sprachmodell, das mit 1,1, Terabyte chinesischsprachigen Daten trainiert wurde. Die Beijing Academy of Artificial Intelligence (BAAI) stellte im selben Jahr Wu Dao 2.0 vor, ein 1,75 Billionen Parameter großes multimodales Modell.
Sprachmodell GLM-130B hängt GPT-3 ab
Nun haben Forschende der chinesischen Tsinghua-Universität GLM-130B vorgestellt, ein bilinguales Sprachmodell, das laut Benchmarks des Teams Metas OPT, BLOOM und OpenAIs GPT-3 übertrifft. Die Few-Shot-Leistung des chinesisch- und englischsprachigen Modells übertraf das Niveau von bisherigem Spitzenmodell GPT-3 im Massive Multi-Task Language Understanding (MMLU)-Benchmark.
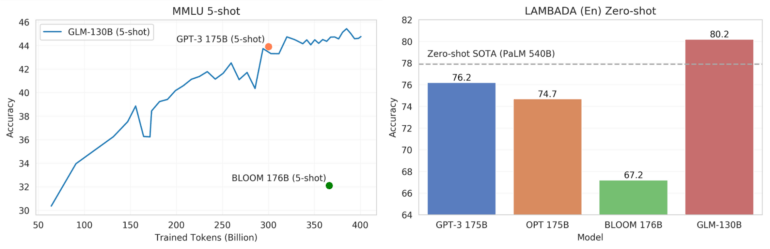
Das Team testete zudem GLM-130B mit LAMBADA, einem Zero-Shot-Benchmark zur Vorhersage des letzten Wortes einer Wortfolge. Der Benchmark wird zur Evaluierung der Sprachmodellierungsfähigkeiten großer Sprachmodelle eingesetzt. Hier hängte das chinesische Modell selbst bisherigen Spitzenreiter PaLM ab - trotz 410 Milliarden Parameter weniger.

Für das Training setzte das Team auf eine an der Tsinghua-Universität entwickelte Methode (GLM) mit 400 Nvidia A100 GPUs.
Damit übertrifft das erste Mal ein großes Sprachmodell aus China westliche Modelle. GLM-130B ist auf Github und HuggingFace verfügbar.
Code-Modell PanGu-Coder erreicht Leistung von Codex
Als konsequente Weiterentwicklung von PanGu zeigten Huaweis Noah’s Ark Lab und Huawei Cloud kürzlich zudem eine chinesische Alternative zu Copilot, Codex und anderen Code-Modellen. PanGu-Coder vervollständigt wie die westlichen Modelle Code und baut dabei auf die bei PanGu geleistete Vorarbeit auf. Der wesentliche Unterschied sind die Trainingsdaten: Code statt Text.
PanGu-Coder kommt in mehreren Modellen, die von 317 Millionen bis 2,6 Milliarden Parametern reichen. Laut Huawei liegen die chinesischen Modelle bei menschlichen Bewertungen auf dem Niveau von Codex, AlphaCode und Alternativen - und lassen sie in einigen Fällen hinter sich.
Das Unternehmen zeigt zudem eine mit einem kuratierten Datensatz trainierte Variante (PanGu-Coder-FT), die noch etwas besser abschneidet. PanGu-Coder kommt knapp ein Jahr nach der Veröffentlichung von OpenAIs Codex. Huawei folgt damit dem Muster von PanGu-Alpha, das ebenfalls knapp ein Jahr nach GPT-3 veröffentlicht wurde.