Google aktualisiert und erweitert Gemma Open Source KI-Modelle
Google hat seine Gemma-Familie um neue Modelle für Code-Vervollständigung und effizientere Inferenz erweitert. Außerdem wurden die Nutzungsbedingungen flexibler gestaltet.
Google hat heute die ersten Erweiterungen seiner im Februar vorgestellten Gemma-Familie angekündigt. Gemma umfasst leichtgewichtige State-of-the-Art Open-Source-Modelle, die auf derselben Technologie wie die Gemini-Modelle basieren.
Gemma für Code
CodeGemma für die Codegenerierung ist in drei Varianten verfügbar:
- Ein vortrainiertes 7B-Modell für Code-Vervollständigung und Code-Generierung
- Ein 7B-Modell mit Befehlsoptimierung für Code-Chat und Befehlsverfolgung
- Ein vortrainiertes 2B-Modell für schnelle lokale Code-Vervollständigung.

CodeGemma wurde mit 500 Milliarden Token aus Webdokumenten, Mathematik und Code trainiert. Es erzeugt syntaktisch korrekten und semantisch sinnvollen Code in Python, JavaScript, Java und anderen gängigen Sprachen. Ziel sei es, dass Entwickler weniger Standardcode schreiben und sich auf komplexere Aufgaben konzentrieren können, so Google.
Gemma für effizientere Inferenz
RecurrentGemma ist ein technisch eigenständiges Modell, das rekurrente neuronale Netze und lokale Aufmerksamkeit zur Verbesserung der Speichereffizienz nutzt. Bei ähnlicher Benchmark-Leistung wie Gemma 2B bietet RecurrentGemma laut Google mehrere Vorteile:
- Geringerer Speicherverbrauch für längere Samples auf Geräten mit begrenztem Speicher wie einzelnen GPUs oder CPUs
- Höherer Durchsatz durch Inferenz mit deutlich größeren Batch-Größen und mehr generierten Token pro Sekunde
- Fortschritte in der Deep-Learning-Forschung durch Nicht-Transformer-Modell mit hoher Leistung
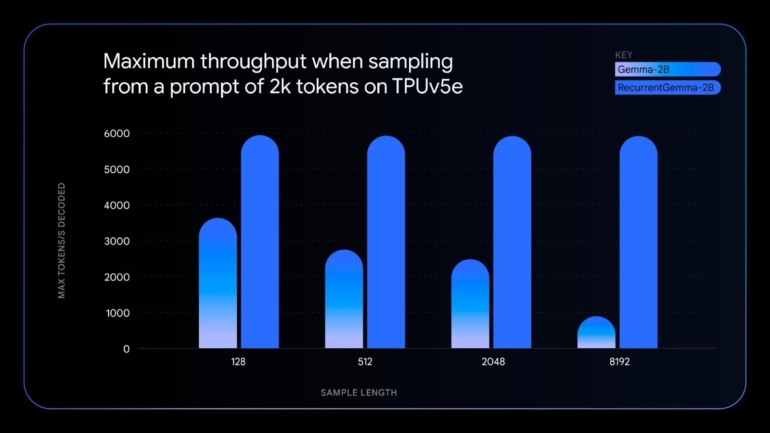
Zusätzlich zu den beiden neuen Modellen aktualisiert Google die Standard-Gemma-Modelle auf Version 1.1 und verspricht Leistungsverbesserungen, Bugfixes und flexiblere Nutzungsbedingungen.
Die neuen Modelle sind ab sofort auf Kaggle, Nvidia NIM APIs, Hugging Face und im Vertex AI Model Garden verfügbar. Sie können in verschiedene Werkzeuge und Plattformen integriert werden, darunter JAX, PyTorch, Hugging Face Transformers, Gemma.cpp, Keras, NVIDIA NeMo, TensorRT-LLM, Optimum-NVIDIA und MediaPipe.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.