Google DeepMind entwickelt Methode zur Selbstkorrektur von KI-Sprachmodellen

Forscher von Google DeepMind haben eine neue Technik namens SCoRe vorgestellt, die großen Sprachmodellen beibringen soll, ihre eigenen Fehler zu erkennen und zu verbessern.
Die Fähigkeit zur Selbstkorrektur ist bei aktuellen Large Language Models (LLMs) bisher nur unzureichend ausgeprägt, wie die Forscher von Google DeepMind feststellen. Bestehende Methoden erfordern oft mehrere Modelle oder externe Überprüfungen.
Die neue Technik "Self-Correction via Reinforcement Learning" (SCoRe) setzt dagegen auf Reinforcement Learning und trainiert ein einzelnes Modell ausschließlich mit selbst erzeugten Daten.
SCoRe arbeitet in zwei aufeinanderfolgenden Phasen, um LLMs Selbstkorrektur beizubringen. In der ersten Phase wird eine Modellinitialisierung darauf optimiert, Korrekturen im zweiten Versuch zu generieren, während die Verteilung der ersten Antworten möglichst nahe an der des Basismodells bleibt. Dies geschieht durch eine spezielle Verlustfunktion, die beide Aspekte berücksichtigt.
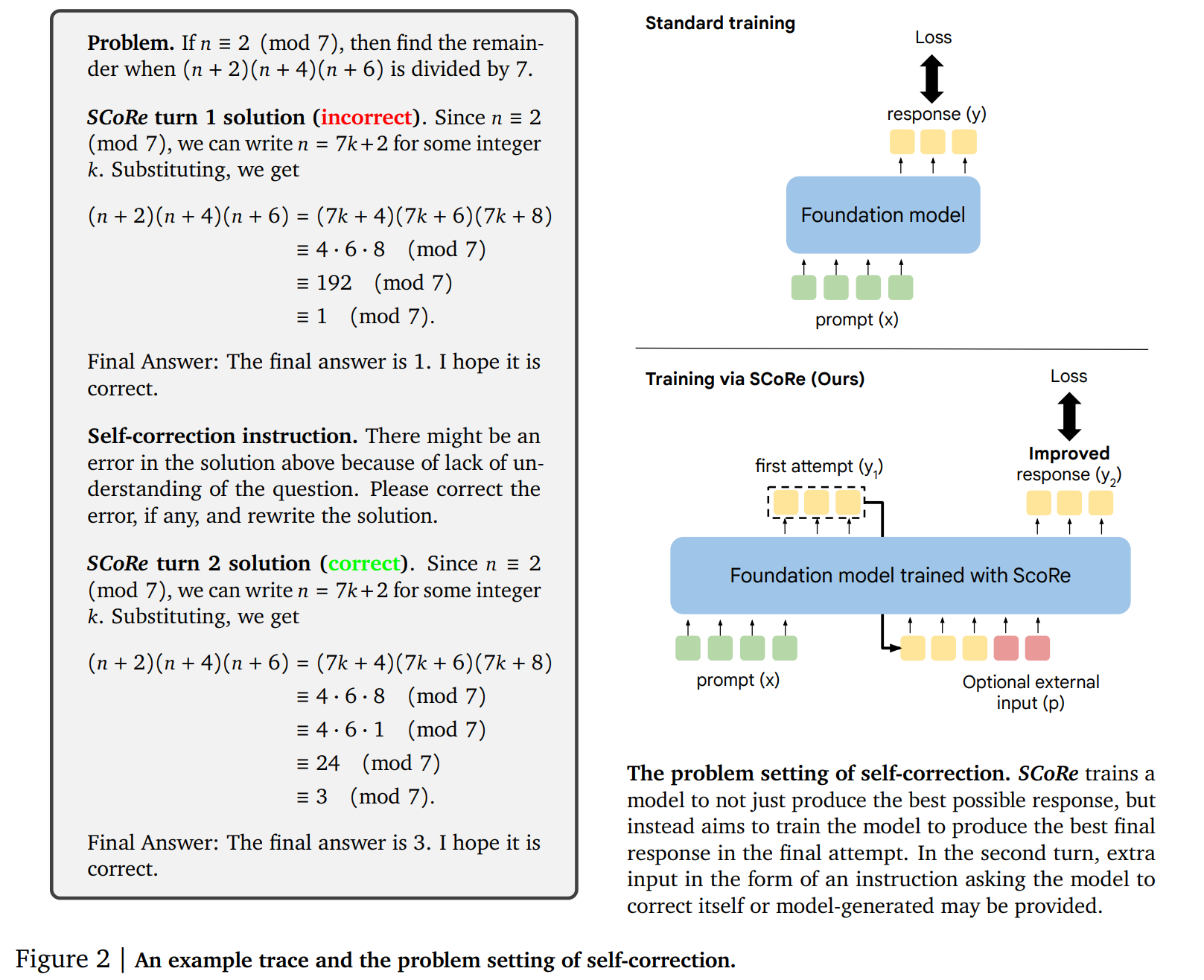
In der zweiten Phase wird dann mehrstufiges Reinforcement Learning angewendet. Hier lernt das Modell, sowohl die erste als auch die zweite Antwort zu optimieren. Eine besondere Belohnungsfunktion fördert dabei das Erlernen von Selbstkorrekturstrategien, indem sie Verbesserungen zwischen den Versuchen stärker belohnt. Wichtig ist, dass SCoRe ausschließlich mit selbst generierten Daten arbeitet. Das Modell erzeugt also seine eigenen Trainingsbeispiele, indem es Probleme löst und dann versucht, die Lösungen zu verbessern. Dies unterscheidet SCoRe von Ansätzen, die auf externe Überprüfung oder vorgegebene Korrekturdaten angewiesen sind.
SCoRe erreicht signifikante Selbstkorrektur
In Experimenten mit den Gemini 1.0 Pro und 1.5 Flash Modellen von Google erzielte SCoRe deutliche Verbesserungen. Auf dem MATH-Benchmark, der mathematisches Schlussfolgern testet, verbesserte sich die Selbstkorrekturrate um 15,6 Prozentpunkte. Beim HumanEval-Benchmark für Codegenerierung betrug die Verbesserung 9,1 Prozentpunkte.
Die Forscher betonen, dass SCoRe der erste Ansatz ist, der eine signifikant positive intrinsische Selbstkorrektur erreicht. Das bedeutet, dass das Modell seine Antworten verbessern kann, ohne externe Rückmeldungen zu erhalten.
Allerdings weisen die Forscher auch auf Einschränkungen hin. So wurde SCoRe bisher nur für eine Runde der Selbstkorrektur trainiert. Zukünftige Arbeiten könnten untersuchen, wie sich die Methode auf mehrere aufeinanderfolgende Korrekturschritte erweitern lässt.
Die Ergebnisse deuten laut dem Team jedoch insgesamt darauf hin, dass das Erlernen von Metastrategien wie Selbstkorrektur über die üblichen Trainingsparadigmen für LLMs hinausgehen muss. Mehrstufiges Reinforcement Learning könnte hier neue Möglichkeiten eröffnen, so die Schlussfolgerung der Autoren.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.