Google Deepmind zeigt Roboter mit verbessertem räumlichen Verständnis dank Smartphone-Video

Google Deepmind demonstriert, wie Roboter mit Hilfe des großen Kontextfensters von Gemini 1.5 Pro und multimodaler Eingaben in komplexen Umgebungen navigieren können.
Die Forscher nutzten die Fähigkeit von Gemini 1.5 Pro, bis zu einer Million multimodale Token zu verarbeiten, um Roboter durch unbekannte Umgebungen zu navigieren - allein durch menschliche Anweisungen, Videoanleitungen und LLM-Schlussfolgerungen.
In einem Experiment führten die Wissenschaftler die Roboter durch bestimmte Bereiche einer realen Umgebung und zeigten ihnen wichtige Orte wie "Lewis' Schreibtisch" oder den "temporären Schreibtischbereich". Anschließend konnten die Roboter zu diesen Orten zurückfinden.
Dieses "Demonstrationsvideo", das dem Roboter vorab einen Überblick über die Umgebung gibt, kann einfach mit einem Smartphone aufgenommen werden.
Video: Google Deepmind
Das sollte sogar mit kleinen Objekten funktionieren. Ein Nutzer könnte dem Roboter einfach ein Video seiner Wohnung zeigen und ihn dann per Smartphone fragen: "Wo habe ich meinen Untersetzer stehen lassen?" Der Roboter navigierte dann selbstständig dorthin.
Dank des integrierten Sprachmodells kann der Roboter auch abstrahieren. Fragt der Nutzer nach einem "Ort zum Zeichnen", kann der Roboter ein Whiteboard assoziieren und den Nutzer dorthin führen.
Video: Google Deepmind
In Zukunft könnte ein Roboter aus visuellen Informationen die Vorlieben eines Benutzers ableiten und entsprechend handeln, schreibt Google Deepmind. Hat ein Nutzer beispielsweise viele Getränkedosen eines bestimmten Herstellers auf seinem Schreibtisch stehen, könnte der Roboter bevorzugt dieses Getränk aus dem Kühlschrank holen und dem Nutzer bringen. Solche Fähigkeiten könnten die Mensch-Roboter-Interaktion erheblich verbessern, so Google Deepmind.
Die Systemarchitektur verarbeitet die multimodalen Eingaben und erstellt daraus einen topologischen Graphen - eine vereinfachte Darstellung des Raums. Dieser Graph wird aus den Einzelbildern der Videotouren konstruiert und erfasst die allgemeine Konnektivität der Umgebung, so dass der Roboter seinen Weg auch ohne Karte finden kann.
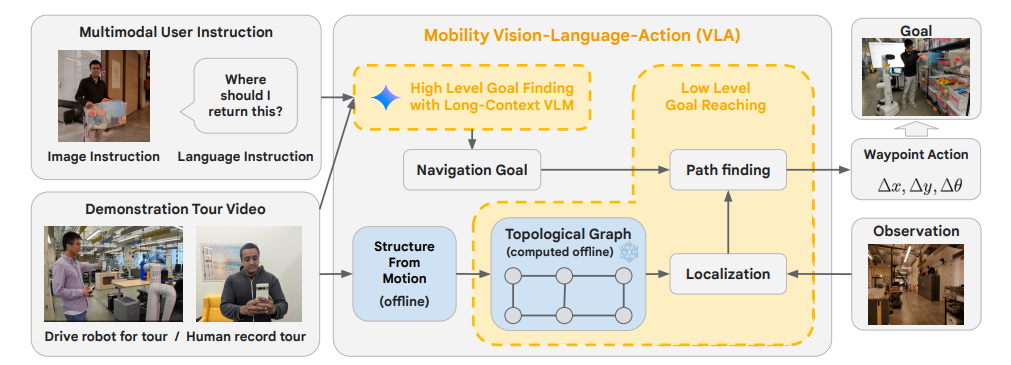
In weiteren Tests erhielten die Roboter zusätzliche multimodale Anweisungen wie Kartenskizzen auf einem Whiteboard, Audioanfragen mit Bezug auf Orte aus der Führung und visuelle Hinweise wie eine Spielzeugkiste. Mit diesen Eingaben konnten die Roboter verschiedene Aufgaben für unterschiedliche Personen ausführen.
In 57 Tests in einer realen Büroumgebung von 836 Quadratmetern erreichte Mobility VLA Erfolgsraten von bis zu 90 Prozent bei der Ausführung verschiedener multimodaler Navigationsaufgaben. Bei komplexen Instruktionen, die Schlussfolgerungen erfordern, erreichte es eine Erfolgsrate von 86 Prozent, verglichen mit 60 Prozent bei einem textbasierten System und 33 Prozent bei einem CLIP-basierten Ansatz.

Trotz der vielversprechenden Ergebnisse weisen die Forscher auf einige Einschränkungen hin. So benötigt das System derzeit 10 bis 30 Sekunden, um einen Befehl zu verarbeiten, was zu Verzögerungen bei der Interaktion führt. Außerdem ist es nicht in der Lage, die Umgebung selbstständig zu erkunden, sondern verlässt sich auf das vorgegebene Demonstrationsvideo.
Google Deepmind plant, Mobility VLA auf weitere Roboterplattformen auszuweiten und die Fähigkeiten des Systems über die reine Navigation hinaus zu erweitern. Vorläufige Tests deuten darauf hin, dass das System auch komplexere Aufgaben wie die Inspektion von Objekten und die Berichterstattung über die Ergebnisse übernehmen könnte.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.