Google Deepminds neues KI-Modell D4RT soll Robotern und AR-Brillen besseres räumliches Sehen ermöglichen
Kurz & Knapp
- Forscher von Google Deepmind haben mit D4RT ein KI-Modell entwickelt, das dynamische Szenen aus Videos in vier Dimensionen rekonstruiert.
- Es vereint dabei Tiefenschätzung, räumlich-zeitliche Korrespondenz und Kameraparameter in einem einzigen System und ist dadurch 18- bis 300-mal schneller als bisherige Methoden.
- Kurzfristig könnte die Technologie Robotern ein besseres räumliches Bewusstsein verleihen, langfristig einen Beitrag zu besseren Weltmodellen liefern.
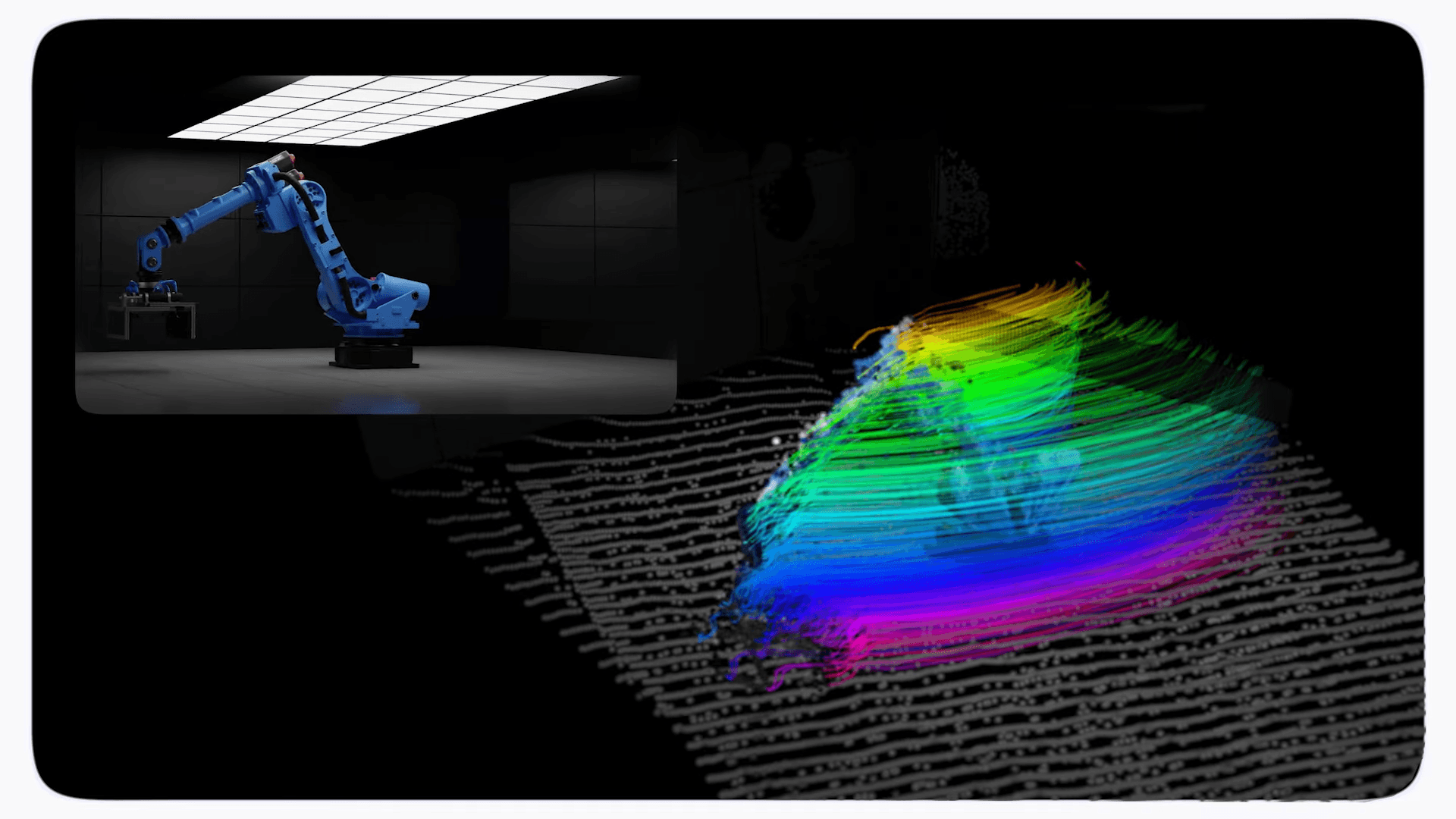
Google Deepminds neues KI-Modell D4RT soll dynamische Szenen aus Videos in vier Dimensionen rekonstruieren und dabei bisherige Methoden um ein Vielfaches übertreffen.
Während Menschen die Welt mühelos in drei Dimensionen wahrnehmen und verstehen, wie sich Objekte durch Raum und Zeit bewegen, ist diese Fähigkeit für KI-Systeme laut Google Deepmind bislang ein rechenintensiver Engpass.
Das neue Modell D4RT (Dynamic 4D Reconstruction and Tracking) soll dieses Problem mit einer neuartigen Architektur lösen, die Tiefenschätzung, räumlich-zeitliche Korrespondenz und Kameraparameter in einem einzigen System vereint.
Zwei Schritte statt vieler Modelle
Bisherige Ansätze zur 4D-Rekonstruktion setzen häufig auf mehrere spezialisierte Modelle, die separate Aufgaben wie Tiefenschätzung, Bewegungssegmentierung und Kameraposenschätzung übernehmen. Diese fragmentierten Systeme erfordern aufwendige Optimierungsschritte, um geometrische Konsistenz herzustellen.
D4RT verfolgt laut dem Forschungspapier einen anderen Ansatz, der auf dem Scene Representation Transformer aufbaut: Ein leistungsstarker Encoder verarbeitet die gesamte Videosequenz auf einmal und komprimiert sie in eine globale Szenenrepräsentation. Ein leichtgewichtiger Decoder fragt diese Repräsentation anschließend nur für die tatsächlich benötigten Punkte ab.
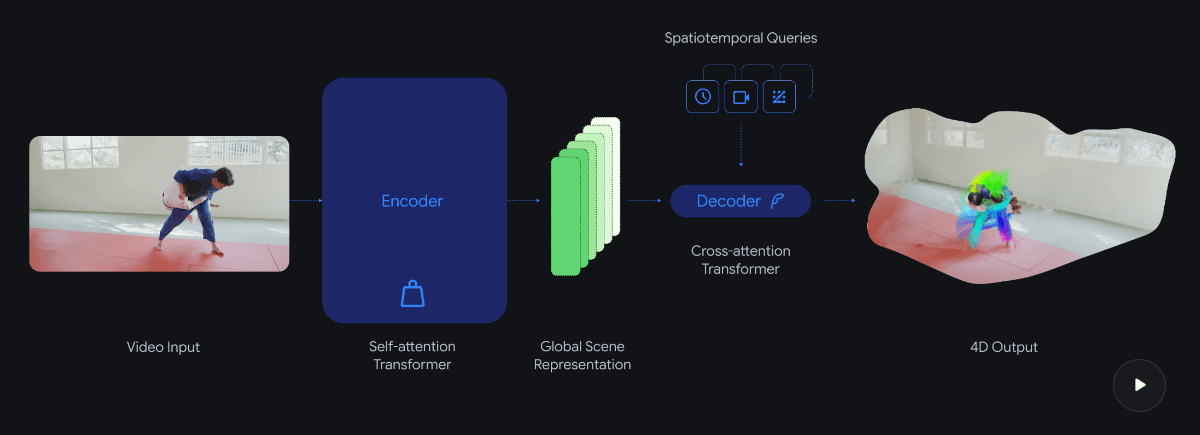
Der Mechanismus dreht sich um eine zentrale Frage: Wo befindet sich ein gegebenes Pixel aus dem Video im 3D-Raum zu einem beliebigen Zeitpunkt, betrachtet von einer gewählten Kamera? Da jede Abfrage unabhängig verarbeitet wird, lässt sie sich auf moderner KI-Hardware parallelisieren.
Anders als bei Konkurrenzmodellen, die separate Decoder für verschiedene Aufgaben benötigen, nutzt D4RT einen einzigen Decoder für Punkttracks, Punktwolken, Tiefenkarten und Kameraparameter. Das Modell kann dabei auch Vorhersagen für Objekte treffen, die in anderen Frames des Videos nicht sichtbar sind. Es funktioniert sowohl für statische Umgebungen als auch für dynamische Szenen mit bewegten Objekten.
18- bis 300-mal schneller als bisherige Methoden
Die Effizienzgewinne sind laut den Forschern erheblich: D4RT soll 18- bis 300-mal schneller arbeiten als vergleichbare Methoden. Ein einminütiges Video verarbeitet das Modell demnach in etwa fünf Sekunden auf einem einzelnen TPU-Chip, während bisherige Methoden bis zu zehn Minuten benötigten.
In den von Google Deepmind geteilten Benchmarks übertrifft D4RT bestehende Methoden bei Tiefenschätzung, Punktwolken-Rekonstruktion, Kameraposenschätzung und 3D-Punkt-Tracking. Bei der Kameraposenschätzung erreicht D4RT über 200 Bilder pro Sekunde, neunmal schneller als VGGT und hundertmal schneller als MegaSaM, und soll dabei noch akkurater sein.
Robotik und Augmented Reality als erste Anwendungsfelder
Kurzfristig könnte die Technologie laut Google Deepmind Robotern ein besseres räumliches Bewusstsein verleihen und Augmented-Reality-Anwendungen ermöglichen, virtuelle Objekte realistischer in die Umgebung einzubetten. Die Effizienz des Modells bringe einen Einsatz direkt auf dem Gerät in greifbare Nähe.
Langfristig sehen die Forscher den Ansatz als Beitrag zu besseren Weltmodellen, die sie als kritischen Schritt auf dem Weg zur künstlichen allgemeinen Intelligenz (AGI) bezeichnen. KI-Agenten sollen in diesen Weltmodellen aus Erfahrung lernen, anstatt nur, wie bei aktuellen KI-Modellen, antrainiertes Wissen weiterzugeben.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren