Google Gemini 2.5 kann Bildinhalte jetzt per natürlicher Sprache analysieren und markieren

Google hat eine neue Funktion für das KI-Modell Gemini 2.5 vorgestellt, die es ermöglicht, Bildinhalte direkt über natürliche Sprache zu analysieren und zu markieren.
Die sogenannte „conversational image segmentation“ geht über herkömmliche Bildsegmentierung hinaus, bei der Objekte meist anhand fester Kategorien wie „Hund“, „Auto“ oder „Stuhl“ erkannt wurden.
Stattdessen kann Gemini jetzt auch komplexe sprachliche Beschreibungen verstehen und auf einzelne Bildbereiche anwenden. Dazu gehören relationale Anfragen wie „die Person mit dem Regenschirm“, logisch konditionierte Aussagen wie „alle Personen, die nicht sitzen“, sowie abstrakte Begriffe wie „Unordnung“ oder „Schaden“, die keine klar definierte visuelle Form haben. Auch Bildinhalte, die sich nur über eingeblendeten Text eindeutig identifizieren lassen – etwa „die Pistazien-Baklava“ in einer Vitrine –, erkennt das Modell mithilfe integrierter Texterkennung. Schließlich unterstützt Gemini auch mehrsprachige Eingaben und liefert bei Bedarf Objektbeschriftungen in anderen Sprachen wie Französisch.
Praktische Einsatzzwecke
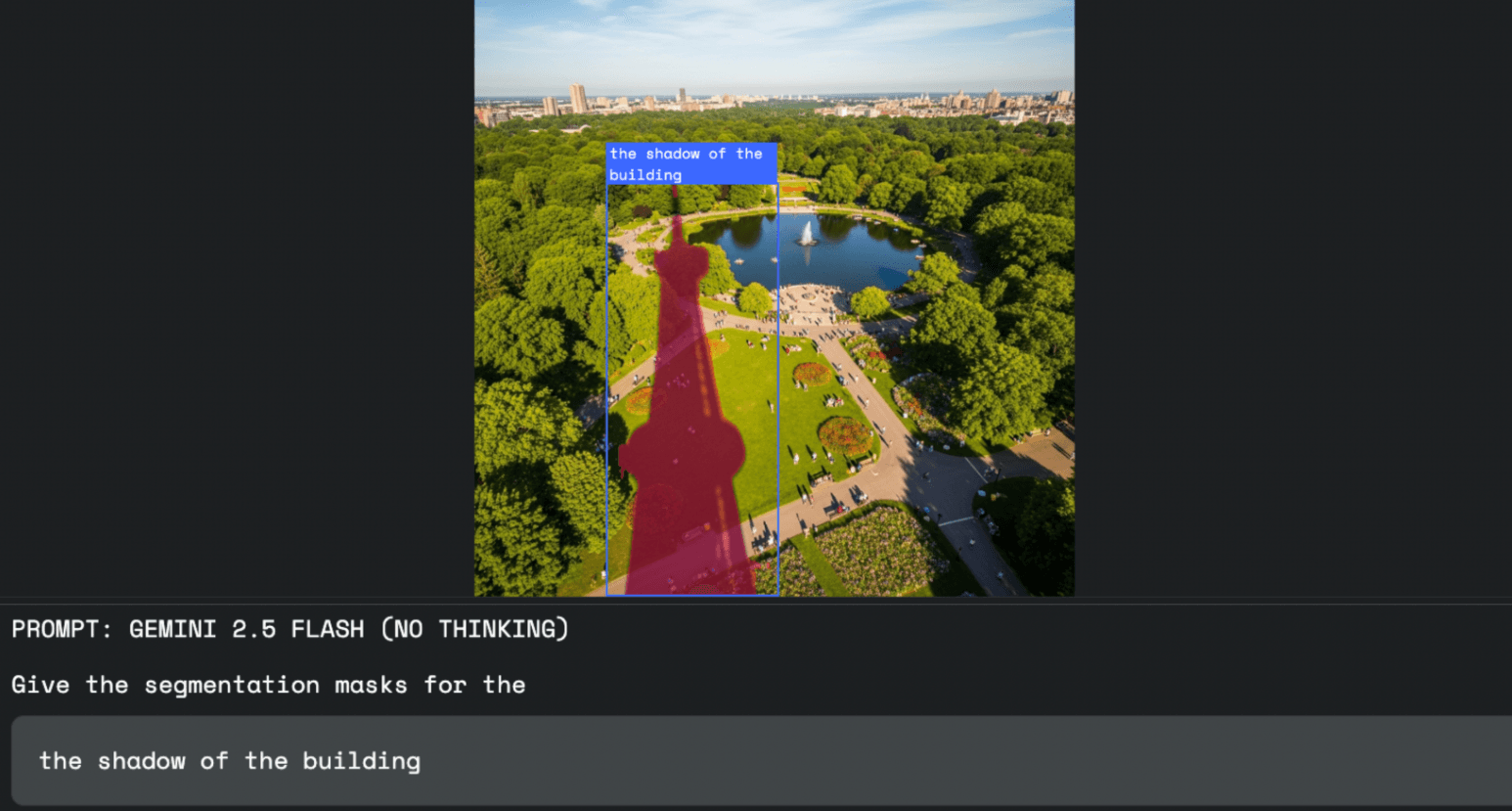
Die Technik lässt sich laut Google in verschiedenen Bereichen einsetzen. In der Bildbearbeitung etwa können Designer statt mit Maus und Auswahlwerkzeugen einfach per Sprache sagen, was sie bearbeiten möchten – zum Beispiel „den Schatten des Gebäudes auswählen“.
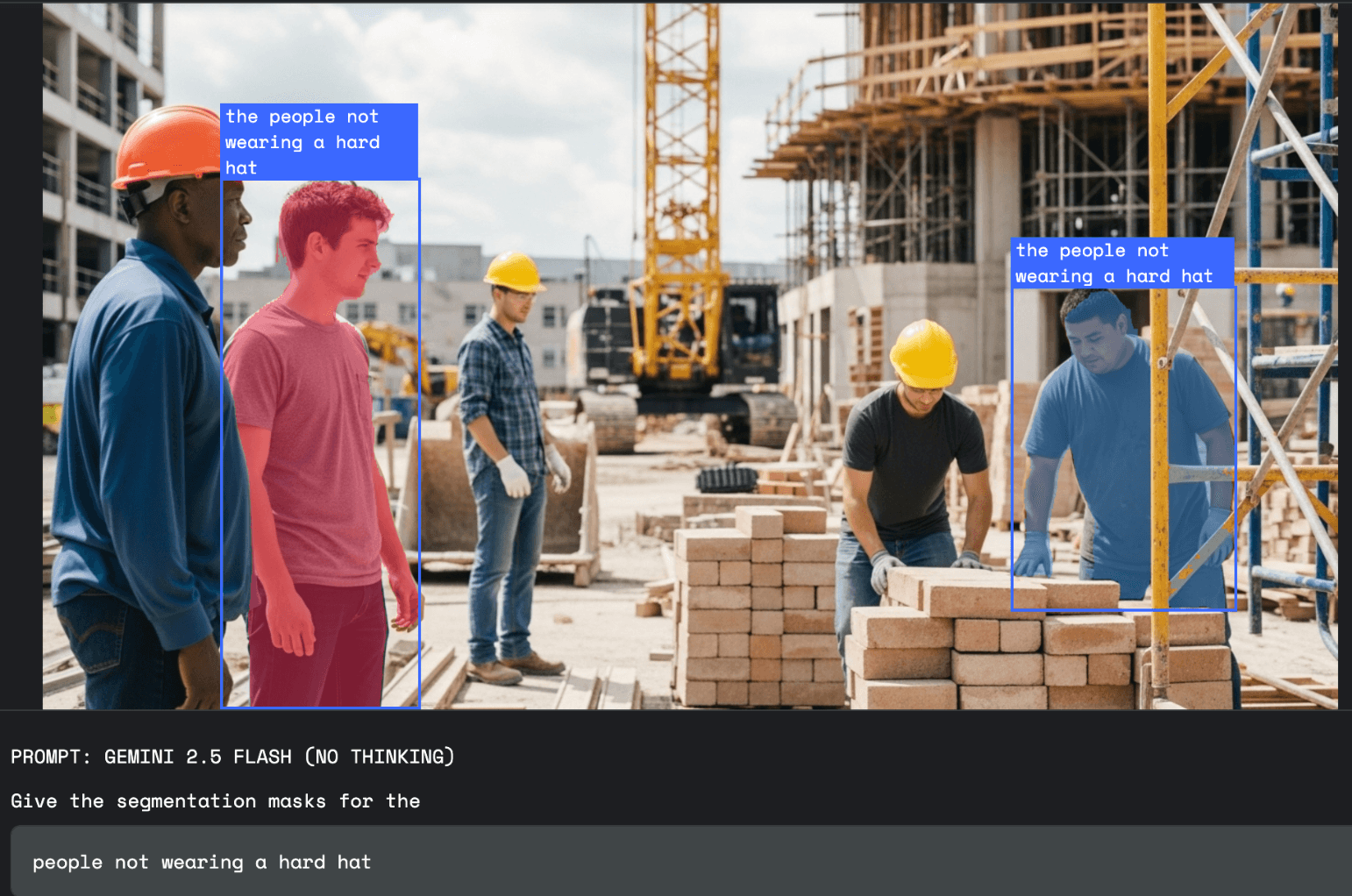
In der Arbeitssicherheit kann Gemini auf Bildern oder Videos gezielt nach Regelverstößen suchen, etwa „alle Personen auf der Baustelle ohne Helm“.
Auch im Versicherungswesen ist die Funktion nützlich: Ein:e Sachverständige:r kann mit einem Befehl wie „markiere alle Häuser mit Sturmschäden“ automatisch beschädigte Gebäude in Luftbildern hervorheben – ohne jedes Objekt manuell prüfen zu müssen.
Keine Spezialmodelle nötig
Für Entwickler:innen ist die Funktion über die Gemini API zugänglich. Die Anfragen laufen direkt über das Gemini-Modell, das mit dieser Fähigkeit ausgestattet ist.
Die Ausgaben erfolgen im JSON-Format und enthalten die Koordinaten des Bildausschnitts (box_2d), eine Pixelmaske (mask) und die beschreibende Bezeichnung (label).
Für die besten Ergebnisse empfiehlt Google die Verwendung des Modells gemini-2.5-flash. Außerdem soll der sogenannte „thinkingBudget“-Parameter auf null gesetzt werden, um eine direkte Antwort zu erzwingen.
Erste Tests sind über Google AI Studio oder Python Colab möglich.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.