Google rollt verbesserte Gemini 2.5 Flash und Flash-Lite KI-Modelle aus
Google veröffentlicht neue Vorschauversionen von Gemini 2.5 Flash und Flash-Lite. Die Modelle sollen effizienter arbeiten, besser mit Multimedia umgehen und übersetzen und komplexere Aufgaben erledigen.
Google hat neue Vorschauversionen seiner leichten KI-Modelle Gemini 2.5 Flash und Flash Lite veröffentlicht. Beide Modelle befinden sich weiterhin in der experimentellen Vorschauphase.
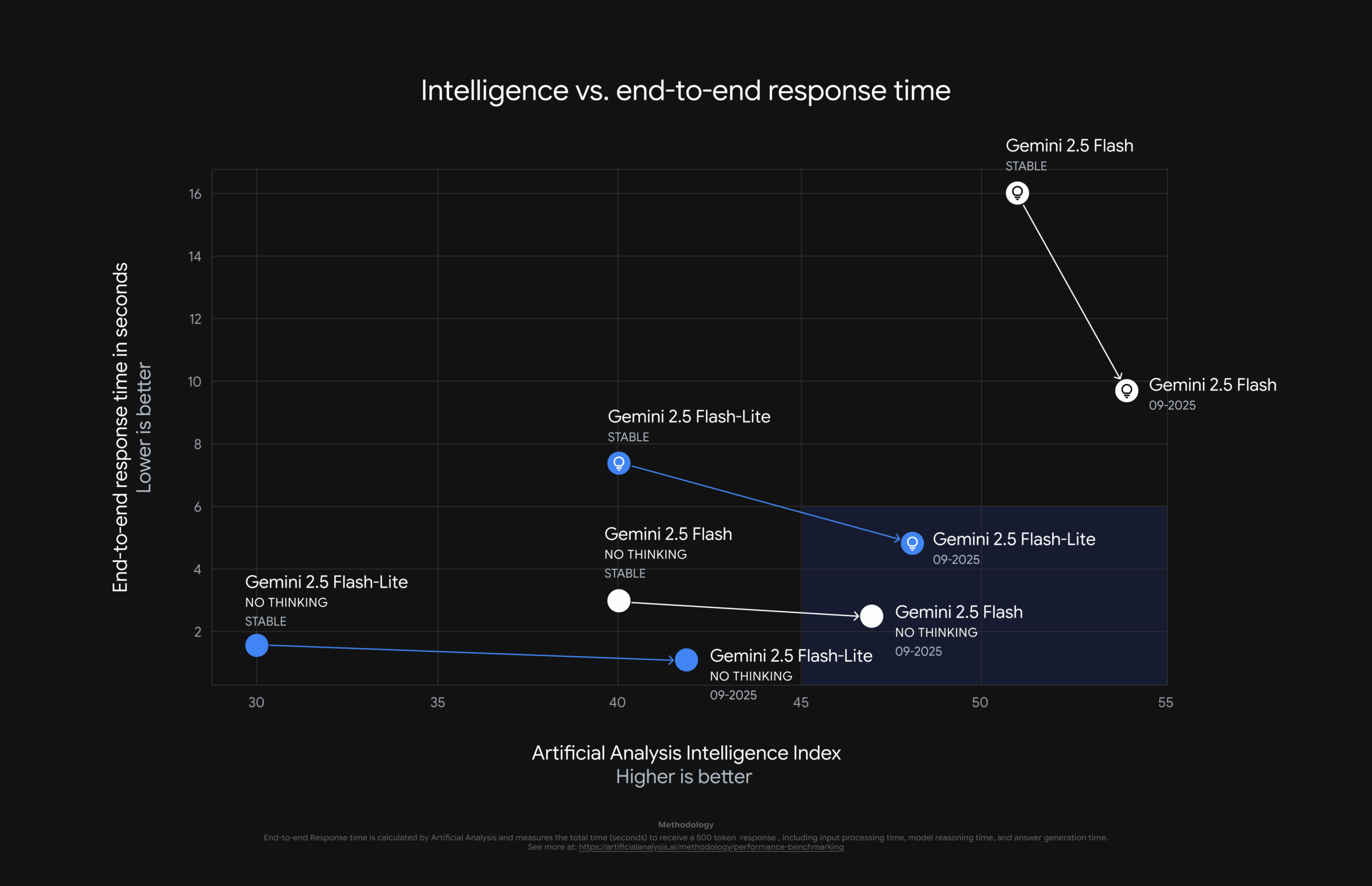
Im Artificial Analysis Index, der verschiedene Benchmarks zusammenfasst, erzielen sie eine bessere Leistung bei einer höheren Antwortgeschwindigkeit durch geringeren Tokenverbrauch. Die Preise bleiben unverändert, doch durch den geringeren Tokenverbrauch sinken die Kosten für den Einsatz.
Die neue Version von Gemini 2.5 Flash-Lite folgt komplexen Anweisungen und Systemprompts „signifikant“ zuverlässiger, produziert kürzere und präzisere Antworten, wodurch Token-Kosten und Latenz reduziert werden, und bietet darüber hinaus eine verbesserte Multimodalität mit präziserer Audiodaten-Transkription, robusterer Bildanalyse und höherer Übersetzungsqualität.
Auch das größere Gemini 2.5 Flash-Modell wurde überarbeitet. Es nutzt externe Tools in komplexen, mehrstufigen Aufgaben besser und zeigte laut Google eine Verbesserung von fünf Prozentpunkten auf dem SWE-Bench Verified Benchmark (von 48,9 auf 54 Prozent). Dieser Benchmark misst die Fähigkeit von KI-Modellen, realistische Softwareentwicklungsaufgaben zu lösen.
Zudem arbeitet das Modell nun effizienter: Mit aktivierter „Thinking“-Funktion erzeugt es qualitativ hochwertigere Ausgaben bei geringerer Token-Nutzung, das heißt, es antwortet schneller und günstiger.
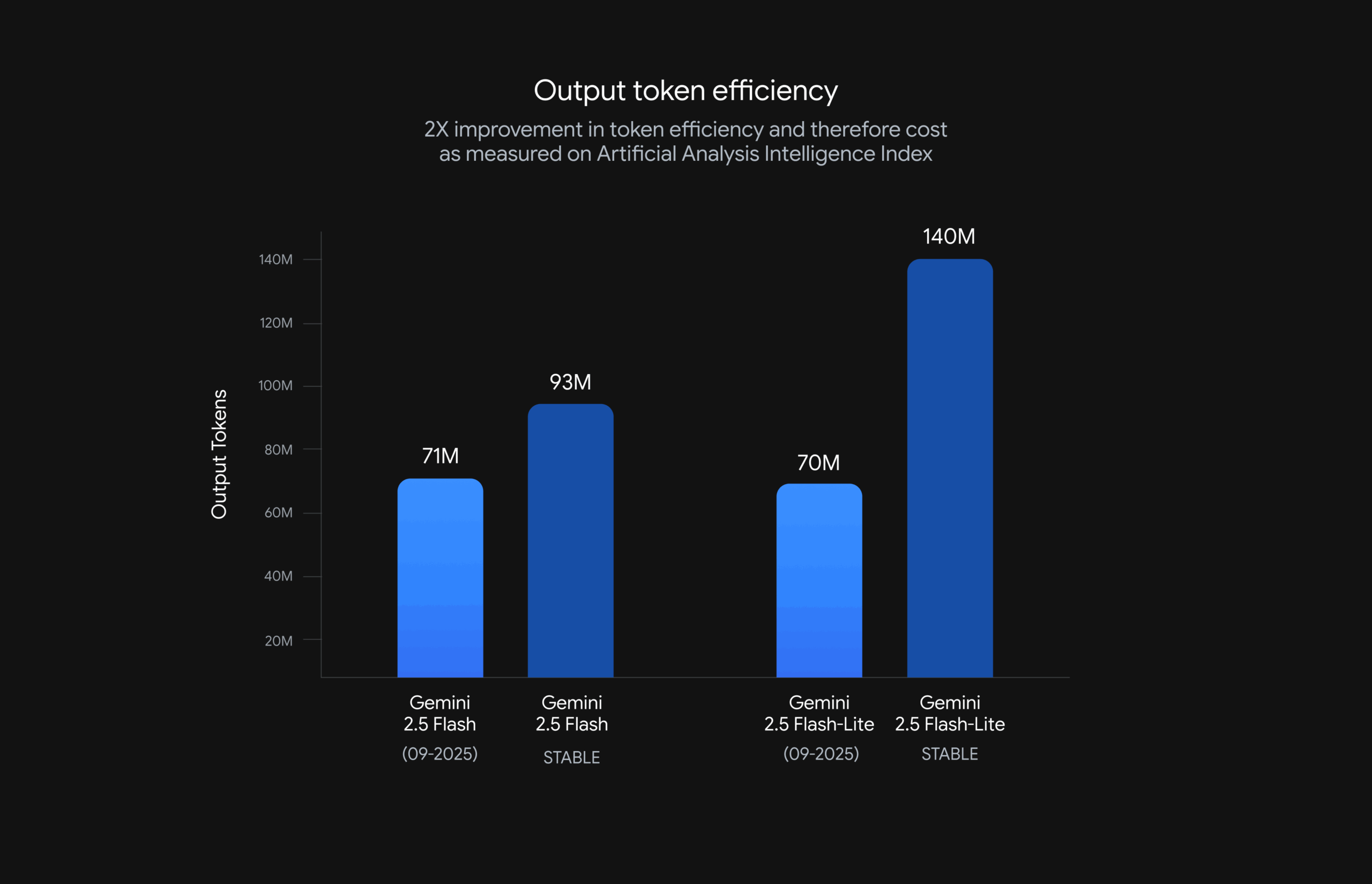
Gemini 2.5 Flash und Flash Lite nutzen
Die Modelle sind ab sofort in Google AI Studio und Vertex AI verfügbar. Das neue Lite-Modell kann über die Modellkennung gemini-2.5-flash-lite-preview-09-2025 getestet werden. Die Flash-Version kann über die Modellkennung gemini-2.5-flash-preview-09-2025 getestet werden.
Um die Nutzung der neuesten Modelle zu erleichtern, führt Google zudem ein Alias-System ein. Die neuen Bezeichner gemini-flash-latest und gemini-flash-lite-latest verweisen stets auf die aktuellste Version eines Modells. Damit entfällt die Notwendigkeit, Modellnamen bei jeder Aktualisierung manuell anzupassen.
Allerdings weist Google darauf hin, dass sich hinter diesen Aliases Funktionen, Preise und Ratenlimits je nach Version ändern können. Wer auf stabile Bedingungen angewiesen ist, soll weiterhin die fest benannten Modelle gemini-2.5-flash und gemini-2.5-flash-lite verwenden. Änderungen an den -latest-Verweisen werden mit einer Frist von zwei Wochen angekündigt.
| Modell | Eingabetoken (Text/Bild/Video) | Eingabetoken (Audio) | Ausgabetoken (inkl. "thinking tokens") |
|---|---|---|---|
| Gemini 2.5 Flash | $0,30 pro 1 Mio. | $1,00 pro 1 Mio. | $2,50 pro 1 Mio. |
| Gemini 2.5 Flash-Lite | $0,10 pro 1 Mio. | $0,30 pro 1 Mio. | $0,40 pro 1 Mio. |
Für die Batch-API fallen jeweils 50 Prozent der interaktiven Preise an. Quelle: offizielle Gemini API Preisliste
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.