Google spendiert seinem mächtigsten KI-Modell Gemini 2.5 Pro einen neuen "Denk"-Modus
Google erweitert seine Gemini-2.5-Modellreihe um einen experimentellen Modus für komplexe Schlussfolgerungen. Eine weitere Neuerung ist der native Audio-Output.
Google führt mit "Deep Think" einen neuen Modus für sein KI-Modell Gemini 2.5 Pro ein. Der erweiterte Denkmodus soll es dem Modell ermöglichen, mehrere Hypothesen zu erwägen, bevor es eine Antwort generiert. Laut Google basiert der Modus auf neuen Forschungstechniken und befindet sich derzeit in einer Testphase mit ausgewählten Nutzern der Gemini-API.
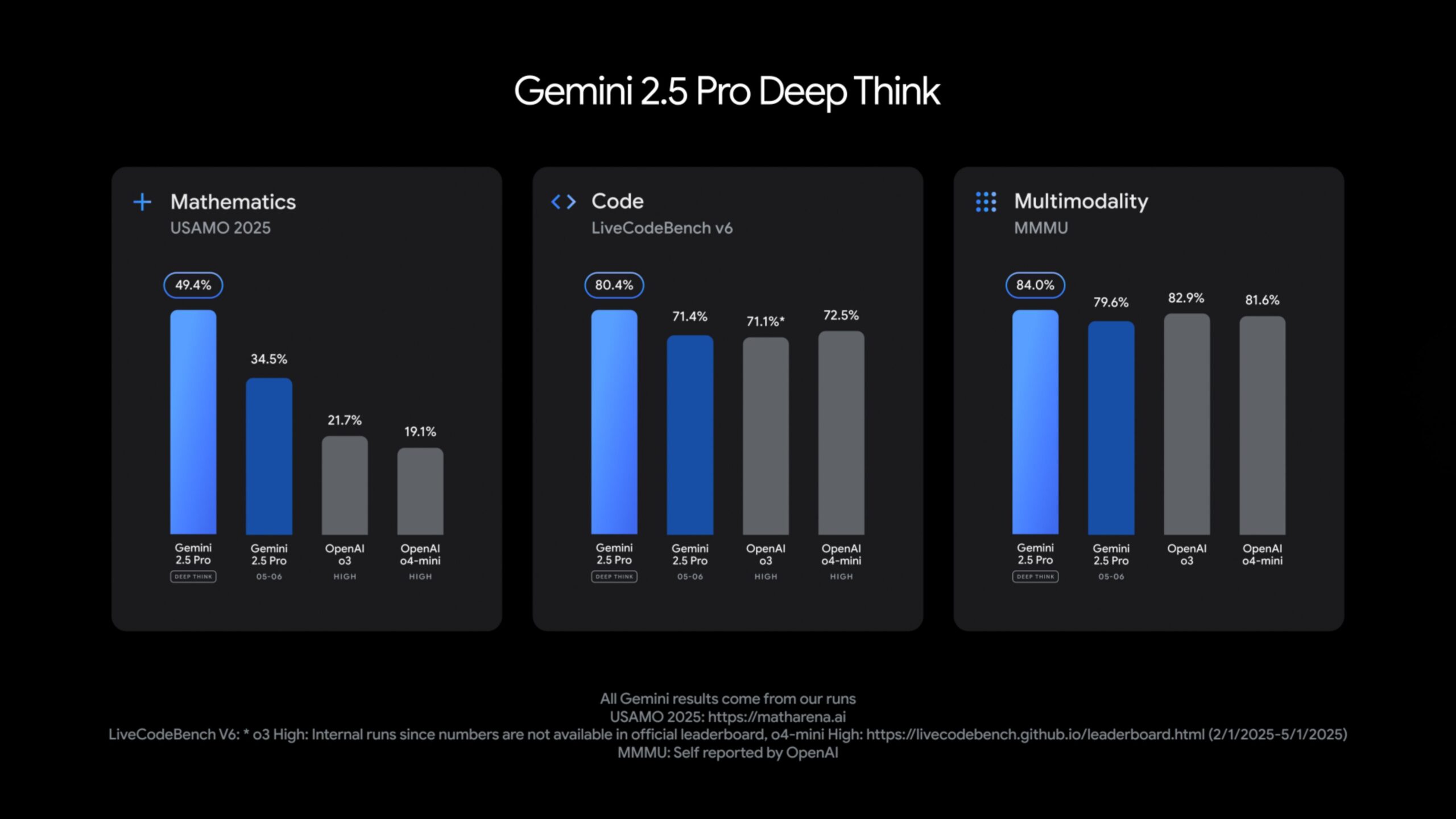
Gemini 2.5 Pro mit Deep Think erzielt laut Google Spitzenwerte in Benchmarks und übertrifft OpenAIs o3 im mathematischen USAMO-Test 2025, im Programmier-Benchmark LiveCodeBench sowie bei MMMU, einem Test für multimodales Schlussfolgern.
Das kürzlich vorgestellte Modell 2.5 Flash, das auf Geschwindigkeit und niedrige Kosten ausgelegt ist, wurde laut Google ebenfalls verbessert. Es erreicht nun bessere Werte in den Bereichen Schlussfolgern, Multimodalität, Codegenerierung und Verständnis langer Kontexte – bei gleichzeitig 20 bis 30 Prozent geringerem Token-Verbrauch.
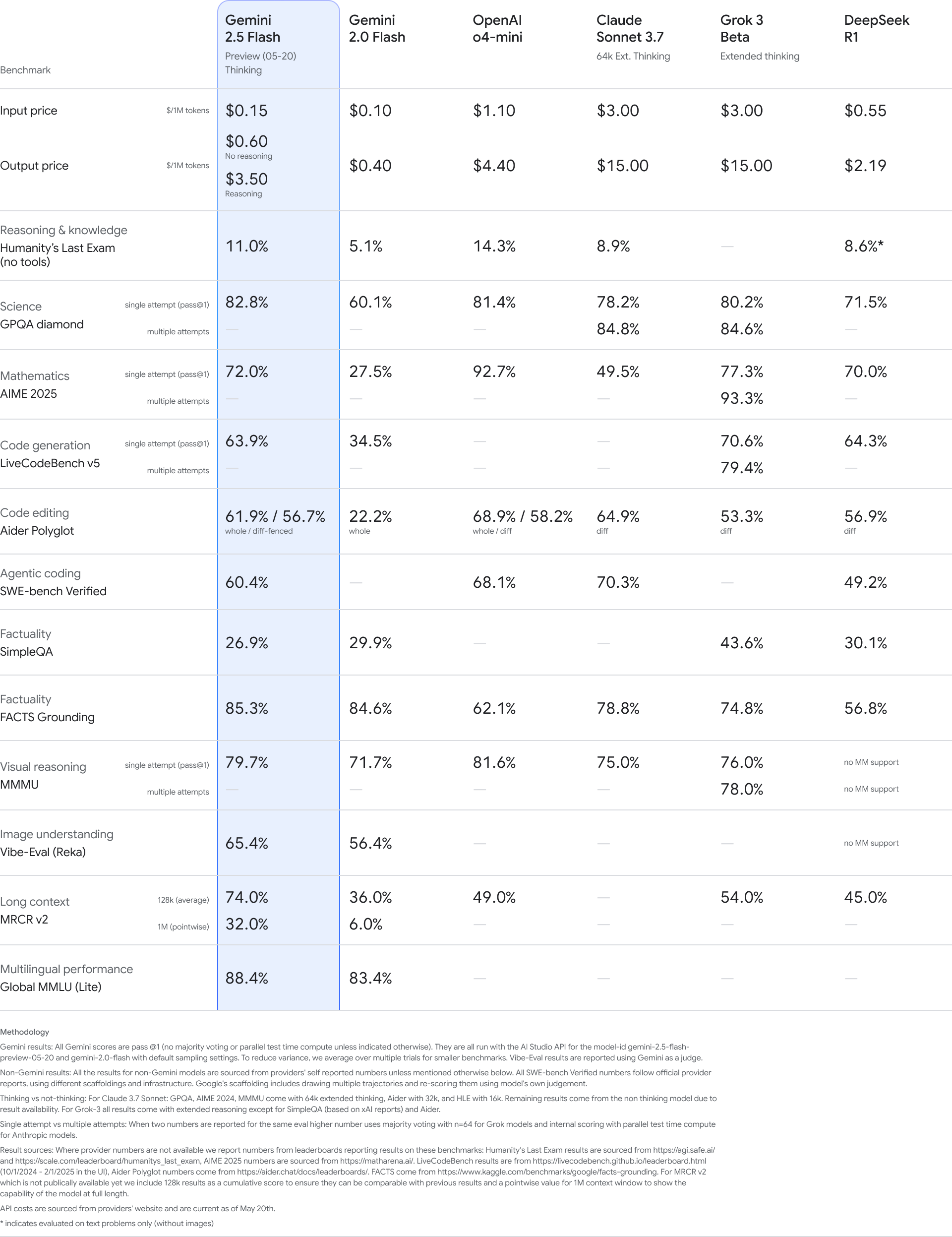
2.5 Flash steht ab sofort in Google AI Studio, Vertex AI und der Gemini-App zur Verfügung. Eine allgemeine Verfügbarkeit für Produktionsumgebungen ist für Anfang Juni geplant.
Expressive Audiofunktionen und Computersteuerung
Gemini 2.5 Pro und Flash unterstützen zudem native Audioausgabe mit mehreren Sprechern. Die Text-zu-Sprache-Funktion kann laut Google Flüstern und andere stimmliche Nuancen abbilden und zwischen über 24 Sprachen wechseln. In der Live API lassen sich Tonfall, Akzent und Stil steuern.
Die neuen Audiofunktionen "Affective Dialogue" und "Proactive Audio" in Googles Gemini-2.5-Modellen sollen Gespräche mit der KI natürlicher und intuitiver gestalten. "Affective Dialogue" ermöglicht es dem Modell, Emotionen in der Stimme des Nutzers zu erkennen und entsprechend zu reagieren – etwa empathisch, neutral oder fröhlich, je nach Tonfall.
"Proactive Audio" sorgt dafür, dass die KI Hintergrundgespräche ignoriert und nur dann antwortet, wenn sie direkt angesprochen wird. Damit sollen ungewollte Reaktionen vermieden und die Sprachinteraktion insgesamt verbessert werden.
Zusätzlich integriert Google die Möglichkeiten von Project Mariner in die Gemini API und Vertex AI. Damit kann das Modell Computeranwendungen wie den Browser bedienen.
Für Entwickler bietet Gemini nun Thought Summaries: Eine strukturierte Darstellung der Überlegungen des Modells inklusive ausgeführter Aktionen. Zudem können sogenannte Thinking Budgets gesetzt werden, um den Rechenaufwand und die Antwortqualität zu steuern. Die Anzahl der Denk-Tokens lässt sich festlegen oder ganz abschalten.
Schließlich unterstützt die Gemini API jetzt das Model Context Protocol (MCP) von Anthropic, was unter anderem die Integration mit Open-Source-Tools erleichtern soll. Google prüft zudem die Bereitstellung gehosteter MCP-Server zur Entwicklung agentischer Anwendungen.
Googles Open-Source-Modell wird multimodal
Ein weiterer Neuzugang in Googles KI-Portfolio ist das Modell Gemma 3n, das speziell für den Einsatz direkt auf mobilen Geräten wie Smartphones, Tablets und Laptops entwickelt wurde. Gemma 3n basiert auf einer neuen Architektur, die laut Google in Zusammenarbeit mit Hardwareherstellern wie Qualcomm, MediaTek und Samsung entwickelt wurde.
Es soll leistungsfähige, multimodale Funktionen bei gleichzeitig geringem Ressourcenverbrauch ermöglichen. Die Modelle mit 5 oder 8 Milliarden Parametern benötigen lediglich 2 bis 3 GB Arbeitsspeicher und sind damit auch für mobile Anwendungen geeignet.
Gemma 3n unterstützt Text-, Audio- und Bildverarbeitung, kann Sprache transkribieren und übersetzen und verarbeitet kombinierte Eingaben über mehrere Modalitäten hinweg. Zudem verfügt es über eine "Mix-n-Match"-Funktion, mit der je nach Anwendung kleinere Teilmodelle aus dem Hauptmodell erzeugt werden können.
Die multilingualen Fähigkeiten wurden insbesondere für Sprachen wie Deutsch, Japanisch, Koreanisch, Spanisch und Französisch verbessert. Google stellt eine Vorschauversion von Gemma 3n ab sofort über das Google AI Studio sowie das AI Edge-Toolkit für lokale Entwicklung bereit.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.