Google-Studie zeigt: KI-Benchmarks ignorieren menschliche Meinungsvielfalt

Kurz & Knapp
- Die gängige Praxis, nur drei bis fünf Bewerter pro Testbeispiel einzusetzen, reicht laut einer Studie von Google Research und dem Rochester Institute of Technology für zuverlässige KI-Benchmarks oft nicht aus. Nötig seien mindestens zehn.
- Schon rund 1.000 Annotationen können ausreichen, wenn das Budget richtig zwischen Testbeispielen und Bewertern aufgeteilt wird. Eine falsche Balance führt selbst bei höherem Budget zu unzuverlässigen Ergebnissen.
- Die optimale Aufteilung hängt von der Messmethode ab: Wer nur das Mehrheitsvotum prüft, benötigt viele Beispiele mit wenigen Bewertern. Wer die gesamte Meinungsvielfalt erfassen will, benötigt weniger Beispiele, dafür mehr Bewerter.
Wie viele Bewerter benötigt ein guter KI-Benchmark? Eine neue Studie zeigt, dass drei bis fünf Bewerter pro Testbeispiel häufig nicht ausreichen. Ebenso entscheidend ist die richtige Verteilung des Budgets.
Wenn KI-Modelle gegeneinander antreten, entscheiden oft menschliche Bewertungen darüber, welches besser abschneidet. Bewerter klassifizieren etwa, ob ein Kommentar toxisch ist oder ob eine Chatbot-Antwort sicher wirkt.
Bei solchen Aufgaben sind sich Menschen jedoch häufig uneinig. In der KI-Forschung ist es daher gängige Praxis, drei bis fünf Bewertungen pro Beispiel einzuholen und per Mehrheitsvotum eine einzige "richtige" Antwort festzulegen. Diese Meinungsvielfalt wird dabei systematisch ausgeblendet.
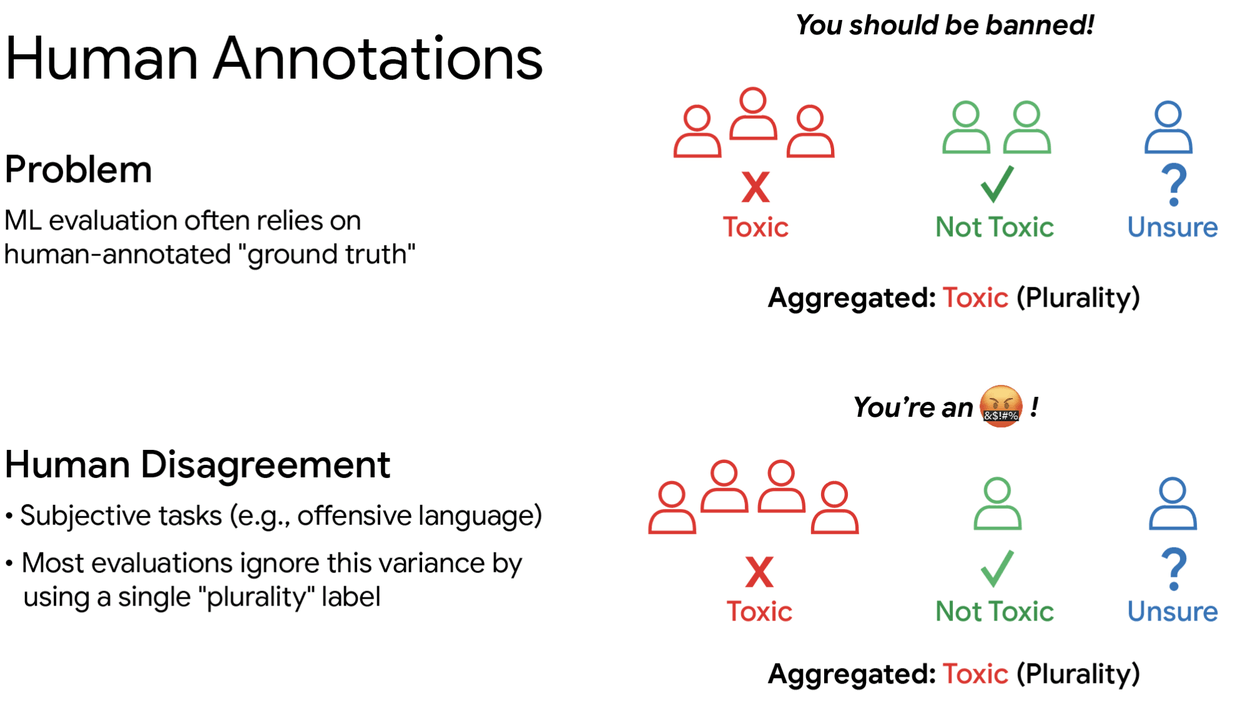
Forscher von Google Research und dem Rochester Institute of Technology haben nun untersucht, wie sich ein begrenztes Budget für menschliche Bewertungen besser einsetzen lässt. Die zentrale Frage: Sollte man möglichst viele verschiedene Testbeispiele bewerten lassen, oder lieber weniger Beispiele von deutlich mehr Menschen?
Die Forscher veranschaulichen das Dilemma mit einem Restaurantbesuch: Man kann 1.000 verschiedene Gäste bitten, jeweils ein Gericht zu probieren, und bekommt so einen groben Gesamteindruck. Oder man lässt 20 Personen dieselben 50 Gerichte bewerten und erfährt deutlich mehr über die Qualität jedes einzelnen Gerichts. Bisherige KI-Benchmarks setzten meist auf viele Testbeispiele, aber nur wenige Bewertungen pro Beispiel.
Tausende Konfigurationen im Stresstest
Um die optimale Verteilung zu ermitteln, entwickelte das Team einen Simulator, der menschliche Bewertungsmuster auf Basis realer Datensätze nachbildet. Der Simulator erzeugt synthetische Bewertungsdaten für zwei zu vergleichende Modelle, wobei eines kontrolliert schlechter abschneidet als das andere. Sokann getestet werdenn, unter welchen Bedingungen der Unterschied zwischen den Modellen statistisch zuverlässig erkannt wird.
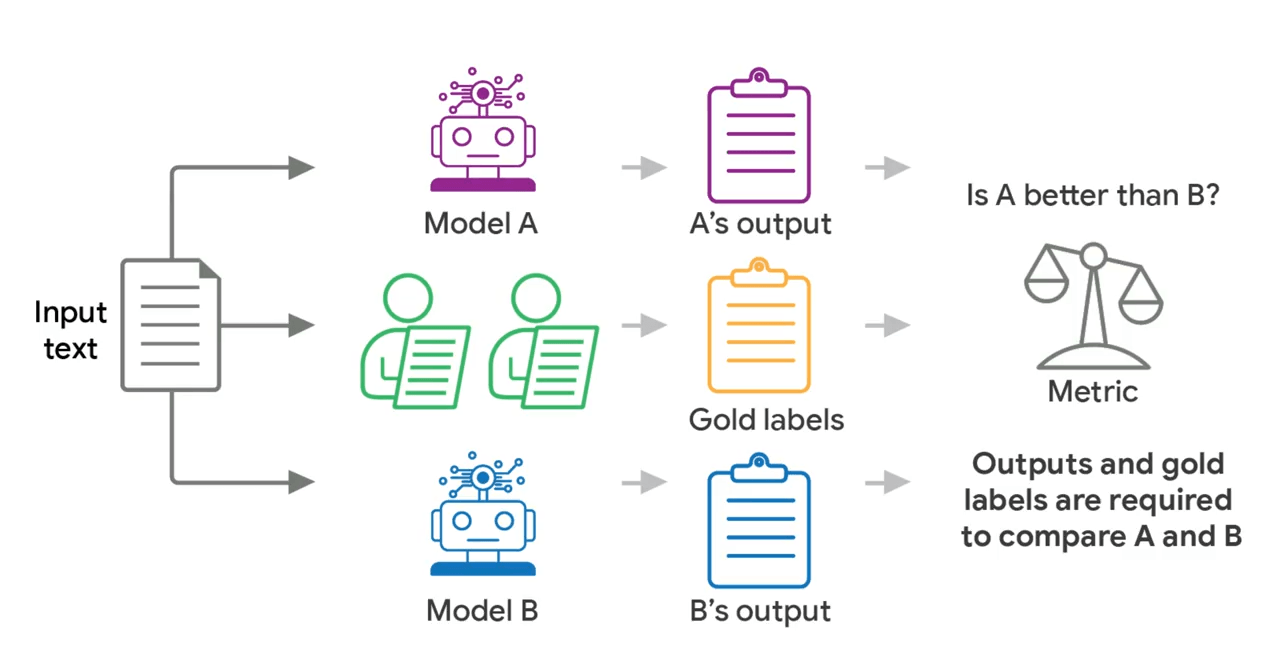
Angepasst wurde der Simulator an fünf reale Datensätze aus Bereichen wie Toxizitätserkennung, Chatbot-Sicherheit und interkultureller Offensiveness-Bewertung. Insgesamt testeten die Forscher tausende Kombinationen mit unterschiedlichen Gesamtbudgets und Bewerterzahlen pro Beispiel.
Mehr als zehn Bewerter pro Beispiel nötig
Das Ergebnis stellt die gängige Praxis infrage. Die übliche Anzahl von ein bis fünf Bewertern pro Testbeispiel reicht laut der Studie häufig nicht aus, um Modellvergleiche reproduzierbar zu machen. Für statistisch belastbare Ergebnisse, die menschliche Meinungsvielfalt abbilden, seien in der Regel mehr als zehn Bewerter pro Beispiel nötig.
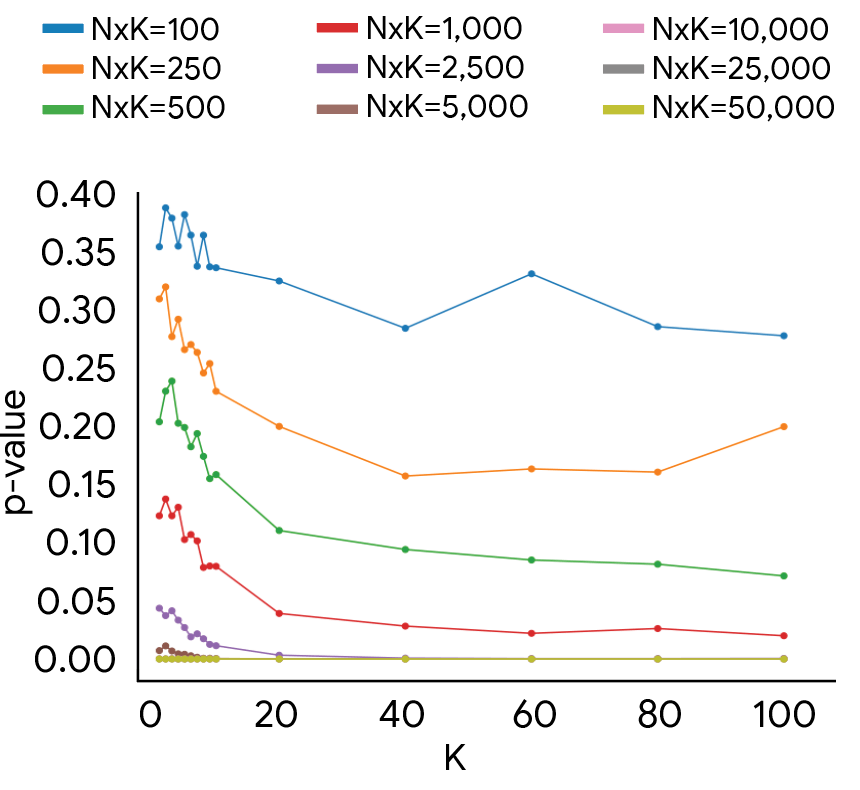
Gleichzeitig zeigen die Experimente, dass zuverlässige Ergebnisse oft schon mit rund 1.000 Annotationen erreichbar sind. Voraussetzung ist allerdings eine passende Verteilung zwischen Testbeispielen und Bewertern. Eine falsche Balance kann selbst bei deutlich höherem Budget zu unzuverlässigen Schlussfolgerungen führen.
Die Messmethode entscheidet über die Strategie
Die wichtigste Erkenntnis lautet, dass es kein universell optimales Verhältnis gibt. Die richtige Strategie hängt davon ab, was gemessen werden soll.
Wer Accuracy verwendet, prüft, ob ein Modell mit dem Mehrheitsvotum der Bewerter übereinstimmt. Dafür eignet sich ein Breite-Ansatz mit möglichst vielen Testbeispielen und wenigen Bewertern pro Beispiel. Accuracy berücksichtigt nur die häufigste Antwort. Zusätzliche Bewerter liefern kaum neue Informationen.
Wer dagegen die gesamte Verteilung menschlicher Antworten erfassen will, etwa mit der sogenannten Total Variation, benötigt den umgekehrten Ansatz. Dann sind weniger Testbeispiele sinnvoll, dafür deutlich mehr Bewerter pro Beispiel. Nur so kann abgebildet werden, wie stark die Zustimmung unter den Bewertern ausfällt.
Unterschiedliche Beispiele können zwar per Mehrheitsvotum dasselbe Label erhalten, aber verschiedene Antwortverteilungen haben. In den Experimenten benötigte diese verteilungssensitive Metrik zudem das kleinste Gesamtbudget.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren